 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Reward Auditing for Active Detection and Mitigation of Reward Hacking
Feb 02, 2026Reinforcement Learning from Human Feedback (RLHF) remains vulnerable to reward hacking, where models exploit spurious correlations in learned reward models to achieve high scores while violating human intent. Existing mitigations rely on static defenses that cannot adapt to novel exploitation strategies. We propose Adversarial Reward Auditing (ARA), a framework that reconceptualizes reward hacking as a dynamic, competitive game. ARA operates in two stages: first, a Hacker policy discovers reward model vulnerabilities while an Auditor learns to detect exploitation from latent representations; second, Auditor-Guided RLHF (AG-RLHF) gates reward signals to penalize detected hacking, transforming reward hacking from an unobservable failure into a measurable, controllable signal. Experiments across three hacking scenarios demonstrate that ARA achieves the best alignment-utility tradeoff among all baselines: reducing sycophancy to near-SFT levels while improving helpfulness, decreasing verbosity while achieving the highest ROUGE-L, and suppressing code gaming while improving Pass@1. Beyond single-domain evaluation, we show that reward hacking, detection, and mitigation all generalize across domains -- a Hacker trained on code gaming exhibits increased sycophancy despite no reward for this behavior, and an Auditor trained on one domain effectively suppresses exploitation in others, enabling efficient multi-domain defense with a single model.
A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models
Feb 22, 2025



The rise of foundation models has transformed machine learning research, prompting efforts to uncover their inner workings and develop more efficient and reliable applications for better control. While significant progress has been made in interpreting Large Language Models (LLMs), multimodal foundation models (MMFMs) - such as contrastive vision-language models, generative vision-language models, and text-to-image models - pose unique interpretability challenges beyond unimodal frameworks. Despite initial studies, a substantial gap remains between the interpretability of LLMs and MMFMs. This survey explores two key aspects: (1) the adaptation of LLM interpretability methods to multimodal models and (2) understanding the mechanistic differences between unimodal language models and crossmodal systems. By systematically reviewing current MMFM analysis techniques, we propose a structured taxonomy of interpretability methods, compare insights across unimodal and multimodal architectures, and highlight critical research gaps.
Rethinking the Uncertainty: A Critical Review and Analysis in the Era of Large Language Models
Oct 26, 2024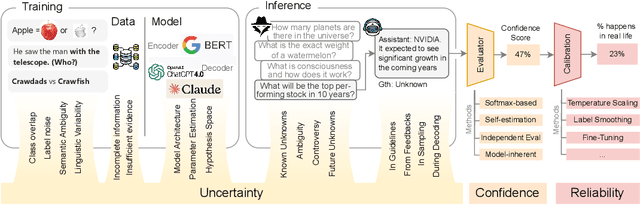
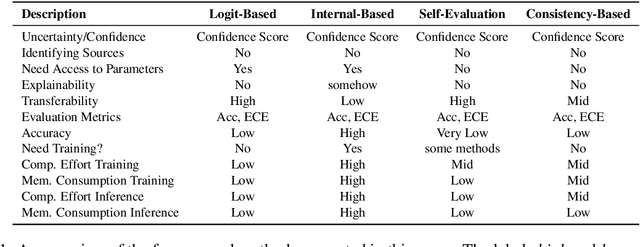
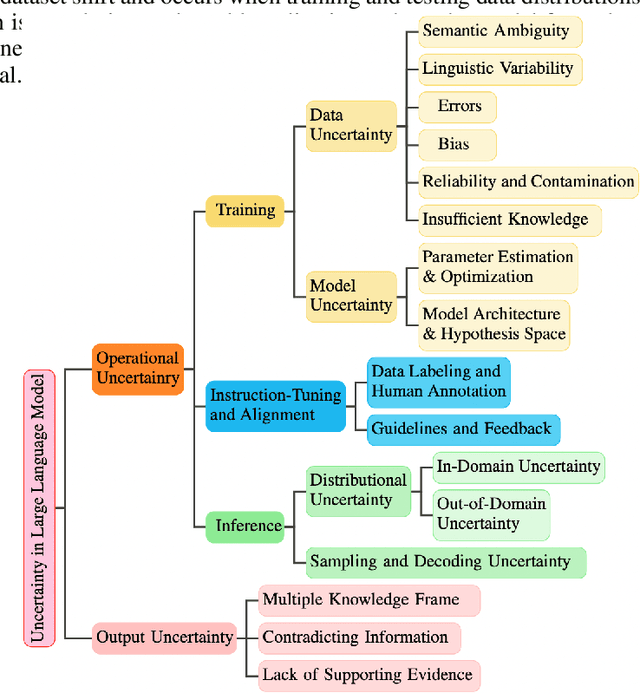
In recent years, Large Language Models (LLMs) have become fundamental to a broad spectrum of artificial intelligence applications. As the use of LLMs expands, precisely estimating the uncertainty in their predictions has become crucial. Current methods often struggle to accurately identify, measure, and address the true uncertainty, with many focusing primarily on estimating model confidence. This discrepancy is largely due to an incomplete understanding of where, when, and how uncertainties are injected into models. This paper introduces a comprehensive framework specifically designed to identify and understand the types and sources of uncertainty, aligned with the unique characteristics of LLMs. Our framework enhances the understanding of the diverse landscape of uncertainties by systematically categorizing and defining each type, establishing a solid foundation for developing targeted methods that can precisely quantify these uncertainties. We also provide a detailed introduction to key related concepts and examine the limitations of current methods in mission-critical and safety-sensitive applications. The paper concludes with a perspective on future directions aimed at enhancing the reliability and practical adoption of these methods in real-world scenarios.
InternalInspector $I^2$: Robust Confidence Estimation in LLMs through Internal States
Jun 17, 2024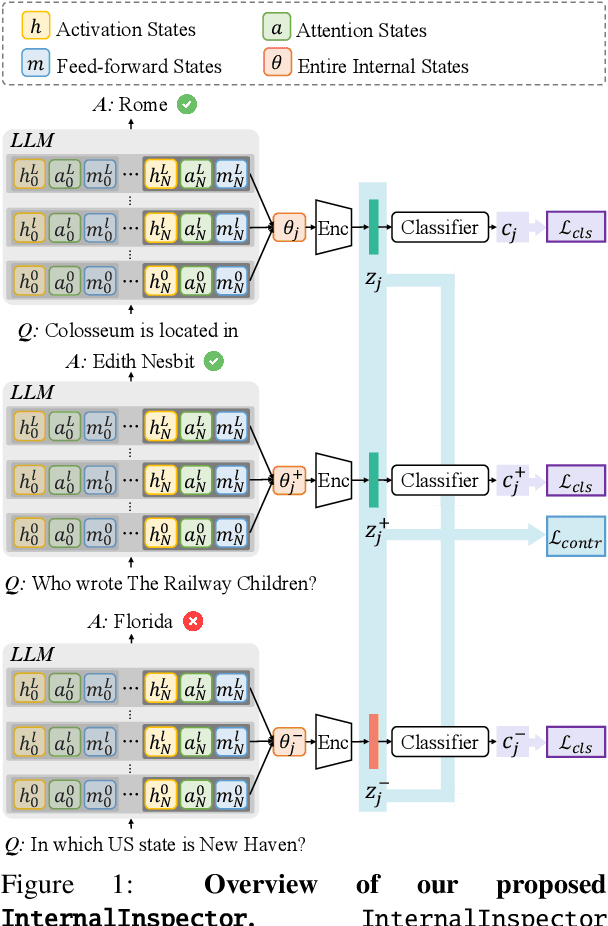
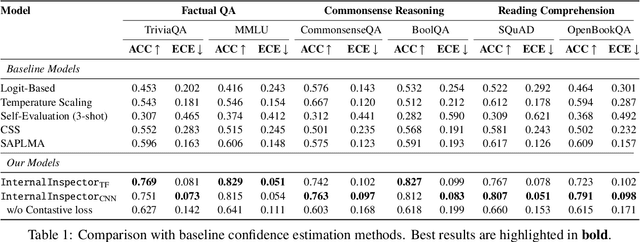
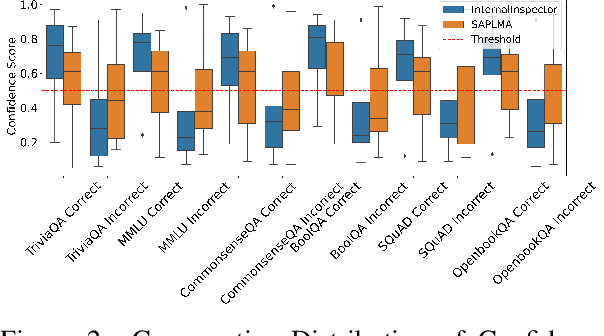
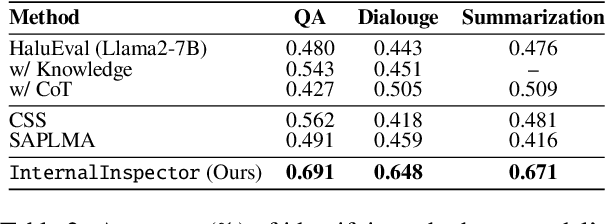
Despite their vast capabilities, Large Language Models (LLMs) often struggle with generating reliable outputs, frequently producing high-confidence inaccuracies known as hallucinations. Addressing this challenge, our research introduces InternalInspector, a novel framework designed to enhance confidence estimation in LLMs by leveraging contrastive learning on internal states including attention states, feed-forward states, and activation states of all layers. Unlike existing methods that primarily focus on the final activation state, InternalInspector conducts a comprehensive analysis across all internal states of every layer to accurately identify both correct and incorrect prediction processes. By benchmarking InternalInspector against existing confidence estimation methods across various natural language understanding and generation tasks, including factual question answering, commonsense reasoning, and reading comprehension, InternalInspector achieves significantly higher accuracy in aligning the estimated confidence scores with the correctness of the LLM's predictions and lower calibration error. Furthermore, InternalInspector excels at HaluEval, a hallucination detection benchmark, outperforming other internal-based confidence estimation methods in this task.
Navigating the Dual Facets: A Comprehensive Evaluation of Sequential Memory Editing in Large Language Models
Feb 16, 2024


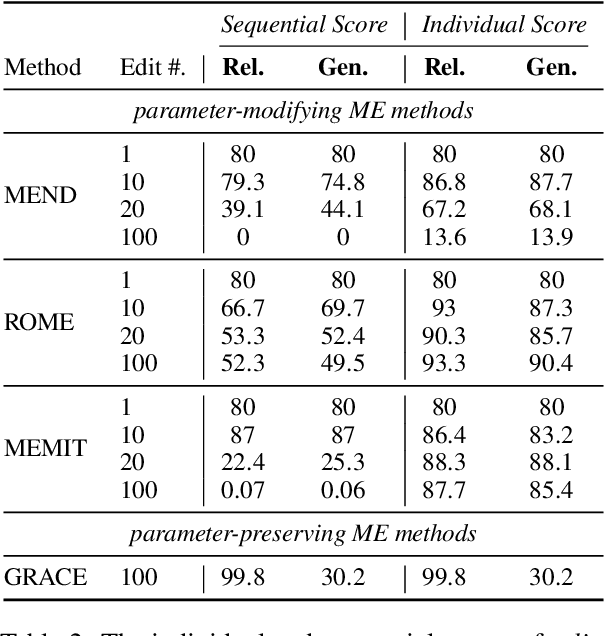
Memory Editing (ME) has emerged as an efficient method to modify erroneous facts or inject new facts into Large Language Models (LLMs). Two mainstream ME methods exist: parameter-modifying ME and parameter-preserving ME (integrating extra modules while preserving original parameters). Regrettably, previous studies on ME evaluation have two critical limitations: (i) evaluating LLMs with single edit only, neglecting the need for continuous editing, and (ii) evaluations focusing solely on basic factual triples, overlooking broader LLM capabilities like logical reasoning and reading understanding. This study addresses these limitations with contributions threefold: (i) We explore how ME affects a wide range of fundamental capabilities of LLMs under sequential editing. Experimental results reveal an intriguing phenomenon: Most parameter-modifying ME consistently degrade performance across all tasks after a few sequential edits. In contrast, parameter-preserving ME effectively maintains LLMs' fundamental capabilities but struggles to accurately recall edited knowledge presented in a different format. (ii) We extend our evaluation to different editing settings, such as layers to edit, model size, instruction tuning, etc. Experimental findings indicate several strategies that can potentially mitigate the adverse effects of ME. (iii) We further explain why parameter-modifying ME damages LLMs from three dimensions: parameter changes after editing, language modeling capability, and the in-context learning capability. Our in-depth study advocates more careful use of ME in real-world scenarios.