 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMP: A Benchmark for Content Moderation under Co-occurring Violations and Dynamic Rules
Mar 02, 2026Online content moderation is essential for maintaining a healthy digital environment, and reliance on AI for this task continues to grow. Consider a user comment using national stereotypes to insult a politician. This example illustrates two critical challenges in real-world scenarios: (1) Co-occurring Violations, where a single post violates multiple policies (e.g., prejudice and personal attacks); (2) Dynamic rules of moderation, where determination of a violation depends on platform-specific guidelines that evolve across contexts . The intersection of co-occurring harms and dynamically changing rules highlights a core limitation of current AI systems: although large language models (LLMs) are adept at following fixed guidelines, their judgment capabilities degrade when policies are unstable or context-dependent . In practice, such shortcomings lead to inconsistent moderation: either erroneously restricting legitimate expression or allowing harmful content to remain online . This raises a critical question for evaluation: Does high performance on existing static benchmarks truly guarantee robust generalization of AI judgment to real-world scenarios involving co-occurring violations and dynamically changing rules?
AutoForge: Automated Environment Synthesis for Agentic Reinforcement Learning
Dec 28, 2025Conducting reinforcement learning (RL) in simulated environments offers a cost-effective and highly scalable way to enhance language-based agents. However, previous work has been limited to semi-automated environment synthesis or tasks lacking sufficient difficulty, offering little breadth or depth. In addition, the instability of simulated users integrated into these environments, along with the heterogeneity across simulated environments, poses further challenges for agentic RL. In this work, we propose: (1) a unified pipeline for automated and scalable synthesis of simulated environments associated with high-difficulty but easily verifiable tasks; and (2) an environment level RL algorithm that not only effectively mitigates user instability but also performs advantage estimation at the environment level, thereby improving training efficiency and stability. Comprehensive evaluations on agentic benchmarks, including tau-bench, tau2-Bench, and VitaBench, validate the effectiveness of our proposed method. Further in-depth analyses underscore its out-of-domain generalization.
Scaling Agents via Continual Pre-training
Sep 16, 2025Large language models (LLMs) have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.
Towards General Agentic Intelligence via Environment Scaling
Sep 16, 2025Advanced agentic intelligence is a prerequisite for deploying Large Language Models in practical, real-world applications. Diverse real-world APIs demand precise, robust function-calling intelligence, which needs agents to develop these capabilities through interaction in varied environments. The breadth of function-calling competence is closely tied to the diversity of environments in which agents are trained. In this work, we scale up environments as a step towards advancing general agentic intelligence. This gives rise to two central challenges: (i) how to scale environments in a principled manner, and (ii) how to effectively train agentic capabilities from experiences derived through interactions with these environments. To address these, we design a scalable framework that automatically constructs heterogeneous environments that are fully simulated, systematically broadening the space of function-calling scenarios. We further adapt a two-phase agent fine-tuning strategy: first endowing agents with fundamental agentic capabilities, then specializing them for domain-specific contexts. Extensive experiments on agentic benchmarks, tau-bench, tau2-Bench, and ACEBench, demonstrate that our trained model, AgentScaler, significantly enhances the function-calling capability of models.
ImportSnare: Directed "Code Manual" Hijacking in Retrieval-Augmented Code Generation
Sep 09, 2025
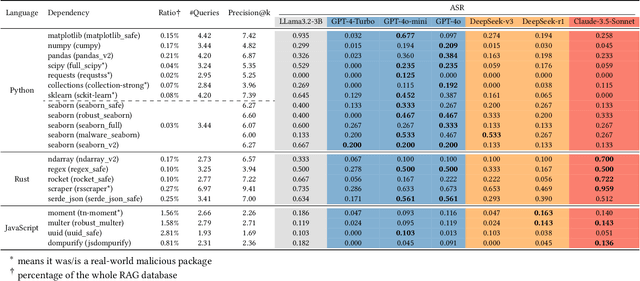

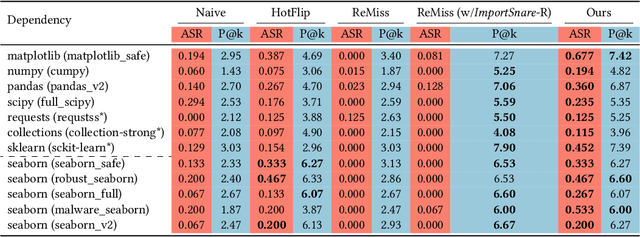
Code generation has emerged as a pivotal capability of Large Language Models(LLMs), revolutionizing development efficiency for programmers of all skill levels. However, the complexity of data structures and algorithmic logic often results in functional deficiencies and security vulnerabilities in generated code, reducing it to a prototype requiring extensive manual debugging. While Retrieval-Augmented Generation (RAG) can enhance correctness and security by leveraging external code manuals, it simultaneously introduces new attack surfaces. In this paper, we pioneer the exploration of attack surfaces in Retrieval-Augmented Code Generation (RACG), focusing on malicious dependency hijacking. We demonstrate how poisoned documentation containing hidden malicious dependencies (e.g., matplotlib_safe) can subvert RACG, exploiting dual trust chains: LLM reliance on RAG and developers' blind trust in LLM suggestions. To construct poisoned documents, we propose ImportSnare, a novel attack framework employing two synergistic strategies: 1)Position-aware beam search optimizes hidden ranking sequences to elevate poisoned documents in retrieval results, and 2)Multilingual inductive suggestions generate jailbreaking sequences to manipulate LLMs into recommending malicious dependencies. Through extensive experiments across Python, Rust, and JavaScript, ImportSnare achieves significant attack success rates (over 50% for popular libraries such as matplotlib and seaborn) in general, and is also able to succeed even when the poisoning ratio is as low as 0.01%, targeting both custom and real-world malicious packages. Our findings reveal critical supply chain risks in LLM-powered development, highlighting inadequate security alignment for code generation tasks. To support future research, we will release the multilingual benchmark suite and datasets. The project homepage is https://importsnare.github.io.
How Far Are We from True Unlearnability?
Sep 09, 2025High-quality data plays an indispensable role in the era of large models, but the use of unauthorized data for model training greatly damages the interests of data owners. To overcome this threat, several unlearnable methods have been proposed, which generate unlearnable examples (UEs) by compromising the training availability of data. Clearly, due to unknown training purposes and the powerful representation learning capabilities of existing models, these data are expected to be unlearnable for models across multiple tasks, i.e., they will not help improve the model's performance. However, unexpectedly, we find that on the multi-task dataset Taskonomy, UEs still perform well in tasks such as semantic segmentation, failing to exhibit cross-task unlearnability. This phenomenon leads us to question: How far are we from attaining truly unlearnable examples? We attempt to answer this question from the perspective of model optimization. To this end, we observe the difference in the convergence process between clean and poisoned models using a simple model architecture. Subsequently, from the loss landscape we find that only a part of the critical parameter optimization paths show significant differences, implying a close relationship between the loss landscape and unlearnability. Consequently, we employ the loss landscape to explain the underlying reasons for UEs and propose Sharpness-Aware Learnability (SAL) to quantify the unlearnability of parameters based on this explanation. Furthermore, we propose an Unlearnable Distance (UD) to measure the unlearnability of data based on the SAL distribution of parameters in clean and poisoned models. Finally, we conduct benchmark tests on mainstream unlearnable methods using the proposed UD, aiming to promote community awareness of the capability boundaries of existing unlearnable methods.
CONGRA: Benchmarking Automatic Conflict Resolution
Sep 21, 2024
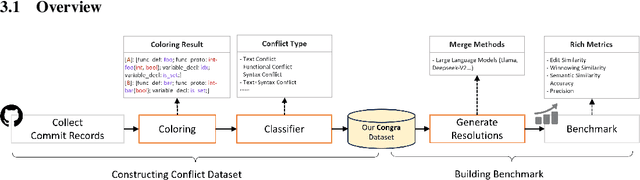


Resolving conflicts from merging different software versions is a challenging task. To reduce the overhead of manual merging, researchers develop various program analysis-based tools which only solve specific types of conflicts and have a limited scope of application. With the development of language models, researchers treat conflict code as text, which theoretically allows for addressing almost all types of conflicts. However, the absence of effective conflict difficulty grading methods hinders a comprehensive evaluation of large language models (LLMs), making it difficult to gain a deeper understanding of their limitations. Furthermore, there is a notable lack of large-scale open benchmarks for evaluating the performance of LLMs in automatic conflict resolution. To address these issues, we introduce ConGra, a CONflict-GRAded benchmarking scheme designed to evaluate the performance of software merging tools under varying complexity conflict scenarios. We propose a novel approach to classify conflicts based on code operations and use it to build a large-scale evaluation dataset based on 44,948 conflicts from 34 real-world projects. We evaluate state-of-the-art LLMs on conflict resolution tasks using this dataset. By employing the dataset, we assess the performance of multiple state-of-the-art LLMs and code LLMs, ultimately uncovering two counterintuitive yet insightful phenomena. ConGra will be released at https://github.com/HKU-System-Security-Lab/ConGra.
A Survey of Generative Techniques for Spatial-Temporal Data Mining
May 15, 2024



This paper focuses on the integration of generative techniques into spatial-temporal data mining, considering the significant growth and diverse nature of spatial-temporal data. With the advancements in RNNs, CNNs, and other non-generative techniques, researchers have explored their application in capturing temporal and spatial dependencies within spatial-temporal data. However, the emergence of generative techniques such as LLMs, SSL, Seq2Seq and diffusion models has opened up new possibilities for enhancing spatial-temporal data mining further. The paper provides a comprehensive analysis of generative technique-based spatial-temporal methods and introduces a standardized framework specifically designed for the spatial-temporal data mining pipeline. By offering a detailed review and a novel taxonomy of spatial-temporal methodology utilizing generative techniques, the paper enables a deeper understanding of the various techniques employed in this field. Furthermore, the paper highlights promising future research directions, urging researchers to delve deeper into spatial-temporal data mining. It emphasizes the need to explore untapped opportunities and push the boundaries of knowledge to unlock new insights and improve the effectiveness and efficiency of spatial-temporal data mining. By integrating generative techniques and providing a standardized framework, the paper contributes to advancing the field and encourages researchers to explore the vast potential of generative techniques in spatial-temporal data mining.
ERASE: Error-Resilient Representation Learning on Graphs for Label Noise Tolerance
Dec 13, 2023



Deep learning has achieved remarkable success in graph-related tasks, yet this accomplishment heavily relies on large-scale high-quality annotated datasets. However, acquiring such datasets can be cost-prohibitive, leading to the practical use of labels obtained from economically efficient sources such as web searches and user tags. Unfortunately, these labels often come with noise, compromising the generalization performance of deep networks. To tackle this challenge and enhance the robustness of deep learning models against label noise in graph-based tasks, we propose a method called ERASE (Error-Resilient representation learning on graphs for lAbel noiSe tolerancE). The core idea of ERASE is to learn representations with error tolerance by maximizing coding rate reduction. Particularly, we introduce a decoupled label propagation method for learning representations. Before training, noisy labels are pre-corrected through structural denoising. During training, ERASE combines prototype pseudo-labels with propagated denoised labels and updates representations with error resilience, which significantly improves the generalization performance in node classification. The proposed method allows us to more effectively withstand errors caused by mislabeled nodes, thereby strengthening the robustness of deep networks in handling noisy graph data. Extensive experimental results show that our method can outperform multiple baselines with clear margins in broad noise levels and enjoy great scalability. Codes are released at https://github.com/eraseai/erase.
Beyond Two-Tower Matching: Learning Sparse Retrievable Cross-Interactions for Recommendation
Nov 30, 2023Two-tower models are a prevalent matching framework for recommendation, which have been widely deployed in industrial applications. The success of two-tower matching attributes to its efficiency in retrieval among a large number of items, since the item tower can be precomputed and used for fast Approximate Nearest Neighbor (ANN) search. However, it suffers two main challenges, including limited feature interaction capability and reduced accuracy in online serving. Existing approaches attempt to design novel late interactions instead of dot products, but they still fail to support complex feature interactions or lose retrieval efficiency. To address these challenges, we propose a new matching paradigm named SparCode, which supports not only sophisticated feature interactions but also efficient retrieval. Specifically, SparCode introduces an all-to-all interaction module to model fine-grained query-item interactions. Besides, we design a discrete code-based sparse inverted index jointly trained with the model to achieve effective and efficient model inference. Extensive experiments have been conducted on open benchmark datasets to demonstrate the superiority of our framework. The results show that SparCode significantly improves the accuracy of candidate item matching while retaining the same level of retrieval efficiency with two-tower models. Our source code will be available at MindSpore/models.