 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOVA: A Verification-Aware Agent Harness for Architecture Evolution in Industrial Recommender Systems
Jun 25, 2026Industrial advertising recommender models are continuously improved through architecture evolution. Upgrades such as RankMixer, TokenMixer-Large, and MixFormer show that better structures remain a key source of quality and business gains. Yet developing such upgrades in production is expert-intensive and difficult to scale. Existing automation is insufficient: AutoML mainly tunes hyper-parameters, while effective gains often require cross-module changes under strict constraints; generic LLM coding agents optimize for runnable code, but runnable code does not imply a valid recommender architecture. Candidates may pass local tests while causing silent failures that degrade performance. We present NOVA, a level-aware agent harness for verification-aware architecture evolution. NOVA uses an architecture gradient, an SGD-inspired, non-differentiable update signal that aggregates prior modifications, verification diagnostics, metric feedback, and trajectory memory to guide the next modification. A verification cascade checks structure semantics, local executability, offline effectiveness, and online impact; invalid candidates are blocked early, with failure patterns recorded as forbidden directions. L1--L4 task-level control matches automation to task complexity and risk, routing high-risk tasks to Copilot for human oversight. Deployed in an industrial advertising system, NOVA achieves the highest effective pass rate on L2 ScaleUp and L3 Literature-to-Production tasks (54.5% and 60.0%), reduces silent failures compared with coding-agent baselines, and shortens one literature-to-production cycle by over 13x in human-attended time. In online A/B testing, the selected L3 candidate improves GMV on three pCVR objectives by +1.25%, +1.70%, and +2.02%, while reducing pCVR bias by 58.8%, 66.7%, and 37.3%.
Expand More, Shrink Less: Shaping Effective-Rank Dynamics for Dense Scaling in Recommendation
May 22, 2026Scaling recommendation models is a central challenge in recommender systems. Recently, RankMixer has emerged as an effective solution, operating on a unified token representation and alternating between token mixing and per-token feedforward networks (P-FFNs) to achieve scalable performance. However, RankMixer suffers from \textit{embedding collapse}, where learned representations have low effective rank, limiting expressivity and underutilizing the expanded representation space. Through empirical analysis and theoretical insights, we identify rigid token mixing and P-FFN modules as the primary causes of this phenomenon, jointly inducing a \textbf{damped oscillatory trajectory} in effective-rank evolution across layers. To address it, we propose RankElastor, a novel architecture that produces spectrum-robust representations with provable collapse mitigation. RankElastor introduces two components: (i) \textbf{parameterized full mixing}, which enables expressive token mixing with improved spectral robustness; and (ii) \textbf{GLU-improved P-FFNs}, which stabilize representation spectra through GLU-style FFN modules. Extensive experiments on large-scale industrial datasets demonstrate that RankElastor consistently improves recommendation performance, mitigates embedding collapse, and exhibits robust scaling behavior. Code is available at this GitHub repository: https://github.com/vasile-paskardlgm/RankElastor
Asymmetric Generative Recommendation via Multi-Expert Projection and Multi-Faceted Hierarchical Quantization
May 14, 2026Generative Recommendation (GenRec) models reformulate recommendation as a sequence generation task, representing items as discrete Semantic IDs used symmetrically as both inputs and prediction targets. We identify a critical dual-stage information bottleneck in this design: (1) the Input Bottleneck, where lossy quantization degrades fine-grained semantics, while popularity bias skews the learned representations toward frequent items, and (2) the Output Bottleneck, where imprecise discrete targets limit supervision quality. To address these issues, we propose AsymRec, an asymmetric continuous-discrete framework that decouples input and output representations. Specifically, Multi-expert Semantic Projection (MSP) maps continuous embeddings into the Transformer's hidden space via expert-specialized projections, preserving semantic richness and improving generalization to infrequent items. Multi-faceted Hierarchical Quantization (MHQ) constructs high-capacity, structured discrete targets through multi-view and multi-level quantization with semantic regularization, preventing dimensional collapse while retaining fine-grained distinctions. Extensive experiments demonstrate that AsymRec consistently outperforms state-of-the-art generative recommenders by an average of 15.8 %. The code will be released.
RankUp: Towards High-rank Representations for Large Scale Advertising Recommender Systems
Apr 21, 2026The scaling laws for recommender systems have been increasingly validated, where MetaFormer-based architectures consistently benefit from increased model depth, hidden dimensionality, and user behavior sequence length. However, whether representation capacity scales proportionally with parameter growth remains largely unexplored. Prior studies on RankMixer reveal that the effective rank of token representations exhibits a damped oscillatory trajectory across layers, failing to increase consistently with depth and even degrading in deeper layers. Motivated by this observation, we propose \textbf{RankUp}, an architecture designed to mitigate representation collapse and enhance expressive capacity through randomized permutation splitting over sparse features, a multi-embedding paradigm, global token integration, crossed pretrained embedding tokens and task-specific token decoupling. RankUp has been fully deployed in large-scale production across Weixin Video Accounts, Official Accounts and Moments, yielding GMV improvements of 3.41\%, 4.81\% and 2.21\%, respectively.
TokenFormer: Unify the Multi-Field and Sequential Recommendation Worlds
Apr 15, 2026Recommender systems have historically developed along two largely independent paradigms: feature interaction models for modeling correlations among multi-field categorical features, and sequential models for capturing user behavior dynamics from historical interaction sequences. Although recent trends attempt to bridge these paradigms within shared backbones, we empirically reveal that naive unifying these two branches may lead to a failure mode of Sequential Collapse Propagation (SCP). That is, the interaction with those dimensionally ill non-sequence fields leads to the dimensional collapse of the sequence features. To overcome this challenge, we propose TokenFormer, a unified recommendation architecture with the following innovations. First, we introduce a Bottom-Full-Top-Sliding (BFTS) attention scheme, which applies full self-attention in the lower layers and shrinking-window sliding attention in the upper layers. Second, we introduce a Non-Linear Interaction Representation (NLIR) that applies one-sided non-linear multiplicative transformations to the hidden states. Extensive experiments on public benchmarks and Tencent's advertising platform demonstrate state-of-the-art performance, while detailed analysis confirm that TokenFormer significantly improves dimensional robustness and representation discriminability under unified modeling.
Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation
Apr 04, 2026Generative recommender systems are rapidly emerging as a new paradigm for recommendation, where collaborative identifiers and/or multi-modal content are mapped into discrete token spaces and user behavior is modelled with autoregressive sequence models. Despite progress on multi-modal recommendation datasets, there is still a lack of public benchmarks that jointly offer large-scale, realistic and fully all-modality data designed specifically for generative recommendation (GR) in industrial advertising. To foster research in this direction, we organised the Tencent Advertising Algorithm Challenge 2025, a global competition built on top of two all-modality datasets for GR: TencentGR-1M and TencentGR-10M. Both datasets are constructed from real de-identified Tencent Ads logs and contain rich collaborative IDs and multi-modal representations extracted with state-of-the-art embedding models. The preliminary track (TencentGR-1M) provides 1 million user sequences with up to 100 interacted items each, where each interaction is labeled with exposure and click signals, while the final track (TencentGR-10M) scales this to 10 million users and explicitly distinguishes between click and conversion events at both the sequence and target level. This paper presents the task definition, data construction process, feature schema, baseline GR model, evaluation protocol, and key findings from top-ranked and award-winning solutions. Our datasets focus on multi-modal sequence generation in an advertising setting and introduce weighted evaluation for high-value conversion events. We release our datasets at https://huggingface.co/datasets/TAAC2025 and baseline implementations at https://github.com/TencentAdvertisingAlgorithmCompetition/baseline_2025 to enable future research on all-modality generative recommendation at an industrial scale. The official website is https://algo.qq.com/2025.
PCSR: Pseudo-label Consistency-Guided Sample Refinement for Noisy Correspondence Learning
Sep 19, 2025Cross-modal retrieval aims to align different modalities via semantic similarity. However, existing methods often assume that image-text pairs are perfectly aligned, overlooking Noisy Correspondences in real data. These misaligned pairs misguide similarity learning and degrade retrieval performance. Previous methods often rely on coarse-grained categorizations that simply divide data into clean and noisy samples, overlooking the intrinsic diversity within noisy instances. Moreover, they typically apply uniform training strategies regardless of sample characteristics, resulting in suboptimal sample utilization for model optimization. To address the above challenges, we introduce a novel framework, called Pseudo-label Consistency-Guided Sample Refinement (PCSR), which enhances correspondence reliability by explicitly dividing samples based on pseudo-label consistency. Specifically, we first employ a confidence-based estimation to distinguish clean and noisy pairs, then refine the noisy pairs via pseudo-label consistency to uncover structurally distinct subsets. We further proposed a Pseudo-label Consistency Score (PCS) to quantify prediction stability, enabling the separation of ambiguous and refinable samples within noisy pairs. Accordingly, we adopt Adaptive Pair Optimization (APO), where ambiguous samples are optimized with robust loss functions and refinable ones are enhanced via text replacement during training. Extensive experiments on CC152K, MS-COCO and Flickr30K validate the effectiveness of our method in improving retrieval robustness under noisy supervision.
Large Foundation Model for Ads Recommendation
Aug 20, 2025


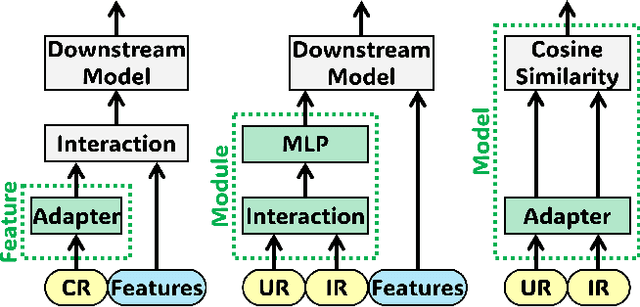
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
Dual Prompt Learning for Adapting Vision-Language Models to Downstream Image-Text Retrieval
Aug 06, 2025
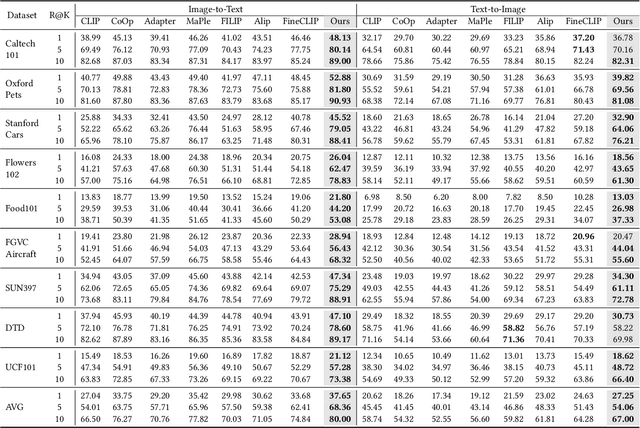
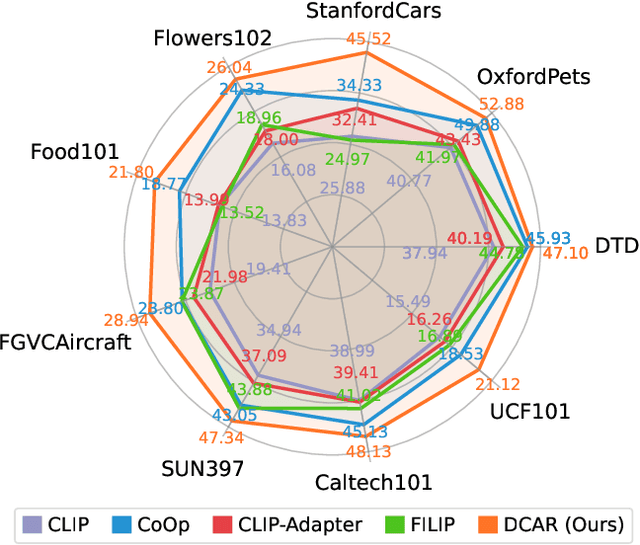
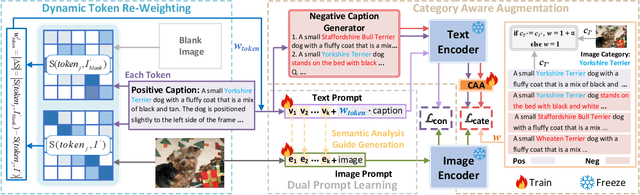
Recently, prompt learning has demonstrated remarkable success in adapting pre-trained Vision-Language Models (VLMs) to various downstream tasks such as image classification. However, its application to the downstream Image-Text Retrieval (ITR) task is more challenging. We find that the challenge lies in discriminating both fine-grained attributes and similar subcategories of the downstream data. To address this challenge, we propose Dual prompt Learning with Joint Category-Attribute Reweighting (DCAR), a novel dual-prompt learning framework to achieve precise image-text matching. The framework dynamically adjusts prompt vectors from both semantic and visual dimensions to improve the performance of CLIP on the downstream ITR task. Based on the prompt paradigm, DCAR jointly optimizes attribute and class features to enhance fine-grained representation learning. Specifically, (1) at the attribute level, it dynamically updates the weights of attribute descriptions based on text-image mutual information correlation; (2) at the category level, it introduces negative samples from multiple perspectives with category-matching weighting to learn subcategory distinctions. To validate our method, we construct the Fine-class Described Retrieval Dataset (FDRD), which serves as a challenging benchmark for ITR in downstream data domains. It covers over 1,500 downstream fine categories and 230,000 image-caption pairs with detailed attribute annotations. Extensive experiments on FDRD demonstrate that DCAR achieves state-of-the-art performance over existing baselines.
Aligning Information Capacity Between Vision and Language via Dense-to-Sparse Feature Distillation for Image-Text Matching
Mar 19, 2025Enabling Visual Semantic Models to effectively handle multi-view description matching has been a longstanding challenge. Existing methods typically learn a set of embeddings to find the optimal match for each view's text and compute similarity. However, the visual and text embeddings learned through these approaches have limited information capacity and are prone to interference from locally similar negative samples. To address this issue, we argue that the information capacity of embeddings is crucial and propose Dense-to-Sparse Feature Distilled Visual Semantic Embedding (D2S-VSE), which enhances the information capacity of sparse text by leveraging dense text distillation. Specifically, D2S-VSE is a two-stage framework. In the pre-training stage, we align images with dense text to enhance the information capacity of visual semantic embeddings. In the fine-tuning stage, we optimize two tasks simultaneously, distilling dense text embeddings to sparse text embeddings while aligning images and sparse texts, enhancing the information capacity of sparse text embeddings. Our proposed D2S-VSE model is extensively evaluated on the large-scale MS-COCO and Flickr30K datasets, demonstrating its superiority over recent state-of-the-art methods.