 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Feature Interaction to Feature Generation: A Generative Paradigm of CTR Prediction Models
Dec 16, 2025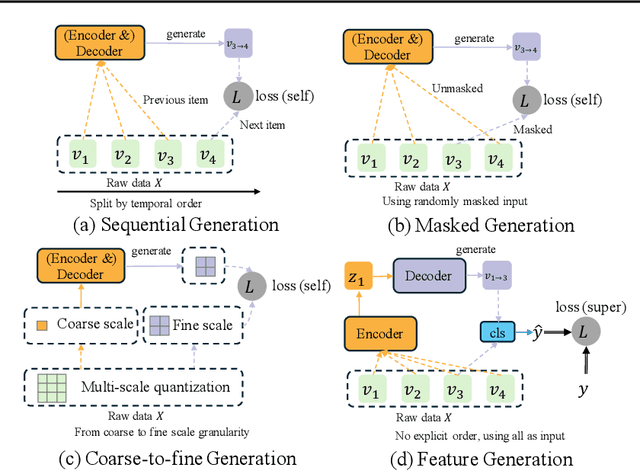
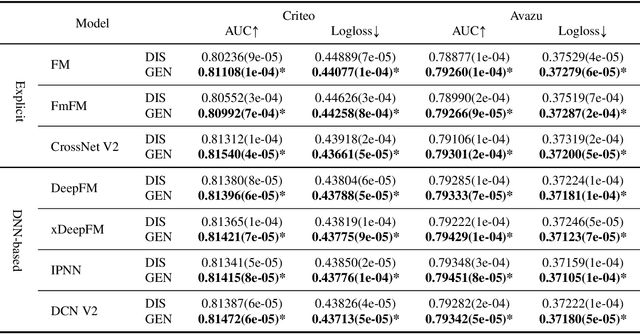
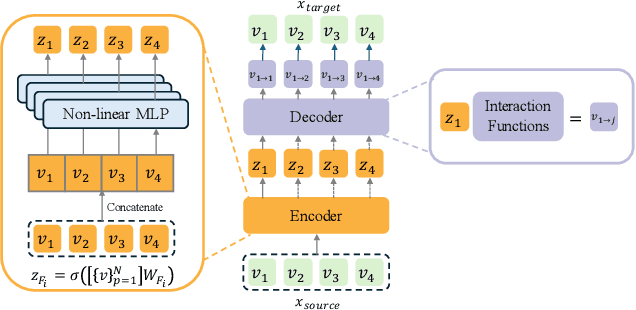
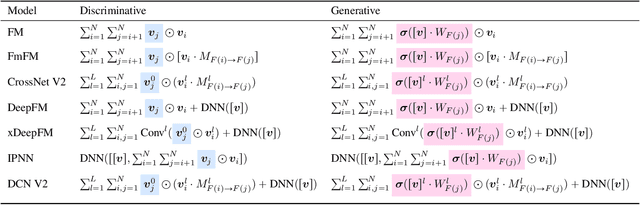
Click-Through Rate (CTR) prediction, a core task in recommendation systems, aims to estimate the probability of users clicking on items. Existing models predominantly follow a discriminative paradigm, which relies heavily on explicit interactions between raw ID embeddings. However, this paradigm inherently renders them susceptible to two critical issues: embedding dimensional collapse and information redundancy, stemming from the over-reliance on feature interactions \emph{over raw ID embeddings}. To address these limitations, we propose a novel \emph{Supervised Feature Generation (SFG)} framework, \emph{shifting the paradigm from discriminative ``feature interaction" to generative ``feature generation"}. Specifically, SFG comprises two key components: an \emph{Encoder} that constructs hidden embeddings for each feature, and a \emph{Decoder} tasked with regenerating the feature embeddings of all features from these hidden representations. Unlike existing generative approaches that adopt self-supervised losses, we introduce a supervised loss to utilize the supervised signal, \ie, click or not, in the CTR prediction task. This framework exhibits strong generalizability: it can be seamlessly integrated with most existing CTR models, reformulating them under the generative paradigm. Extensive experiments demonstrate that SFG consistently mitigates embedding collapse and reduces information redundancy, while yielding substantial performance gains across various datasets and base models. The code is available at https://github.com/USTC-StarTeam/GE4Rec.
Enhancing CTR Prediction with De-correlated Expert Networks
May 23, 2025Modeling feature interactions is essential for accurate click-through rate (CTR) prediction in advertising systems. Recent studies have adopted the Mixture-of-Experts (MoE) approach to improve performance by ensembling multiple feature interaction experts. These studies employ various strategies, such as learning independent embedding tables for each expert or utilizing heterogeneous expert architectures, to differentiate the experts, which we refer to expert \emph{de-correlation}. However, it remains unclear whether these strategies effectively achieve de-correlated experts. To address this, we propose a De-Correlated MoE (D-MoE) framework, which introduces a Cross-Expert De-Correlation loss to minimize expert correlations.Additionally, we propose a novel metric, termed Cross-Expert Correlation, to quantitatively evaluate the expert de-correlation degree. Based on this metric, we identify a key finding for MoE framework design: \emph{different de-correlation strategies are mutually compatible, and progressively employing them leads to reduced correlation and enhanced performance}.Extensive experiments have been conducted to validate the effectiveness of D-MoE and the de-correlation principle. Moreover, online A/B testing on Tencent's advertising platforms demonstrates that D-MoE achieves a significant 1.19\% Gross Merchandise Volume (GMV) lift compared to the Multi-Embedding MoE baseline.
Long-Sequence Recommendation Models Need Decoupled Embeddings
Oct 03, 2024



Lifelong user behavior sequences, comprising up to tens of thousands of history behaviors, are crucial for capturing user interests and predicting user responses in modern recommendation systems. A two-stage paradigm is typically adopted to handle these long sequences: a few relevant behaviors are first searched from the original long sequences via an attention mechanism in the first stage and then aggregated with the target item to construct a discriminative representation for prediction in the second stage. In this work, we identify and characterize, for the first time, a neglected deficiency in existing long-sequence recommendation models: a single set of embeddings struggles with learning both attention and representation, leading to interference between these two processes. Initial attempts to address this issue using linear projections -- a technique borrowed from language processing -- proved ineffective, shedding light on the unique challenges of recommendation models. To overcome this, we propose the Decoupled Attention and Representation Embeddings (DARE) model, where two distinct embedding tables are initialized and learned separately to fully decouple attention and representation. Extensive experiments and analysis demonstrate that DARE provides more accurate search of correlated behaviors and outperforms baselines with AUC gains up to 0.9% on public datasets and notable online system improvements. Furthermore, decoupling embedding spaces allows us to reduce the attention embedding dimension and accelerate the search procedure by 50% without significant performance impact, enabling more efficient, high-performance online serving.
Disentangled Representation with Cross Experts Covariance Loss for Multi-Domain Recommendation
May 21, 2024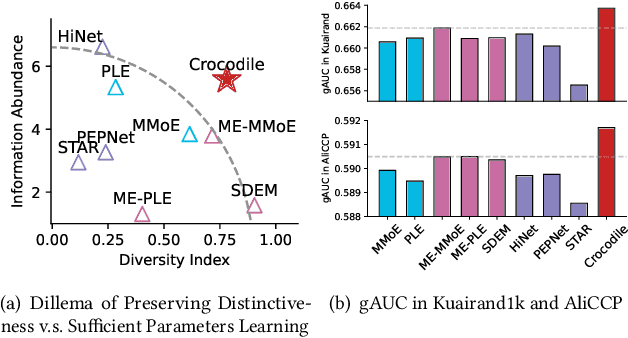

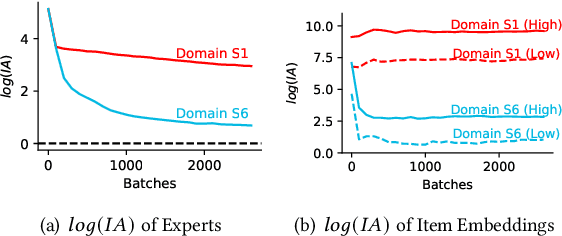
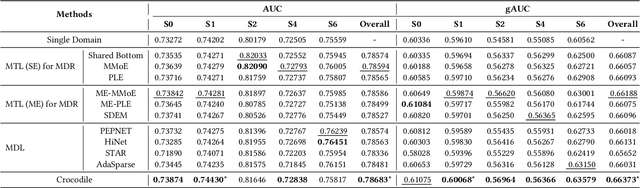
Multi-domain learning (MDL) has emerged as a prominent research area aimed at enhancing the quality of personalized services. The key challenge in MDL lies in striking a balance between learning commonalities across domains while preserving the distinct characteristics of each domain. However, this gives rise to a challenging dilemma. On one hand, a model needs to leverage domain-specific modules, such as experts or embeddings, to preserve the uniqueness of each domain. On the other hand, due to the long-tailed distributions observed in real-world domains, some tail domains may lack sufficient samples to fully learn their corresponding modules. Unfortunately, existing approaches have not adequately addressed this dilemma. To address this issue, we propose a novel model called Crocodile, which stands for Cross-experts Covariance Loss for Disentangled Learning. Crocodile adopts a multi-embedding paradigm to facilitate model learning and employs a Covariance Loss on these embeddings to disentangle them. This disentanglement enables the model to capture diverse user interests across domains effectively. Additionally, we introduce a novel gating mechanism to further enhance the capabilities of Crocodile. Through empirical analysis, we demonstrate that our proposed method successfully resolves these two challenges and outperforms all state-of-the-art methods on publicly available datasets. We firmly believe that the analytical perspectives and design concept of disentanglement presented in our work can pave the way for future research in the field of MDL.
Understanding the Ranking Loss for Recommendation with Sparse User Feedback
Mar 21, 2024Click-through rate (CTR) prediction holds significant importance in the realm of online advertising. While many existing approaches treat it as a binary classification problem and utilize binary cross entropy (BCE) as the optimization objective, recent advancements have indicated that combining BCE loss with ranking loss yields substantial performance improvements. However, the full efficacy of this combination loss remains incompletely understood. In this paper, we uncover a new challenge associated with BCE loss in scenarios with sparse positive feedback, such as CTR prediction: the gradient vanishing for negative samples. Subsequently, we introduce a novel perspective on the effectiveness of ranking loss in CTR prediction, highlighting its ability to generate larger gradients on negative samples, thereby mitigating their optimization issues and resulting in improved classification ability. Our perspective is supported by extensive theoretical analysis and empirical evaluation conducted on publicly available datasets. Furthermore, we successfully deployed the ranking loss in Tencent's online advertising system, achieving notable lifts of 0.70% and 1.26% in Gross Merchandise Value (GMV) for two main scenarios. The code for our approach is openly accessible at the following GitHub repository: https://github.com/SkylerLinn/Understanding-the-Ranking-Loss.
Ad Recommendation in a Collapsed and Entangled World
Feb 22, 2024



In this paper, we present an industry ad recommendation system, paying attention to the challenges and practices of learning appropriate representations. Our study begins by showcasing our approaches to preserving priors when encoding features of diverse types into embedding representations. Specifically, we address sequence features, numeric features, pre-trained embedding features, as well as sparse ID features. Moreover, we delve into two pivotal challenges associated with feature representation: the dimensional collapse of embeddings and the interest entanglement across various tasks or scenarios. Subsequently, we propose several practical approaches to effectively tackle these two challenges. We then explore several training techniques to facilitate model optimization, reduce bias, and enhance exploration. Furthermore, we introduce three analysis tools that enable us to comprehensively study feature correlation, dimensional collapse, and interest entanglement. This work builds upon the continuous efforts of Tencent's ads recommendation team in the last decade. It not only summarizes general design principles but also presents a series of off-the-shelf solutions and analysis tools. The reported performance is based on our online advertising platform, which handles hundreds of billions of requests daily, serving millions of ads to billions of users.
On the Embedding Collapse when Scaling up Recommendation Models
Oct 06, 2023Recent advances in deep foundation models have led to a promising trend of developing large recommendation models to leverage vast amounts of available data. However, we experiment to scale up existing recommendation models and observe that the enlarged models do not improve satisfactorily. In this context, we investigate the embedding layers of enlarged models and identify a phenomenon of embedding collapse, which ultimately hinders scalability, wherein the embedding matrix tends to reside in a low-dimensional subspace. Through empirical and theoretical analysis, we demonstrate that the feature interaction module specific to recommendation models has a two-sided effect. On the one hand, the interaction restricts embedding learning when interacting with collapsed embeddings, exacerbating the collapse issue. On the other hand, feature interaction is crucial in mitigating the fitting of spurious features, thereby improving scalability. Based on this analysis, we propose a simple yet effective multi-embedding design incorporating embedding-set-specific interaction modules to capture diverse patterns and reduce collapse. Extensive experiments demonstrate that this proposed design provides consistent scalability for various recommendation models.
Decoupled Training: Return of Frustratingly Easy Multi-Domain Learning
Sep 19, 2023Multi-domain learning (MDL) aims to train a model with minimal average risk across multiple overlapping but non-identical domains. To tackle the challenges of dataset bias and domain domination, numerous MDL approaches have been proposed from the perspectives of seeking commonalities by aligning distributions to reduce domain gap or reserving differences by implementing domain-specific towers, gates, and even experts. MDL models are becoming more and more complex with sophisticated network architectures or loss functions, introducing extra parameters and enlarging computation costs. In this paper, we propose a frustratingly easy and hyperparameter-free multi-domain learning method named Decoupled Training(D-Train). D-Train is a tri-phase general-to-specific training strategy that first pre-trains on all domains to warm up a root model, then post-trains on each domain by splitting into multi heads, and finally fine-tunes the heads by fixing the backbone, enabling decouple training to achieve domain independence. Despite its extraordinary simplicity and efficiency, D-Train performs remarkably well in extensive evaluations of various datasets from standard benchmarks to applications of satellite imagery and recommender systems.
STEM: Unleashing the Power of Embeddings for Multi-task Recommendation
Aug 16, 2023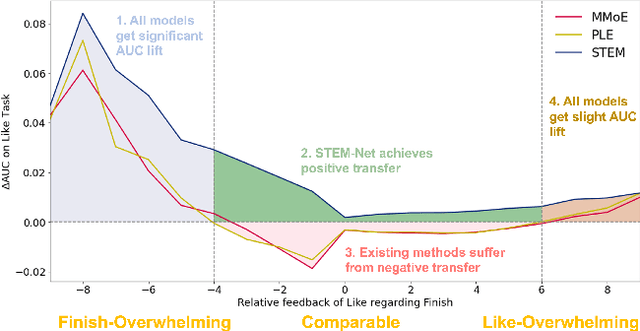

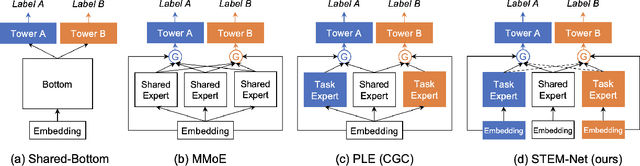
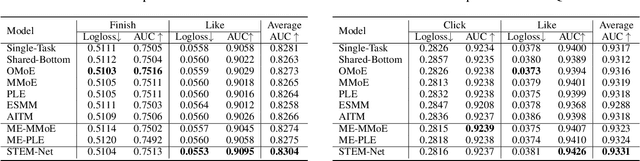
Multi-task learning (MTL) has gained significant popularity in recommendation systems as it enables the simultaneous optimization of multiple objectives. A key challenge in MTL is the occurrence of negative transfer, where the performance of certain tasks deteriorates due to conflicts between tasks. Existing research has explored negative transfer by treating all samples as a whole, overlooking the inherent complexities within them. To this end, we delve into the intricacies of samples by splitting them based on the relative amount of positive feedback among tasks. Surprisingly, negative transfer still occurs in existing MTL methods on samples that receive comparable feedback across tasks. It is worth noting that existing methods commonly employ a shared-embedding paradigm, and we hypothesize that their failure can be attributed to the limited capacity of modeling diverse user preferences across tasks using such universal embeddings. In this paper, we introduce a novel paradigm called Shared and Task-specific EMbeddings (STEM) that aims to incorporate both shared and task-specific embeddings to effectively capture task-specific user preferences. Under this paradigm, we propose a simple model STEM-Net, which is equipped with shared and task-specific embedding tables, along with a customized gating network with stop-gradient operations to facilitate the learning of these embeddings. Remarkably, STEM-Net demonstrates exceptional performance on comparable samples, surpassing the Single-Task Like model and achieves positive transfer. Comprehensive evaluation on three public MTL recommendation datasets demonstrates that STEM-Net outperforms state-of-the-art models by a substantial margin, providing evidence of its effectiveness and superiority.
CLIPood: Generalizing CLIP to Out-of-Distributions
Feb 02, 2023

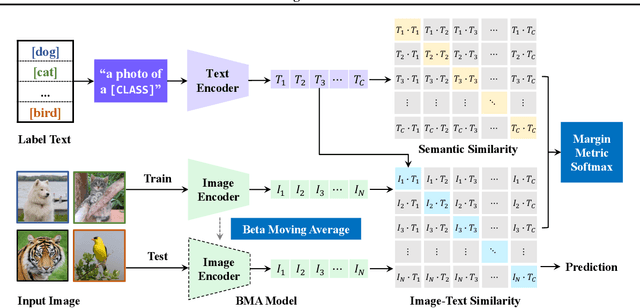

Out-of-distribution (OOD) generalization, where the model needs to handle distribution shifts from training, is a major challenge of machine learning. Recently, contrastive language-image pre-training (CLIP) models have shown impressive zero-shot ability, revealing a promising path toward OOD generalization. However, to boost upon zero-shot performance, further adaptation of CLIP on downstream tasks is indispensable but undesirably degrades OOD generalization ability. In this paper, we aim at generalizing CLIP to out-of-distribution test data on downstream tasks. Beyond the two canonical OOD situations, domain shift and open class, we tackle a more general but difficult in-the-wild setting where both OOD situations may occur on the unseen test data. We propose CLIPood, a simple fine-tuning method that can adapt CLIP models to all OOD situations. To exploit semantic relations between classes from the text modality, CLIPood introduces a new training objective, margin metric softmax (MMS), with class adaptive margins for fine-tuning. Moreover, to incorporate both the pre-trained zero-shot model and the fine-tuned task-adaptive model, CLIPood proposes a new Beta moving average (BMA) to maintain a temporal ensemble according to Beta distribution. Experiments on diverse datasets with different OOD scenarios show that CLIPood consistently outperforms existing generalization techniques.