 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoherence-guided Preference Disentanglement for Cross-domain Recommendations
Oct 27, 2024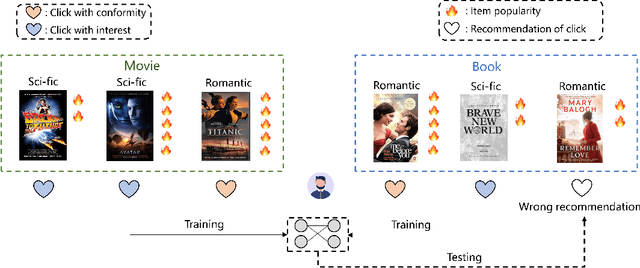

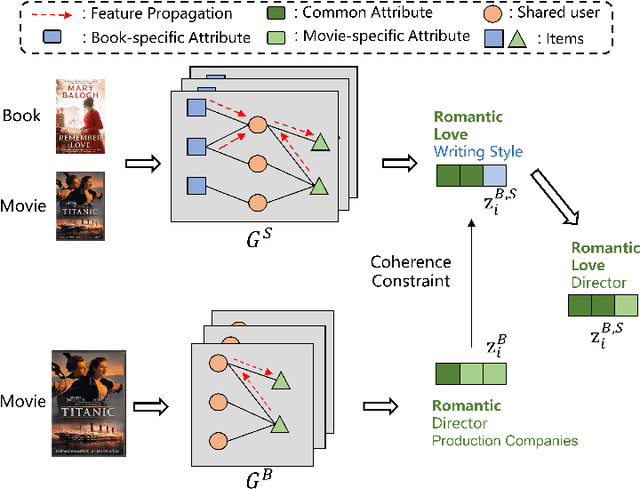
Discovering user preferences across different domains is pivotal in cross-domain recommendation systems, particularly when platforms lack comprehensive user-item interactive data. The limited presence of shared users often hampers the effective modeling of common preferences. While leveraging shared items' attributes, such as category and popularity, can enhance cross-domain recommendation performance, the scarcity of shared items between domains has limited research in this area. To address this, we propose a Coherence-guided Preference Disentanglement (CoPD) method aimed at improving cross-domain recommendation by i) explicitly extracting shared item attributes to guide the learning of shared user preferences and ii) disentangling these preferences to identify specific user interests transferred between domains. CoPD introduces coherence constraints on item embeddings of shared and specific domains, aiding in extracting shared attributes. Moreover, it utilizes these attributes to guide the disentanglement of user preferences into separate embeddings for interest and conformity through a popularity-weighted loss. Experiments conducted on real-world datasets demonstrate the superior performance of our proposed CoPD over existing competitive baselines, highlighting its effectiveness in enhancing cross-domain recommendation performance.
Graph Attention Networks with LSTM-based Path Reweighting
Jun 21, 2021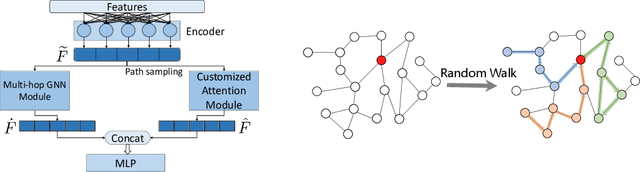


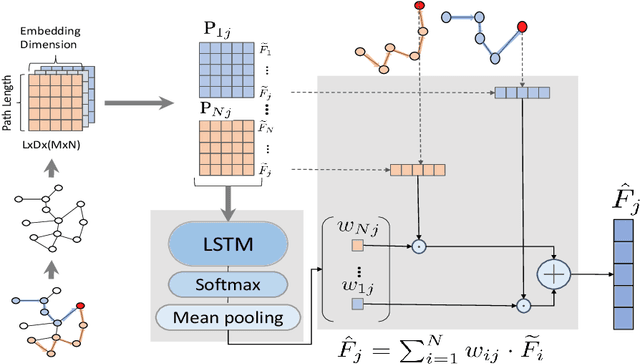
Graph Neural Networks (GNNs) have been extensively used for mining graph-structured data with impressive performance. However, traditional GNNs suffer from over-smoothing, non-robustness and over-fitting problems. To solve these weaknesses, we design a novel GNN solution, namely Graph Attention Network with LSTM-based Path Reweighting (PR-GAT). PR-GAT can automatically aggregate multi-hop information, highlight important paths and filter out noises. In addition, we utilize random path sampling in PR-GAT for data augmentation. The augmented data is used for predicting the distribution of corresponding labels. Finally, we demonstrate that PR-GAT can mitigate the issues of over-smoothing, non-robustness and overfitting. We achieve state-of-the-art accuracy on 5 out of 7 datasets and competitive accuracy for other 2 datasets. The average accuracy of 7 datasets have been improved by 0.5\% than the best SOTA from literature.