 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
Decomposition-Enhanced Training for Post-Hoc Attributions In Language Models
Oct 29, 2025Large language models (LLMs) are increasingly used for long-document question answering, where reliable attribution to sources is critical for trust. Existing post-hoc attribution methods work well for extractive QA but struggle in multi-hop, abstractive, and semi-extractive settings, where answers synthesize information across passages. To address these challenges, we argue that post-hoc attribution can be reframed as a reasoning problem, where answers are decomposed into constituent units, each tied to specific context. We first show that prompting models to generate such decompositions alongside attributions improves performance. Building on this, we introduce DecompTune, a post-training method that teaches models to produce answer decompositions as intermediate reasoning steps. We curate a diverse dataset of complex QA tasks, annotated with decompositions by a strong LLM, and post-train Qwen-2.5 (7B and 14B) using a two-stage SFT + GRPO pipeline with task-specific curated rewards. Across extensive experiments and ablations, DecompTune substantially improves attribution quality, outperforming prior methods and matching or exceeding state-of-the-art frontier models.
A Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
Jul 09, 2025

Despite the significant progress that has been made in video generative models, existing state-of-the-art methods can only produce videos lasting 5-16 seconds, often labeled "long-form videos". Furthermore, videos exceeding 16 seconds struggle to maintain consistent character appearances and scene layouts throughout the narrative. In particular, multi-subject long videos still fail to preserve character consistency and motion coherence. While some methods can generate videos up to 150 seconds long, they often suffer from frame redundancy and low temporal diversity. Recent work has attempted to produce long-form videos featuring multiple characters, narrative coherence, and high-fidelity detail. We comprehensively studied 32 papers on video generation to identify key architectural components and training strategies that consistently yield these qualities. We also construct a comprehensive novel taxonomy of existing methods and present comparative tables that categorize papers by their architectural designs and performance characteristics.
A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models
Feb 22, 2025



The rise of foundation models has transformed machine learning research, prompting efforts to uncover their inner workings and develop more efficient and reliable applications for better control. While significant progress has been made in interpreting Large Language Models (LLMs), multimodal foundation models (MMFMs) - such as contrastive vision-language models, generative vision-language models, and text-to-image models - pose unique interpretability challenges beyond unimodal frameworks. Despite initial studies, a substantial gap remains between the interpretability of LLMs and MMFMs. This survey explores two key aspects: (1) the adaptation of LLM interpretability methods to multimodal models and (2) understanding the mechanistic differences between unimodal language models and crossmodal systems. By systematically reviewing current MMFM analysis techniques, we propose a structured taxonomy of interpretability methods, compare insights across unimodal and multimodal architectures, and highlight critical research gaps.
On Mechanistic Circuits for Extractive Question-Answering
Feb 12, 2025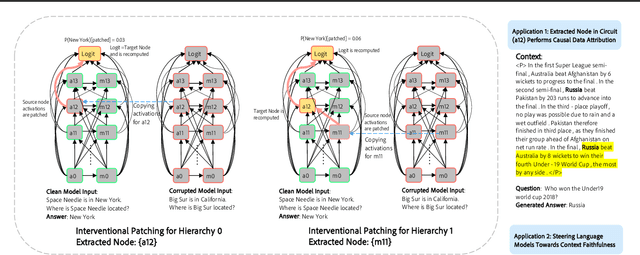
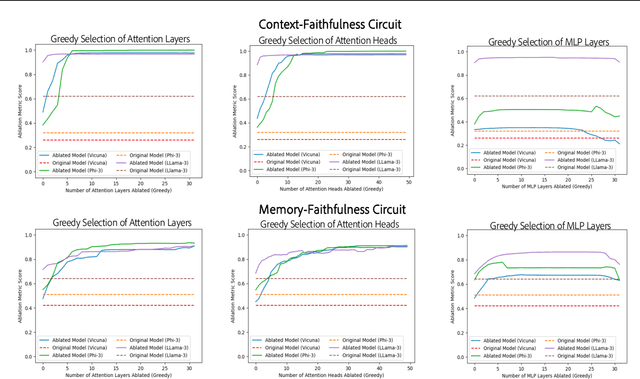
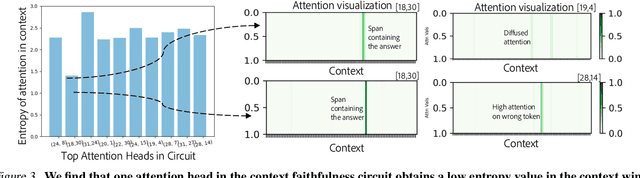
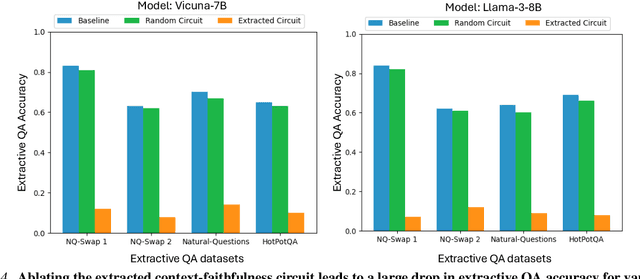
Large language models are increasingly used to process documents and facilitate question-answering on them. In our paper, we extract mechanistic circuits for this real-world language modeling task: context-augmented language modeling for extractive question-answering (QA) tasks and understand the potential benefits of circuits towards downstream applications such as data attribution to context information. We extract circuits as a function of internal model components (e.g., attention heads, MLPs) using causal mediation analysis techniques. Leveraging the extracted circuits, we first understand the interplay between the model's usage of parametric memory and retrieved context towards a better mechanistic understanding of context-augmented language models. We then identify a small set of attention heads in our circuit which performs reliable data attribution by default, thereby obtaining attribution for free in just the model's forward pass. Using this insight, we then introduce ATTNATTRIB, a fast data attribution algorithm which obtains state-of-the-art attribution results across various extractive QA benchmarks. Finally, we show the possibility to steer the language model towards answering from the context, instead of the parametric memory by using the attribution from ATTNATTRIB as an additional signal during the forward pass. Beyond mechanistic understanding, our paper provides tangible applications of circuits in the form of reliable data attribution and model steering.
Persona-SQ: A Personalized Suggested Question Generation Framework For Real-world Documents
Dec 17, 2024



Suggested questions (SQs) provide an effective initial interface for users to engage with their documents in AI-powered reading applications. In practical reading sessions, users have diverse backgrounds and reading goals, yet current SQ features typically ignore such user information, resulting in homogeneous or ineffective questions. We introduce a pipeline that generates personalized SQs by incorporating reader profiles (professions and reading goals) and demonstrate its utility in two ways: 1) as an improved SQ generation pipeline that produces higher quality and more diverse questions compared to current baselines, and 2) as a data generator to fine-tune extremely small models that perform competitively with much larger models on SQ generation. Our approach can not only serve as a drop-in replacement in current SQ systems to immediately improve their performance but also help develop on-device SQ models that can run locally to deliver fast and private SQ experience.
On Mechanistic Knowledge Localization in Text-to-Image Generative Models
May 02, 2024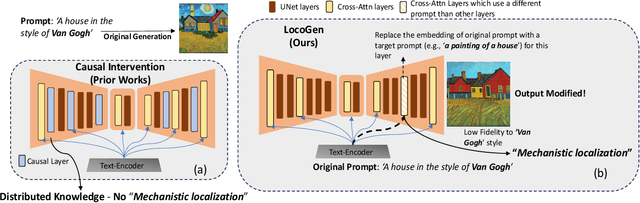
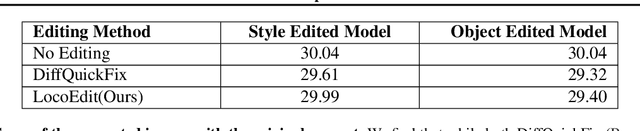
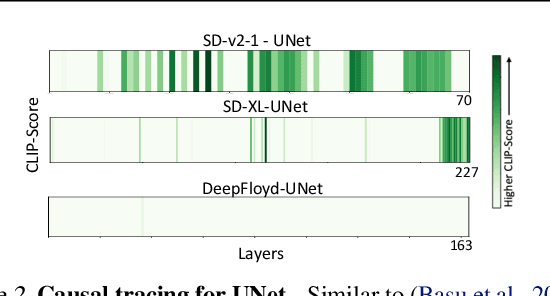
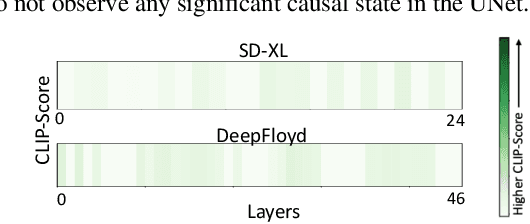
Identifying layers within text-to-image models which control visual attributes can facilitate efficient model editing through closed-form updates. Recent work, leveraging causal tracing show that early Stable-Diffusion variants confine knowledge primarily to the first layer of the CLIP text-encoder, while it diffuses throughout the UNet.Extending this framework, we observe that for recent models (e.g., SD-XL, DeepFloyd), causal tracing fails in pinpointing localized knowledge, highlighting challenges in model editing. To address this issue, we introduce the concept of Mechanistic Localization in text-to-image models, where knowledge about various visual attributes (e.g., ``style", ``objects", ``facts") can be mechanistically localized to a small fraction of layers in the UNet, thus facilitating efficient model editing. We localize knowledge using our method LocoGen which measures the direct effect of intermediate layers to output generation by performing interventions in the cross-attention layers of the UNet. We then employ LocoEdit, a fast closed-form editing method across popular open-source text-to-image models (including the latest SD-XL)and explore the possibilities of neuron-level model editing. Using Mechanistic Localization, our work offers a better view of successes and failures in localization-based text-to-image model editing. Code will be available at \href{https://github.com/samyadeepbasu/LocoGen}{https://github.com/samyadeepbasu/LocoGen}.
FABLES: Evaluating faithfulness and content selection in book-length summarization
Apr 01, 2024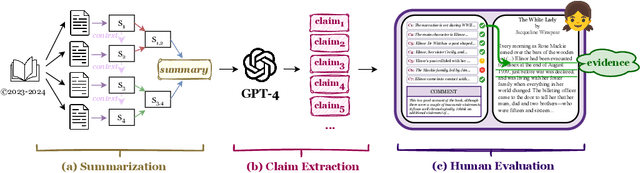
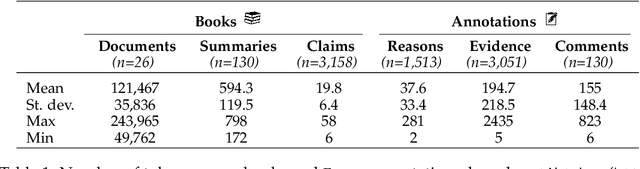


While long-context large language models (LLMs) can technically summarize book-length documents (>100K tokens), the length and complexity of the documents have so far prohibited evaluations of input-dependent aspects like faithfulness. In this paper, we conduct the first large-scale human evaluation of faithfulness and content selection on LLM-generated summaries of fictional books. Our study mitigates the issue of data contamination by focusing on summaries of books published in 2023 or 2024, and we hire annotators who have fully read each book prior to the annotation task to minimize cost and cognitive burden. We collect FABLES, a dataset of annotations on 3,158 claims made in LLM-generated summaries of 26 books, at a cost of $5.2K USD, which allows us to rank LLM summarizers based on faithfulness: Claude-3-Opus significantly outperforms all closed-source LLMs, while the open-source Mixtral is on par with GPT-3.5-Turbo. An analysis of the annotations reveals that most unfaithful claims relate to events and character states, and they generally require indirect reasoning over the narrative to invalidate. While LLM-based auto-raters have proven reliable for factuality and coherence in other settings, we implement several LLM raters of faithfulness and find that none correlates strongly with human annotations, especially with regard to detecting unfaithful claims. Our experiments suggest that detecting unfaithful claims is an important future direction not only for summarization evaluation but also as a testbed for long-context understanding. Finally, we move beyond faithfulness by exploring content selection errors in book-length summarization: we develop a typology of omission errors related to crucial narrative elements and also identify a systematic over-emphasis on events occurring towards the end of the book.
Localizing and Editing Knowledge in Text-to-Image Generative Models
Oct 20, 2023Text-to-Image Diffusion Models such as Stable-Diffusion and Imagen have achieved unprecedented quality of photorealism with state-of-the-art FID scores on MS-COCO and other generation benchmarks. Given a caption, image generation requires fine-grained knowledge about attributes such as object structure, style, and viewpoint amongst others. Where does this information reside in text-to-image generative models? In our paper, we tackle this question and understand how knowledge corresponding to distinct visual attributes is stored in large-scale text-to-image diffusion models. We adapt Causal Mediation Analysis for text-to-image models and trace knowledge about distinct visual attributes to various (causal) components in the (i) UNet and (ii) text-encoder of the diffusion model. In particular, we show that unlike generative large-language models, knowledge about different attributes is not localized in isolated components, but is instead distributed amongst a set of components in the conditional UNet. These sets of components are often distinct for different visual attributes. Remarkably, we find that the CLIP text-encoder in public text-to-image models such as Stable-Diffusion contains only one causal state across different visual attributes, and this is the first self-attention layer corresponding to the last subject token of the attribute in the caption. This is in stark contrast to the causal states in other language models which are often the mid-MLP layers. Based on this observation of only one causal state in the text-encoder, we introduce a fast, data-free model editing method Diff-QuickFix which can effectively edit concepts in text-to-image models. DiffQuickFix can edit (ablate) concepts in under a second with a closed-form update, providing a significant 1000x speedup and comparable editing performance to existing fine-tuning based editing methods.
KNN-LM Does Not Improve Open-ended Text Generation
May 24, 2023



In this paper, we study the generation quality of interpolation-based retrieval-augmented language models (LMs). These methods, best exemplified by the KNN-LM, interpolate the LM's predicted distribution of the next word with a distribution formed from the most relevant retrievals for a given prefix. While the KNN-LM and related methods yield impressive decreases in perplexity, we discover that they do not exhibit corresponding improvements in open-ended generation quality, as measured by both automatic evaluation metrics (e.g., MAUVE) and human evaluations. Digging deeper, we find that interpolating with a retrieval distribution actually increases perplexity compared to a baseline Transformer LM for the majority of tokens in the WikiText-103 test set, even though the overall perplexity is lower due to a smaller number of tokens for which perplexity dramatically decreases after interpolation. However, when decoding a long sequence at inference time, significant improvements on this smaller subset of tokens are washed out by slightly worse predictions on most tokens. Furthermore, we discover that the entropy of the retrieval distribution increases faster than that of the base LM as the generated sequence becomes longer, which indicates that retrieval is less reliable when using model-generated text as queries (i.e., is subject to exposure bias). We hope that our analysis spurs future work on improved decoding algorithms and interpolation strategies for retrieval-augmented language models.