 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Pyramid Adversarial Training for Improved ViT Performance
Dec 26, 2023



Recently, Pyramid Adversarial training (Herrmann et al., 2022) has been shown to be very effective for improving clean accuracy and distribution-shift robustness of vision transformers. However, due to the iterative nature of adversarial training, the technique is up to 7 times more expensive than standard training. To make the method more efficient, we propose Universal Pyramid Adversarial training, where we learn a single pyramid adversarial pattern shared across the whole dataset instead of the sample-wise patterns. With our proposed technique, we decrease the computational cost of Pyramid Adversarial training by up to 70% while retaining the majority of its benefit on clean performance and distribution-shift robustness. In addition, to the best of our knowledge, we are also the first to find that universal adversarial training can be leveraged to improve clean model performance.
NEFTune: Noisy Embeddings Improve Instruction Finetuning
Oct 10, 2023



We show that language model finetuning can be improved, sometimes dramatically, with a simple augmentation. NEFTune adds noise to the embedding vectors during training. Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Sep 04, 2023



As Large Language Models quickly become ubiquitous, it becomes critical to understand their security vulnerabilities. Recent work shows that text optimizers can produce jailbreaking prompts that bypass moderation and alignment. Drawing from the rich body of work on adversarial machine learning, we approach these attacks with three questions: What threat models are practically useful in this domain? How do baseline defense techniques perform in this new domain? How does LLM security differ from computer vision? We evaluate several baseline defense strategies against leading adversarial attacks on LLMs, discussing the various settings in which each is feasible and effective. Particularly, we look at three types of defenses: detection (perplexity based), input preprocessing (paraphrase and retokenization), and adversarial training. We discuss white-box and gray-box settings and discuss the robustness-performance trade-off for each of the defenses considered. We find that the weakness of existing discrete optimizers for text, combined with the relatively high costs of optimization, makes standard adaptive attacks more challenging for LLMs. Future research will be needed to uncover whether more powerful optimizers can be developed, or whether the strength of filtering and preprocessing defenses is greater in the LLMs domain than it has been in computer vision.
K-SAM: Sharpness-Aware Minimization at the Speed of SGD
Oct 23, 2022Sharpness-Aware Minimization (SAM) has recently emerged as a robust technique for improving the accuracy of deep neural networks. However, SAM incurs a high computational cost in practice, requiring up to twice as much computation as vanilla SGD. The computational challenge posed by SAM arises because each iteration requires both ascent and descent steps and thus double the gradient computations. To address this challenge, we propose to compute gradients in both stages of SAM on only the top-k samples with highest loss. K-SAM is simple and extremely easy-to-implement while providing significant generalization boosts over vanilla SGD at little to no additional cost.
Certified Neural Network Watermarks with Randomized Smoothing
Jul 16, 2022

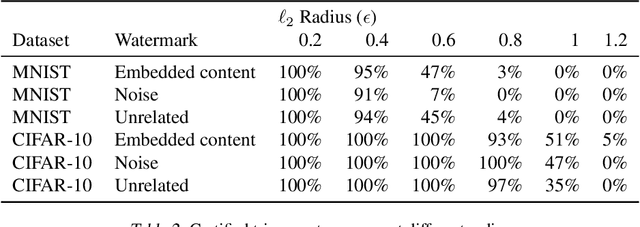

Watermarking is a commonly used strategy to protect creators' rights to digital images, videos and audio. Recently, watermarking methods have been extended to deep learning models -- in principle, the watermark should be preserved when an adversary tries to copy the model. However, in practice, watermarks can often be removed by an intelligent adversary. Several papers have proposed watermarking methods that claim to be empirically resistant to different types of removal attacks, but these new techniques often fail in the face of new or better-tuned adversaries. In this paper, we propose a certifiable watermarking method. Using the randomized smoothing technique proposed in Chiang et al., we show that our watermark is guaranteed to be unremovable unless the model parameters are changed by more than a certain l2 threshold. In addition to being certifiable, our watermark is also empirically more robust compared to previous watermarking methods. Our experiments can be reproduced with code at https://github.com/arpitbansal297/Certified_Watermarks
* ICML 2022
Adversarial Examples Make Strong Poisons
Jun 21, 2021

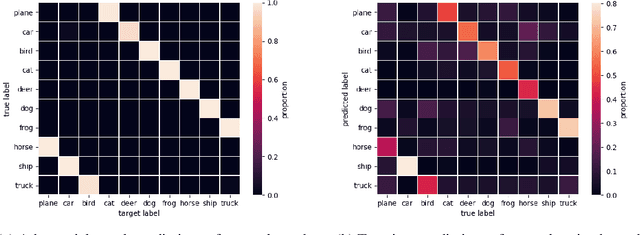

The adversarial machine learning literature is largely partitioned into evasion attacks on testing data and poisoning attacks on training data. In this work, we show that adversarial examples, originally intended for attacking pre-trained models, are even more effective for data poisoning than recent methods designed specifically for poisoning. Our findings indicate that adversarial examples, when assigned the original label of their natural base image, cannot be used to train a classifier for natural images. Furthermore, when adversarial examples are assigned their adversarial class label, they are useful for training. This suggests that adversarial examples contain useful semantic content, just with the ``wrong'' labels (according to a network, but not a human). Our method, adversarial poisoning, is substantially more effective than existing poisoning methods for secure dataset release, and we release a poisoned version of ImageNet, ImageNet-P, to encourage research into the strength of this form of data obfuscation.
Preventing Unauthorized Use of Proprietary Data: Poisoning for Secure Dataset Release
Mar 05, 2021



Large organizations such as social media companies continually release data, for example user images. At the same time, these organizations leverage their massive corpora of released data to train proprietary models that give them an edge over their competitors. These two behaviors can be in conflict as an organization wants to prevent competitors from using their own data to replicate the performance of their proprietary models. We solve this problem by developing a data poisoning method by which publicly released data can be minimally modified to prevent others from train-ing models on it. Moreover, our method can be used in an online fashion so that companies can protect their data in real time as they release it.We demonstrate the success of our approach onImageNet classification and on facial recognition.
ProportionNet: Balancing Fairness and Revenue for Auction Design with Deep Learning
Oct 13, 2020
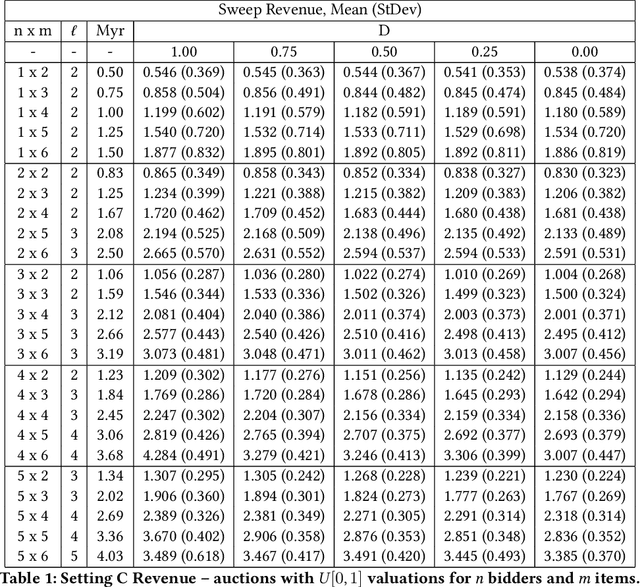
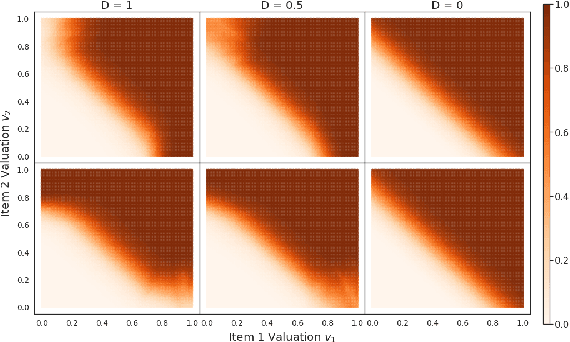
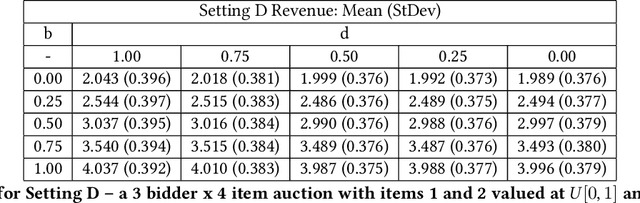
The design of revenue-maximizing auctions with strong incentive guarantees is a core concern of economic theory. Computational auctions enable online advertising, sourcing, spectrum allocation, and myriad financial markets. Analytic progress in this space is notoriously difficult; since Myerson's 1981 work characterizing single-item optimal auctions, there has been limited progress outside of restricted settings. A recent paper by D\"utting et al. circumvents analytic difficulties by applying deep learning techniques to, instead, approximate optimal auctions. In parallel, new research from Ilvento et al. and other groups has developed notions of fairness in the context of auction design. Inspired by these advances, in this paper, we extend techniques for approximating auctions using deep learning to address concerns of fairness while maintaining high revenue and strong incentive guarantees.
WrapNet: Neural Net Inference with Ultra-Low-Resolution Arithmetic
Jul 26, 2020

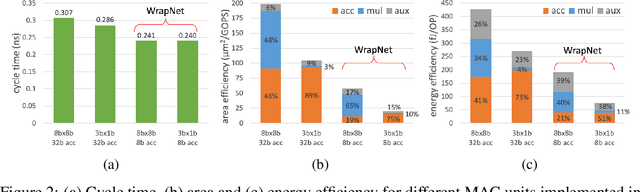
Low-resolution neural networks represent both weights and activations with few bits, drastically reducing the multiplication complexity. Nonetheless, these products are accumulated using high-resolution (typically 32-bit) additions, an operation that dominates the arithmetic complexity of inference when using extreme quantization (e.g., binary weights). To further optimize inference, we propose a method that adapts neural networks to use low-resolution (8-bit) additions in the accumulators, achieving classification accuracy comparable to their 32-bit counterparts. We achieve resilience to low-resolution accumulation by inserting a cyclic activation layer, as well as an overflow penalty regularizer. We demonstrate the efficacy of our approach on both software and hardware platforms.
Detection as Regression: Certified Object Detection by Median Smoothing
Jul 07, 2020
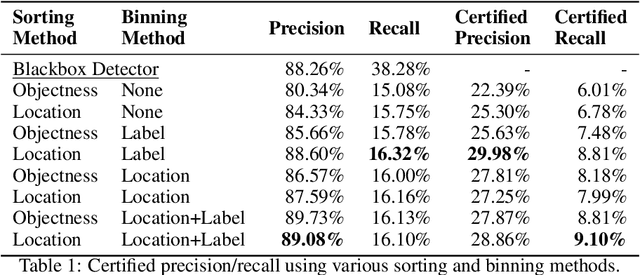

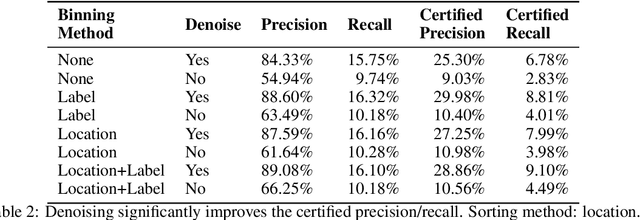
Despite the vulnerability of object detectors to adversarial attacks, very few defenses are known to date. While adversarial training can improve the empirical robustness of image classifiers, a direct extension to object detection is very expensive. This work is motivated by recent progress on certified classification by randomized smoothing. We start by presenting a reduction from object detection to a regression problem. Then, to enable certified regression, where standard mean smoothing fails, we propose median smoothing, which is of independent interest. We obtain the first model-agnostic, training-free, and certified defense for object detection against $\ell_2$-bounded attacks.