 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025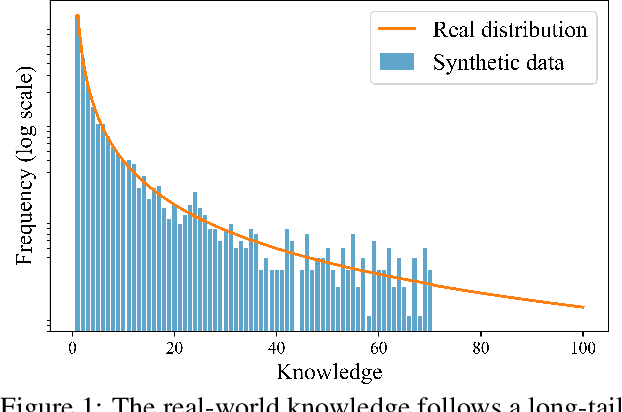
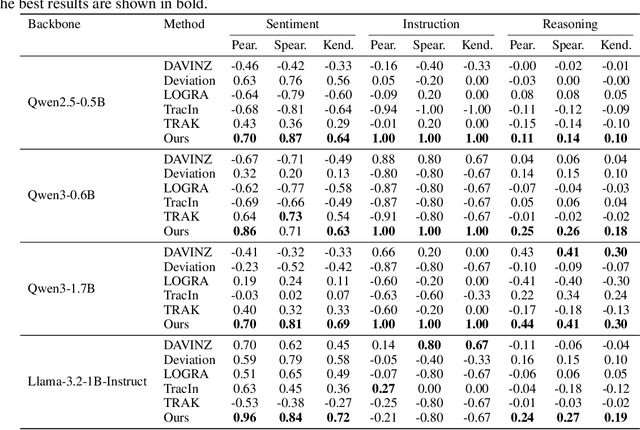
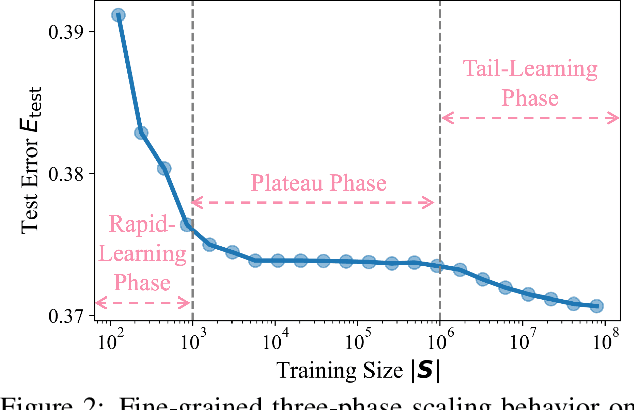
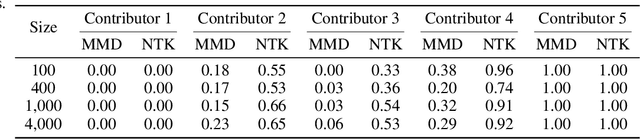
The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.
ChemBOMAS: Accelerated BO in Chemistry with LLM-Enhanced Multi-Agent System
Sep 10, 2025The efficiency of Bayesian optimization (BO) in chemistry is often hindered by sparse experimental data and complex reaction mechanisms. To overcome these limitations, we introduce ChemBOMAS, a new framework named LLM-Enhanced Multi-Agent System for accelerating BO in chemistry. ChemBOMAS's optimization process is enhanced by LLMs and synergistically employs two strategies: knowledge-driven coarse-grained optimization and data-driven fine-grained optimization. First, in the knowledge-driven coarse-grained optimization stage, LLMs intelligently decompose the vast search space by reasoning over existing chemical knowledge to identify promising candidate regions. Subsequently, in the data-driven fine-grained optimization stage, LLMs enhance the BO process within these candidate regions by generating pseudo-data points, thereby improving data utilization efficiency and accelerating convergence. Benchmark evaluations** further confirm that ChemBOMAS significantly enhances optimization effectiveness and efficiency compared to various BO algorithms. Importantly, the practical utility of ChemBOMAS was validated through wet-lab experiments conducted under pharmaceutical industry protocols, targeting conditional optimization for a previously unreported and challenging chemical reaction. In the wet experiment, ChemBOMAS achieved an optimal objective value of 96%. This was substantially higher than the 15% achieved by domain experts. This real-world success, together with strong performance on benchmark evaluations, highlights ChemBOMAS as a powerful tool to accelerate chemical discovery.
MetaScientist: A Human-AI Synergistic Framework for Automated Mechanical Metamaterial Design
Dec 20, 2024



The discovery of novel mechanical metamaterials, whose properties are dominated by their engineered structures rather than chemical composition, is a knowledge-intensive and resource-demanding process. To accelerate the design of novel metamaterials, we present MetaScientist, a human-in-the-loop system that integrates advanced AI capabilities with expert oversight with two primary phases: (1) hypothesis generation, where the system performs complex reasoning to generate novel and scientifically sound hypotheses, supported with domain-specific foundation models and inductive biases retrieved from existing literature; (2) 3D structure synthesis, where a 3D structure is synthesized with a novel 3D diffusion model based on the textual hypothesis and refined it with a LLM-based refinement model to achieve better structure properties. At each phase, domain experts iteratively validate the system outputs, and provide feedback and supplementary materials to ensure the alignment of the outputs with scientific principles and human preferences. Through extensive evaluation from human scientists, MetaScientist is able to deliver novel and valid mechanical metamaterial designs that have the potential to be highly impactful in the metamaterial field.
SiMilarity-Enhanced Homophily for Multi-View Heterophilous Graph Clustering
Oct 04, 2024With the increasing prevalence of graph-structured data, multi-view graph clustering has been widely used in various downstream applications. Existing approaches primarily rely on a unified message passing mechanism, which significantly enhances clustering performance. Nevertheless, this mechanism limits its applicability to heterophilous situations, as it is fundamentally predicated on the assumption of homophily, i.e., the connected nodes often belong to the same class. In reality, this assumption does not always hold; a moderately or even mildly homophilous graph is more common than a fully homophilous one due to inevitable heterophilous information in the graph. To address this issue, in this paper, we propose a novel SiMilarity-enhanced Homophily for Multi-view Heterophilous Graph Clustering (SMHGC) approach. By analyzing the relationship between similarity and graph homophily, we propose to enhance the homophily by introducing three similarity terms, i.e., neighbor pattern similarity, node feature similarity, and multi-view global similarity, in a label-free manner. Then, a consensus-based inter- and intra-view fusion paradigm is proposed to fuse the improved homophilous graph from different views and utilize them for clustering. The state-of-the-art experimental results on both multi-view heterophilous and homophilous datasets collectively demonstrate the strong capacity of similarity for unsupervised multi-view heterophilous graph learning. Additionally, the consistent performance across semi-synthetic datasets with varying levels of homophily serves as further evidence of SMHGC's resilience to heterophily.
Homophily-Related: Adaptive Hybrid Graph Filter for Multi-View Graph Clustering
Jan 05, 2024Recently there is a growing focus on graph data, and multi-view graph clustering has become a popular area of research interest. Most of the existing methods are only applicable to homophilous graphs, yet the extensive real-world graph data can hardly fulfill the homophily assumption, where the connected nodes tend to belong to the same class. Several studies have pointed out that the poor performance on heterophilous graphs is actually due to the fact that conventional graph neural networks (GNNs), which are essentially low-pass filters, discard information other than the low-frequency information on the graph. Nevertheless, on certain graphs, particularly heterophilous ones, neglecting high-frequency information and focusing solely on low-frequency information impedes the learning of node representations. To break this limitation, our motivation is to perform graph filtering that is closely related to the homophily degree of the given graph, with the aim of fully leveraging both low-frequency and high-frequency signals to learn distinguishable node embedding. In this work, we propose Adaptive Hybrid Graph Filter for Multi-View Graph Clustering (AHGFC). Specifically, a graph joint process and graph joint aggregation matrix are first designed by using the intrinsic node features and adjacency relationship, which makes the low and high-frequency signals on the graph more distinguishable. Then we design an adaptive hybrid graph filter that is related to the homophily degree, which learns the node embedding based on the graph joint aggregation matrix. After that, the node embedding of each view is weighted and fused into a consensus embedding for the downstream task. Experimental results show that our proposed model performs well on six datasets containing homophilous and heterophilous graphs.
HeroLT: Benchmarking Heterogeneous Long-Tailed Learning
Jul 17, 2023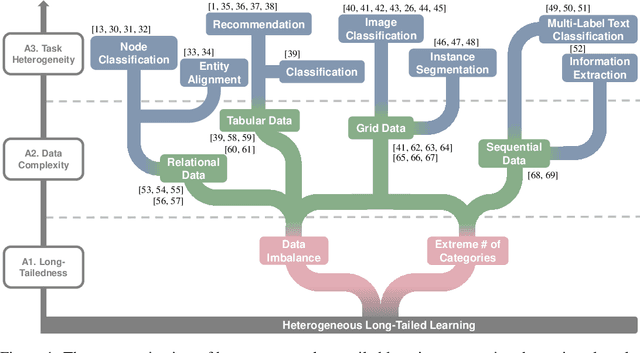


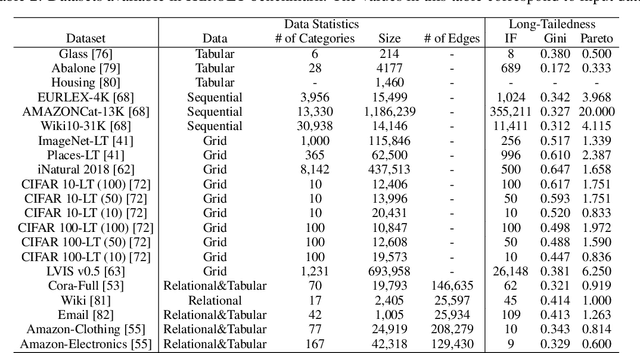
Long-tailed data distributions are prevalent in a variety of domains, including finance, e-commerce, biomedical science, and cyber security. In such scenarios, the performance of machine learning models is often dominated by the head categories, while the learning of tail categories is significantly inadequate. Given abundant studies conducted to alleviate the issue, this work aims to provide a systematic view of long-tailed learning with regard to three pivotal angles: (A1) the characterization of data long-tailedness, (A2) the data complexity of various domains, and (A3) the heterogeneity of emerging tasks. To achieve this, we develop the most comprehensive (to the best of our knowledge) long-tailed learning benchmark named HeroLT, which integrates 13 state-of-the-art algorithms and 6 evaluation metrics on 14 real-world benchmark datasets across 4 tasks from 3 domains. HeroLT with novel angles and extensive experiments (264 in total) enables researchers and practitioners to effectively and fairly evaluate newly proposed methods compared with existing baselines on varying types of datasets. Finally, we conclude by highlighting the significant applications of long-tailed learning and identifying several promising future directions. For accessibility and reproducibility, we open-source our benchmark HeroLT and corresponding results at https://github.com/SSSKJ/HeroLT.
Variational Graph Generator for Multi-View Graph Clustering
Oct 13, 2022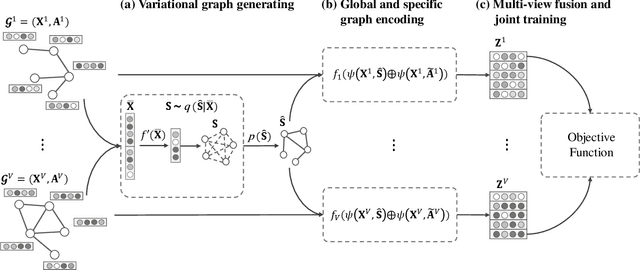
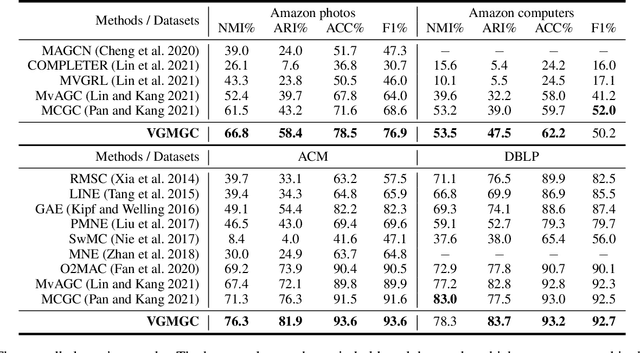
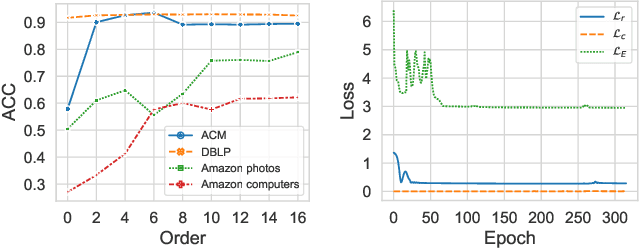
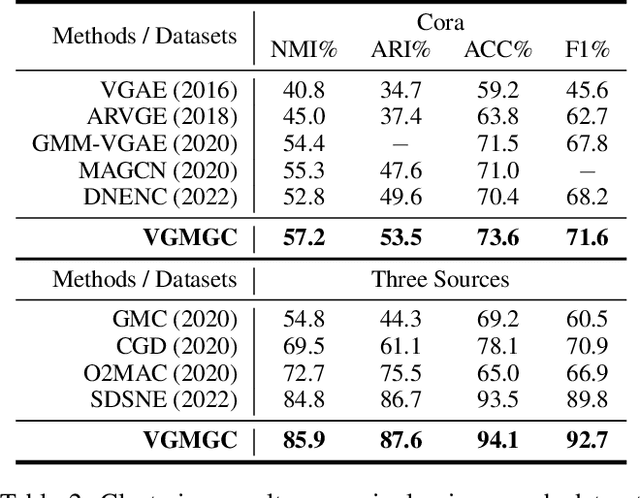
Multi-view graph clustering (MGC) methods are increasingly being studied due to the rising of multi-view data with graph structural information. The critical point of MGC is to better utilize the view-specific and view-common information in features and graphs of multiple views. However, existing works have an inherent limitation that they are unable to concurrently utilize the consensus graph information across multiple graphs and the view-specific feature information. To address this issue, we propose Variational Graph Generator for Multi-View Graph Clustering (VGMGC). Specifically, a novel variational graph generator is proposed to infer a reliable variational consensus graph based on a priori assumption over multiple graphs. Then a simple yet effective graph encoder in conjunction with the multi-view clustering objective is presented to learn the desired graph embeddings for clustering, which embeds the consensus and view-specific graphs together with features. Finally, theoretical results illustrate the rationality of VGMGC by analyzing the uncertainty of the inferred consensus graph with information bottleneck principle. Extensive experiments demonstrate the superior performance of our VGMGC over SOTAs.
Graph Attention Networks with LSTM-based Path Reweighting
Jun 21, 2021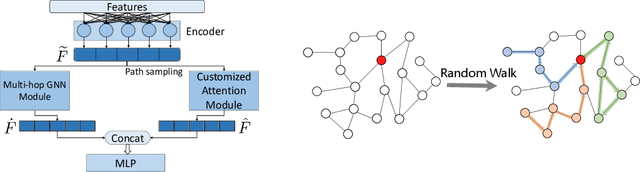


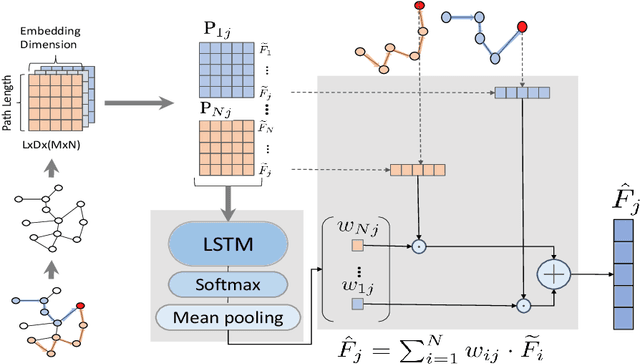
Graph Neural Networks (GNNs) have been extensively used for mining graph-structured data with impressive performance. However, traditional GNNs suffer from over-smoothing, non-robustness and over-fitting problems. To solve these weaknesses, we design a novel GNN solution, namely Graph Attention Network with LSTM-based Path Reweighting (PR-GAT). PR-GAT can automatically aggregate multi-hop information, highlight important paths and filter out noises. In addition, we utilize random path sampling in PR-GAT for data augmentation. The augmented data is used for predicting the distribution of corresponding labels. Finally, we demonstrate that PR-GAT can mitigate the issues of over-smoothing, non-robustness and overfitting. We achieve state-of-the-art accuracy on 5 out of 7 datasets and competitive accuracy for other 2 datasets. The average accuracy of 7 datasets have been improved by 0.5\% than the best SOTA from literature.