 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruth Discovery in Sequence Labels from Crowds
Paper and Code
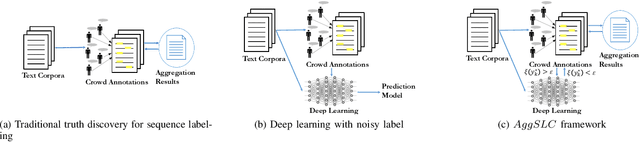
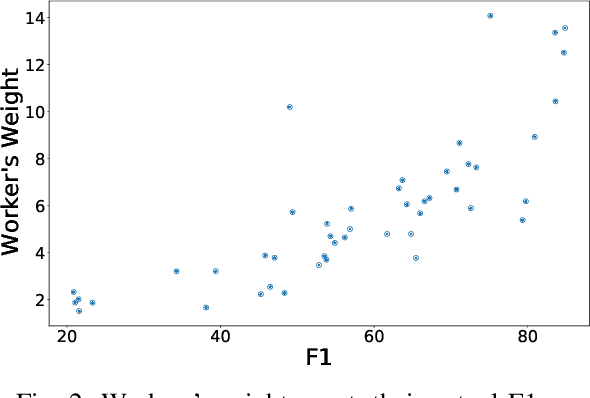
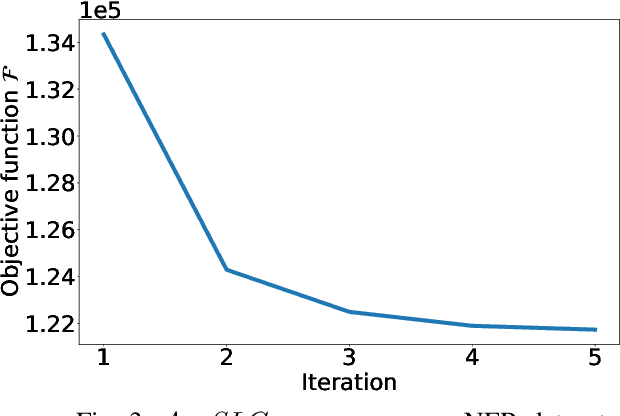
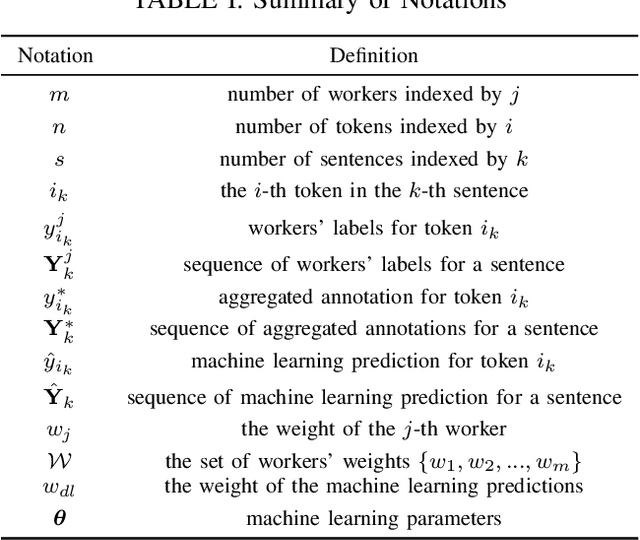
Annotations quality and quantity positively affect the performance of sequence labeling, a vital task in Natural Language Processing. Hiring domain experts to annotate a corpus set is very costly in terms of money and time. Crowdsourcing platforms, such as Amazon Mechanical Turk (AMT), have been deployed to assist in this purpose. However, these platforms are prone to human errors due to the lack of expertise; hence, one worker's annotations cannot be directly used to train the model. Existing literature in annotation aggregation more focuses on binary or multi-choice problems. In recent years, handling the sequential label aggregation tasks on imbalanced datasets with complex dependencies between tokens has been challenging. To conquer the challenge, we propose an optimization-based method that infers the best set of aggregated annotations using labels provided by workers. The proposed Aggregation method for Sequential Labels from Crowds ($AggSLC$) jointly considers the characteristics of sequential labeling tasks, workers' reliabilities, and advanced machine learning techniques. We evaluate $AggSLC$ on different crowdsourced data for Named Entity Recognition (NER), Information Extraction tasks in biomedical (PICO), and the simulated dataset. Our results show that the proposed method outperforms the state-of-the-art aggregation methods. To achieve insights into the framework, we study $AggSLC$ components' effectiveness through ablation studies by evaluating our model in the absence of the prediction module and inconsistency loss function. Theoretical analysis of our algorithm's convergence points that the proposed $AggSLC$ halts after a finite number of iterations.