 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models on Solved and Unsolved Problems in Graph Theory: Implications for Computing Education
Feb 04, 2026Large Language Models are increasingly used by students to explore advanced material in computer science, including graph theory. As these tools become integrated into undergraduate and graduate coursework, it is important to understand how reliably they support mathematically rigorous thinking. This study examines the performance of a LLM on two related graph theoretic problems: a solved problem concerning the gracefulness of line graphs and an open problem for which no solution is currently known. We use an eight stage evaluation protocol that reflects authentic mathematical inquiry, including interpretation, exploration, strategy formation, and proof construction. The model performed strongly on the solved problem, producing correct definitions, identifying relevant structures, recalling appropriate results without hallucination, and constructing a valid proof confirmed by a graph theory expert. For the open problem, the model generated coherent interpretations and plausible exploratory strategies but did not advance toward a solution. It did not fabricate results and instead acknowledged uncertainty, which is consistent with the explicit prompting instructions that directed the model to avoid inventing theorems or unsupported claims. These findings indicate that LLMs can support exploration of established material but remain limited in tasks requiring novel mathematical insight or critical structural reasoning. For computing education, this distinction highlights the importance of guiding students to use LLMs for conceptual exploration while relying on independent verification and rigorous argumentation for formal problem solving.
DiagnoLLM: A Hybrid Bayesian Neural Language Framework for Interpretable Disease Diagnosis
Nov 16, 2025Building trustworthy clinical AI systems requires not only accurate predictions but also transparent, biologically grounded explanations. We present \texttt{DiagnoLLM}, a hybrid framework that integrates Bayesian deconvolution, eQTL-guided deep learning, and LLM-based narrative generation for interpretable disease diagnosis. DiagnoLLM begins with GP-unmix, a Gaussian Process-based hierarchical model that infers cell-type-specific gene expression profiles from bulk and single-cell RNA-seq data while modeling biological uncertainty. These features, combined with regulatory priors from eQTL analysis, power a neural classifier that achieves high predictive performance in Alzheimer's Disease (AD) detection (88.0\% accuracy). To support human understanding and trust, we introduce an LLM-based reasoning module that translates model outputs into audience-specific diagnostic reports, grounded in clinical features, attribution signals, and domain knowledge. Human evaluations confirm that these reports are accurate, actionable, and appropriately tailored for both physicians and patients. Our findings show that LLMs, when deployed as post-hoc reasoners rather than end-to-end predictors, can serve as effective communicators within hybrid diagnostic pipelines.
GENUINE: Graph Enhanced Multi-level Uncertainty Estimation for Large Language Models
Sep 09, 2025Uncertainty estimation is essential for enhancing the reliability of Large Language Models (LLMs), particularly in high-stakes applications. Existing methods often overlook semantic dependencies, relying on token-level probability measures that fail to capture structural relationships within the generated text. We propose GENUINE: Graph ENhanced mUlti-level uncertaINty Estimation for Large Language Models, a structure-aware framework that leverages dependency parse trees and hierarchical graph pooling to refine uncertainty quantification. By incorporating supervised learning, GENUINE effectively models semantic and structural relationships, improving confidence assessments. Extensive experiments across NLP tasks show that GENUINE achieves up to 29% higher AUROC than semantic entropy-based approaches and reduces calibration errors by over 15%, demonstrating the effectiveness of graph-based uncertainty modeling. The code is available at https://github.com/ODYSSEYWT/GUQ.
Non-exchangeable Conformal Prediction for Temporal Graph Neural Networks
Jul 02, 2025Conformal prediction for graph neural networks (GNNs) offers a promising framework for quantifying uncertainty, enhancing GNN reliability in high-stakes applications. However, existing methods predominantly focus on static graphs, neglecting the evolving nature of real-world graphs. Temporal dependencies in graph structure, node attributes, and ground truth labels violate the fundamental exchangeability assumption of standard conformal prediction methods, limiting their applicability. To address these challenges, in this paper, we introduce NCPNET, a novel end-to-end conformal prediction framework tailored for temporal graphs. Our approach extends conformal prediction to dynamic settings, mitigating statistical coverage violations induced by temporal dependencies. To achieve this, we propose a diffusion-based non-conformity score that captures both topological and temporal uncertainties within evolving networks. Additionally, we develop an efficiency-aware optimization algorithm that improves the conformal prediction process, enhancing computational efficiency and reducing coverage violations. Extensive experiments on diverse real-world temporal graphs, including WIKI, REDDIT, DBLP, and IBM Anti-Money Laundering dataset, demonstrate NCPNET's capability to ensure guaranteed coverage in temporal graphs, achieving up to a 31% reduction in prediction set size on the WIKI dataset, significantly improving efficiency compared to state-of-the-art methods. Our data and code are available at https://github.com/ODYSSEYWT/NCPNET.
Scientific Hypothesis Generation and Validation: Methods, Datasets, and Future Directions
May 06, 2025Large Language Models (LLMs) are transforming scientific hypothesis generation and validation by enabling information synthesis, latent relationship discovery, and reasoning augmentation. This survey provides a structured overview of LLM-driven approaches, including symbolic frameworks, generative models, hybrid systems, and multi-agent architectures. We examine techniques such as retrieval-augmented generation, knowledge-graph completion, simulation, causal inference, and tool-assisted reasoning, highlighting trade-offs in interpretability, novelty, and domain alignment. We contrast early symbolic discovery systems (e.g., BACON, KEKADA) with modern LLM pipelines that leverage in-context learning and domain adaptation via fine-tuning, retrieval, and symbolic grounding. For validation, we review simulation, human-AI collaboration, causal modeling, and uncertainty quantification, emphasizing iterative assessment in open-world contexts. The survey maps datasets across biomedicine, materials science, environmental science, and social science, introducing new resources like AHTech and CSKG-600. Finally, we outline a roadmap emphasizing novelty-aware generation, multimodal-symbolic integration, human-in-the-loop systems, and ethical safeguards, positioning LLMs as agents for principled, scalable scientific discovery.
MetaScientist: A Human-AI Synergistic Framework for Automated Mechanical Metamaterial Design
Dec 20, 2024



The discovery of novel mechanical metamaterials, whose properties are dominated by their engineered structures rather than chemical composition, is a knowledge-intensive and resource-demanding process. To accelerate the design of novel metamaterials, we present MetaScientist, a human-in-the-loop system that integrates advanced AI capabilities with expert oversight with two primary phases: (1) hypothesis generation, where the system performs complex reasoning to generate novel and scientifically sound hypotheses, supported with domain-specific foundation models and inductive biases retrieved from existing literature; (2) 3D structure synthesis, where a 3D structure is synthesized with a novel 3D diffusion model based on the textual hypothesis and refined it with a LLM-based refinement model to achieve better structure properties. At each phase, domain experts iteratively validate the system outputs, and provide feedback and supplementary materials to ensure the alignment of the outputs with scientific principles and human preferences. Through extensive evaluation from human scientists, MetaScientist is able to deliver novel and valid mechanical metamaterial designs that have the potential to be highly impactful in the metamaterial field.
Rethinking the Uncertainty: A Critical Review and Analysis in the Era of Large Language Models
Oct 26, 2024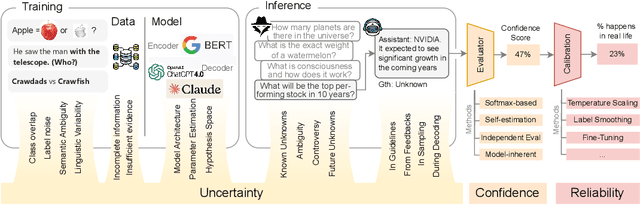
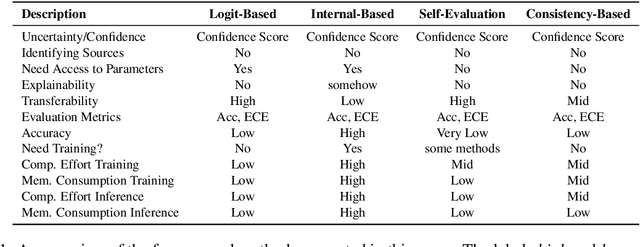
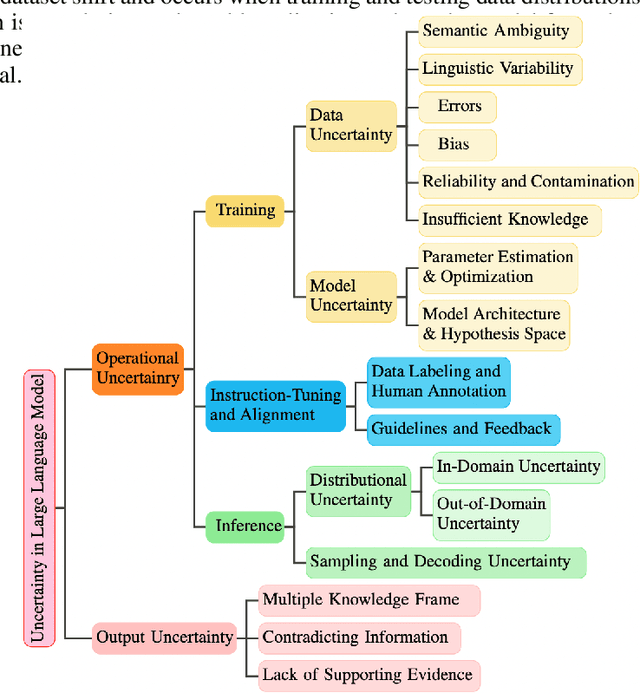
In recent years, Large Language Models (LLMs) have become fundamental to a broad spectrum of artificial intelligence applications. As the use of LLMs expands, precisely estimating the uncertainty in their predictions has become crucial. Current methods often struggle to accurately identify, measure, and address the true uncertainty, with many focusing primarily on estimating model confidence. This discrepancy is largely due to an incomplete understanding of where, when, and how uncertainties are injected into models. This paper introduces a comprehensive framework specifically designed to identify and understand the types and sources of uncertainty, aligned with the unique characteristics of LLMs. Our framework enhances the understanding of the diverse landscape of uncertainties by systematically categorizing and defining each type, establishing a solid foundation for developing targeted methods that can precisely quantify these uncertainties. We also provide a detailed introduction to key related concepts and examine the limitations of current methods in mission-critical and safety-sensitive applications. The paper concludes with a perspective on future directions aimed at enhancing the reliability and practical adoption of these methods in real-world scenarios.
Empirical Analysis for Unsupervised Universal Dependency Parse Tree Aggregation
Apr 03, 2024



Dependency parsing is an essential task in NLP, and the quality of dependency parsers is crucial for many downstream tasks. Parsers' quality often varies depending on the domain and the language involved. Therefore, it is essential to combat the issue of varying quality to achieve stable performance. In various NLP tasks, aggregation methods are used for post-processing aggregation and have been shown to combat the issue of varying quality. However, aggregation methods for post-processing aggregation have not been sufficiently studied in dependency parsing tasks. In an extensive empirical study, we compare different unsupervised post-processing aggregation methods to identify the most suitable dependency tree structure aggregation method.
An Empirical Study of Using ChatGPT for Fact Verification Task
Nov 11, 2023



ChatGPT has recently emerged as a powerful tool for performing diverse NLP tasks. However, ChatGPT has been criticized for generating nonfactual responses, raising concerns about its usability for sensitive tasks like fact verification. This study investigates three key research questions: (1) Can ChatGPT be used for fact verification tasks? (2) What are different prompts performance using ChatGPT for fact verification tasks? (3) For the best-performing prompt, what common mistakes does ChatGPT make? Specifically, this study focuses on conducting a comprehensive and systematic analysis by designing and comparing the performance of three different prompts for fact verification tasks on the benchmark FEVER dataset using ChatGPT.
Zero-shot Approach to Overcome Perturbation Sensitivity of Prompts
May 25, 2023
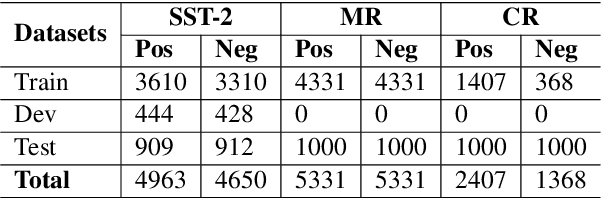
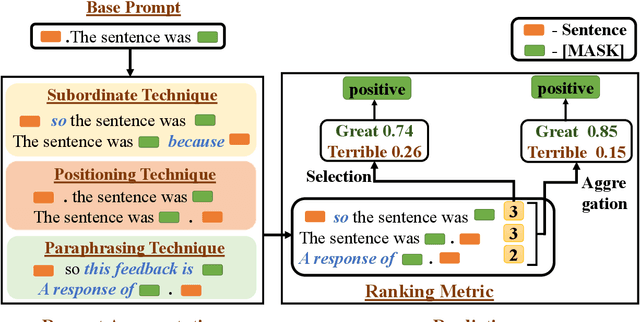
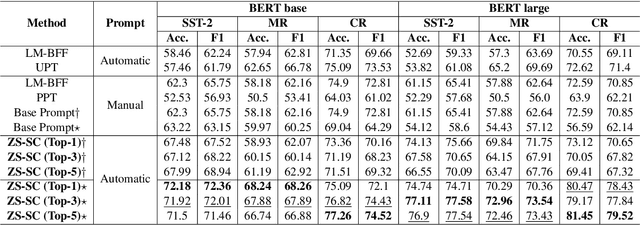
Recent studies have demonstrated that natural-language prompts can help to leverage the knowledge learned by pre-trained language models for the binary sentence-level sentiment classification task. Specifically, these methods utilize few-shot learning settings to fine-tune the sentiment classification model using manual or automatically generated prompts. However, the performance of these methods is sensitive to the perturbations of the utilized prompts. Furthermore, these methods depend on a few labeled instances for automatic prompt generation and prompt ranking. This study aims to find high-quality prompts for the given task in a zero-shot setting. Given a base prompt, our proposed approach automatically generates multiple prompts similar to the base prompt employing positional, reasoning, and paraphrasing techniques and then ranks the prompts using a novel metric. We empirically demonstrate that the top-ranked prompts are high-quality and significantly outperform the base prompt and the prompts generated using few-shot learning for the binary sentence-level sentiment classification task.