 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEM: Unleashing the Power of Embeddings for Multi-task Recommendation
Aug 16, 2023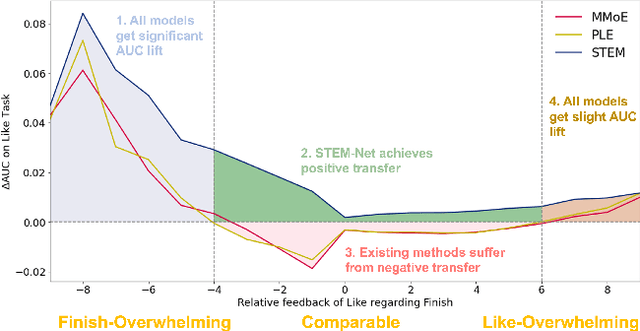

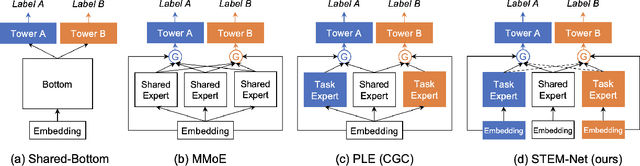
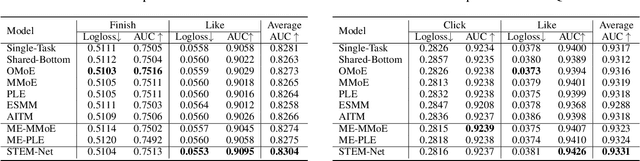
Multi-task learning (MTL) has gained significant popularity in recommendation systems as it enables the simultaneous optimization of multiple objectives. A key challenge in MTL is the occurrence of negative transfer, where the performance of certain tasks deteriorates due to conflicts between tasks. Existing research has explored negative transfer by treating all samples as a whole, overlooking the inherent complexities within them. To this end, we delve into the intricacies of samples by splitting them based on the relative amount of positive feedback among tasks. Surprisingly, negative transfer still occurs in existing MTL methods on samples that receive comparable feedback across tasks. It is worth noting that existing methods commonly employ a shared-embedding paradigm, and we hypothesize that their failure can be attributed to the limited capacity of modeling diverse user preferences across tasks using such universal embeddings. In this paper, we introduce a novel paradigm called Shared and Task-specific EMbeddings (STEM) that aims to incorporate both shared and task-specific embeddings to effectively capture task-specific user preferences. Under this paradigm, we propose a simple model STEM-Net, which is equipped with shared and task-specific embedding tables, along with a customized gating network with stop-gradient operations to facilitate the learning of these embeddings. Remarkably, STEM-Net demonstrates exceptional performance on comparable samples, surpassing the Single-Task Like model and achieves positive transfer. Comprehensive evaluation on three public MTL recommendation datasets demonstrates that STEM-Net outperforms state-of-the-art models by a substantial margin, providing evidence of its effectiveness and superiority.
Temporal Interest Network for Click-Through Rate Prediction
Aug 15, 2023



The history of user behaviors constitutes one of the most significant characteristics in predicting the click-through rate (CTR), owing to their strong semantic and temporal correlation with the target item. While the literature has individually examined each of these correlations, research has yet to analyze them in combination, that is, the quadruple correlation of (behavior semantics, target semantics, behavior temporal, and target temporal). The effect of this correlation on performance and the extent to which existing methods learn it remain unknown. To address this gap, we empirically measure the quadruple correlation and observe intuitive yet robust quadruple patterns. We measure the learned correlation of several representative user behavior methods, but to our surprise, none of them learn such a pattern, especially the temporal one. In this paper, we propose the Temporal Interest Network (TIN) to capture the quadruple semantic and temporal correlation between behaviors and the target. We achieve this by incorporating target-aware temporal encoding, in addition to semantic embedding, to represent behaviors and the target. Furthermore, we deploy target-aware attention, along with target-aware representation, to explicitly conduct the 4-way interaction. We performed comprehensive evaluations on the Amazon and Alibaba datasets. Our proposed TIN outperforms the best-performing baselines by 0.43\% and 0.29\% on two datasets, respectively. Comprehensive analysis and visualization show that TIN is indeed capable of learning the quadruple correlation effectively, while all existing methods fail to do so. We provide our implementation of TIN in Tensorflow.
AdaTask: A Task-aware Adaptive Learning Rate Approach to Multi-task Learning
Nov 28, 2022



Multi-task learning (MTL) models have demonstrated impressive results in computer vision, natural language processing, and recommender systems. Even though many approaches have been proposed, how well these approaches balance different tasks on each parameter still remains unclear. In this paper, we propose to measure the task dominance degree of a parameter by the total updates of each task on this parameter. Specifically, we compute the total updates by the exponentially decaying Average of the squared Updates (AU) on a parameter from the corresponding task.Based on this novel metric, we observe that many parameters in existing MTL methods, especially those in the higher shared layers, are still dominated by one or several tasks. The dominance of AU is mainly due to the dominance of accumulative gradients from one or several tasks. Motivated by this, we propose a Task-wise Adaptive learning rate approach, AdaTask in short, to separate the \emph{accumulative gradients} and hence the learning rate of each task for each parameter in adaptive learning rate approaches (e.g., AdaGrad, RMSProp, and Adam). Comprehensive experiments on computer vision and recommender system MTL datasets demonstrate that AdaTask significantly improves the performance of dominated tasks, resulting SOTA average task-wise performance. Analysis on both synthetic and real-world datasets shows AdaTask balance parameters in every shared layer well.