 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Quantization through Multimodal Prompting for 3D Understanding
Nov 19, 2025Vector quantization has emerged as a powerful tool in large-scale multimodal models, unifying heterogeneous representations through discrete token encoding. However, its effectiveness hinges on robust codebook design. Current prototype-based approaches relying on trainable vectors or clustered centroids fall short in representativeness and interpretability, even as multimodal alignment demonstrates its promise in vision-language models. To address these limitations, we propose a simple multimodal prompting-driven quantization framework for point cloud analysis. Our methodology is built upon two core insights: 1) Text embeddings from pre-trained models inherently encode visual semantics through many-to-one contrastive alignment, naturally serving as robust prototype priors; and 2) Multimodal prompts enable adaptive refinement of these prototypes, effectively mitigating vision-language semantic gaps. The framework introduces a dual-constrained quantization space, enforced by compactness and separation regularization, which seamlessly integrates visual and prototype features, resulting in hybrid representations that jointly encode geometric and semantic information. Furthermore, we employ Gumbel-Softmax relaxation to achieve differentiable discretization while maintaining quantization sparsity. Extensive experiments on the ModelNet40 and ScanObjectNN datasets clearly demonstrate the superior effectiveness of the proposed method.
A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models
Feb 22, 2025



The rise of foundation models has transformed machine learning research, prompting efforts to uncover their inner workings and develop more efficient and reliable applications for better control. While significant progress has been made in interpreting Large Language Models (LLMs), multimodal foundation models (MMFMs) - such as contrastive vision-language models, generative vision-language models, and text-to-image models - pose unique interpretability challenges beyond unimodal frameworks. Despite initial studies, a substantial gap remains between the interpretability of LLMs and MMFMs. This survey explores two key aspects: (1) the adaptation of LLM interpretability methods to multimodal models and (2) understanding the mechanistic differences between unimodal language models and crossmodal systems. By systematically reviewing current MMFM analysis techniques, we propose a structured taxonomy of interpretability methods, compare insights across unimodal and multimodal architectures, and highlight critical research gaps.
Navigating the Dual Facets: A Comprehensive Evaluation of Sequential Memory Editing in Large Language Models
Feb 16, 2024


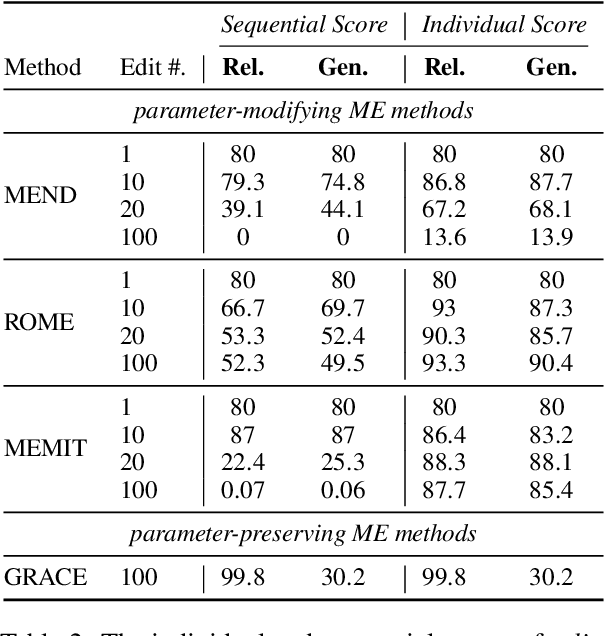
Memory Editing (ME) has emerged as an efficient method to modify erroneous facts or inject new facts into Large Language Models (LLMs). Two mainstream ME methods exist: parameter-modifying ME and parameter-preserving ME (integrating extra modules while preserving original parameters). Regrettably, previous studies on ME evaluation have two critical limitations: (i) evaluating LLMs with single edit only, neglecting the need for continuous editing, and (ii) evaluations focusing solely on basic factual triples, overlooking broader LLM capabilities like logical reasoning and reading understanding. This study addresses these limitations with contributions threefold: (i) We explore how ME affects a wide range of fundamental capabilities of LLMs under sequential editing. Experimental results reveal an intriguing phenomenon: Most parameter-modifying ME consistently degrade performance across all tasks after a few sequential edits. In contrast, parameter-preserving ME effectively maintains LLMs' fundamental capabilities but struggles to accurately recall edited knowledge presented in a different format. (ii) We extend our evaluation to different editing settings, such as layers to edit, model size, instruction tuning, etc. Experimental findings indicate several strategies that can potentially mitigate the adverse effects of ME. (iii) We further explain why parameter-modifying ME damages LLMs from three dimensions: parameter changes after editing, language modeling capability, and the in-context learning capability. Our in-depth study advocates more careful use of ME in real-world scenarios.
THInImg: Cross-modal Steganography for Presenting Talking Heads in Images
Nov 28, 2023Cross-modal Steganography is the practice of concealing secret signals in publicly available cover signals (distinct from the modality of the secret signals) unobtrusively. While previous approaches primarily concentrated on concealing a relatively small amount of information, we propose THInImg, which manages to hide lengthy audio data (and subsequently decode talking head video) inside an identity image by leveraging the properties of human face, which can be effectively utilized for covert communication, transmission and copyright protection. THInImg consists of two parts: the encoder and decoder. Inside the encoder-decoder pipeline, we introduce a novel architecture that substantially increase the capacity of hiding audio in images. Moreover, our framework can be extended to iteratively hide multiple audio clips into an identity image, offering multiple levels of control over permissions. We conduct extensive experiments to prove the effectiveness of our method, demonstrating that THInImg can present up to 80 seconds of high quality talking-head video (including audio) in an identity image with 160x160 resolution.