 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPTAM: Constituency Parse Tree Aggregation Method
Jan 19, 2022

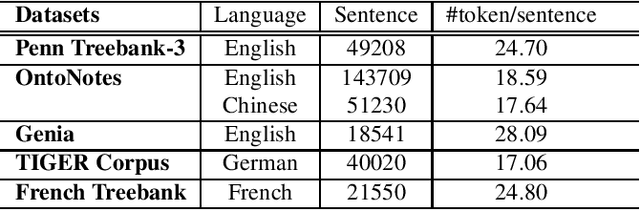
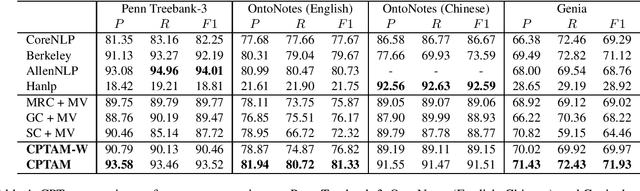
Diverse Natural Language Processing tasks employ constituency parsing to understand the syntactic structure of a sentence according to a phrase structure grammar. Many state-of-the-art constituency parsers are proposed, but they may provide different results for the same sentences, especially for corpora outside their training domains. This paper adopts the truth discovery idea to aggregate constituency parse trees from different parsers by estimating their reliability in the absence of ground truth. Our goal is to consistently obtain high-quality aggregated constituency parse trees. We formulate the constituency parse tree aggregation problem in two steps, structure aggregation and constituent label aggregation. Specifically, we propose the first truth discovery solution for tree structures by minimizing the weighted sum of Robinson-Foulds (RF) distances, a classic symmetric distance metric between two trees. Extensive experiments are conducted on benchmark datasets in different languages and domains. The experimental results show that our method, CPTAM, outperforms the state-of-the-art aggregation baselines. We also demonstrate that the weights estimated by CPTAM can adequately evaluate constituency parsers in the absence of ground truth.
Truth Discovery in Sequence Labels from Crowds
Sep 09, 2021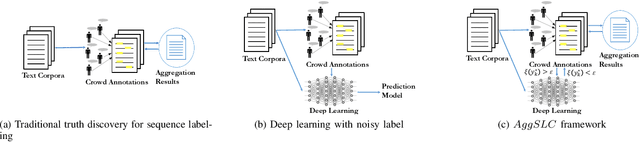
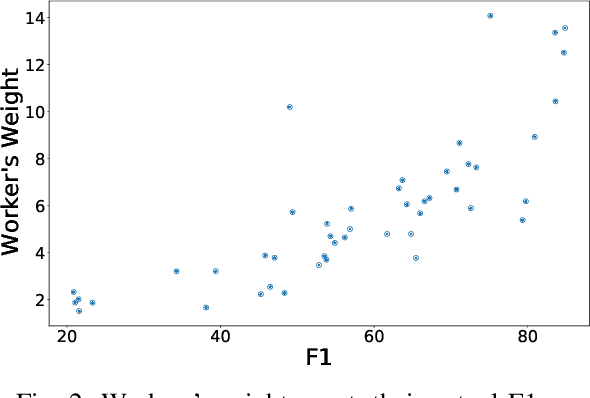
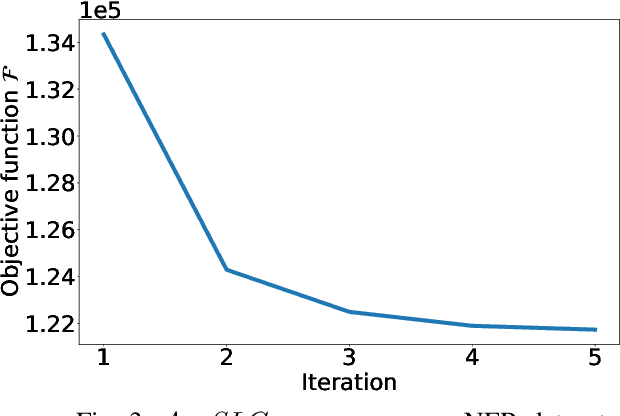
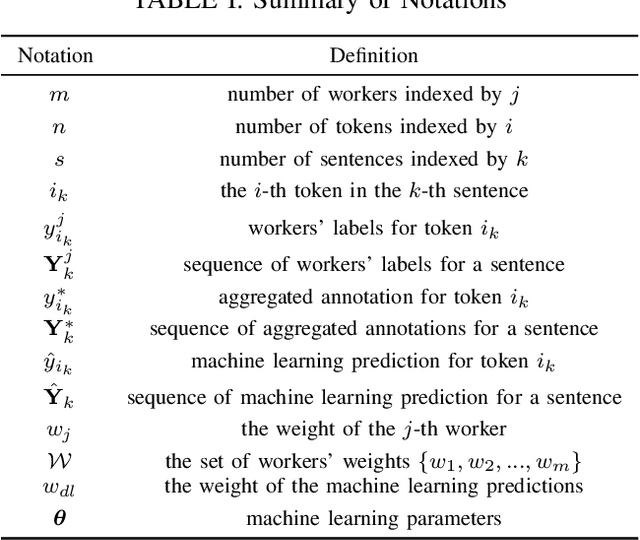
Annotations quality and quantity positively affect the performance of sequence labeling, a vital task in Natural Language Processing. Hiring domain experts to annotate a corpus set is very costly in terms of money and time. Crowdsourcing platforms, such as Amazon Mechanical Turk (AMT), have been deployed to assist in this purpose. However, these platforms are prone to human errors due to the lack of expertise; hence, one worker's annotations cannot be directly used to train the model. Existing literature in annotation aggregation more focuses on binary or multi-choice problems. In recent years, handling the sequential label aggregation tasks on imbalanced datasets with complex dependencies between tokens has been challenging. To conquer the challenge, we propose an optimization-based method that infers the best set of aggregated annotations using labels provided by workers. The proposed Aggregation method for Sequential Labels from Crowds ($AggSLC$) jointly considers the characteristics of sequential labeling tasks, workers' reliabilities, and advanced machine learning techniques. We evaluate $AggSLC$ on different crowdsourced data for Named Entity Recognition (NER), Information Extraction tasks in biomedical (PICO), and the simulated dataset. Our results show that the proposed method outperforms the state-of-the-art aggregation methods. To achieve insights into the framework, we study $AggSLC$ components' effectiveness through ablation studies by evaluating our model in the absence of the prediction module and inconsistency loss function. Theoretical analysis of our algorithm's convergence points that the proposed $AggSLC$ halts after a finite number of iterations.