 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXGuardian: Towards Explainable and Generalized AI Anti-Cheat on FPS Games
Jan 26, 2026Aim-assist cheats are the most prevalent and infamous form of cheating in First-Person Shooter (FPS) games, which help cheaters illegally reveal the opponent's location and auto-aim and shoot, and thereby pose significant threats to the game industry. Although a considerable research effort has been made to automatically detect aim-assist cheats, existing works suffer from unreliable frameworks, limited generalizability, high overhead, low detection performance, and a lack of explainability of detection results. In this paper, we propose XGuardian, a server-side generalized and explainable system for detecting aim-assist cheats to overcome these limitations. It requires only two raw data inputs, pitch and yaw, which are all FPS games' must-haves, to construct novel temporal features and describe aim trajectories, which are essential for distinguishing cheaters and normal players. XGuardian is evaluated with the latest mainstream FPS game CS2, and validates its generalizability with another two different games. It achieves high detection performance and low overhead compared to prior works across different games with real-world and large-scale datasets, demonstrating wide generalizability and high effectiveness. It is able to justify its predictions and thereby shorten the ban cycle. We make XGuardian as well as our datasets publicly available.
Scaling Agents via Continual Pre-training
Sep 16, 2025Large language models (LLMs) have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.
How Far Are We from True Unlearnability?
Sep 09, 2025High-quality data plays an indispensable role in the era of large models, but the use of unauthorized data for model training greatly damages the interests of data owners. To overcome this threat, several unlearnable methods have been proposed, which generate unlearnable examples (UEs) by compromising the training availability of data. Clearly, due to unknown training purposes and the powerful representation learning capabilities of existing models, these data are expected to be unlearnable for models across multiple tasks, i.e., they will not help improve the model's performance. However, unexpectedly, we find that on the multi-task dataset Taskonomy, UEs still perform well in tasks such as semantic segmentation, failing to exhibit cross-task unlearnability. This phenomenon leads us to question: How far are we from attaining truly unlearnable examples? We attempt to answer this question from the perspective of model optimization. To this end, we observe the difference in the convergence process between clean and poisoned models using a simple model architecture. Subsequently, from the loss landscape we find that only a part of the critical parameter optimization paths show significant differences, implying a close relationship between the loss landscape and unlearnability. Consequently, we employ the loss landscape to explain the underlying reasons for UEs and propose Sharpness-Aware Learnability (SAL) to quantify the unlearnability of parameters based on this explanation. Furthermore, we propose an Unlearnable Distance (UD) to measure the unlearnability of data based on the SAL distribution of parameters in clean and poisoned models. Finally, we conduct benchmark tests on mainstream unlearnable methods using the proposed UD, aiming to promote community awareness of the capability boundaries of existing unlearnable methods.
ImportSnare: Directed "Code Manual" Hijacking in Retrieval-Augmented Code Generation
Sep 09, 2025
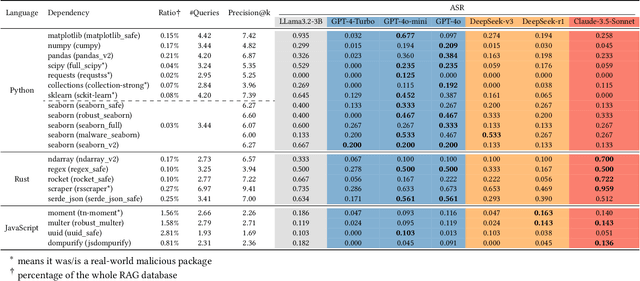

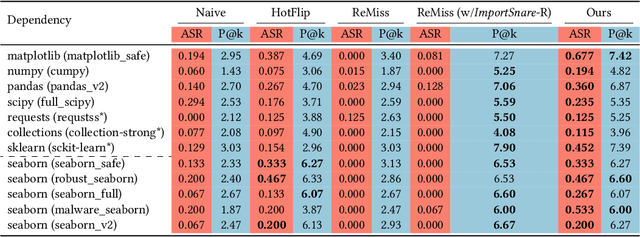
Code generation has emerged as a pivotal capability of Large Language Models(LLMs), revolutionizing development efficiency for programmers of all skill levels. However, the complexity of data structures and algorithmic logic often results in functional deficiencies and security vulnerabilities in generated code, reducing it to a prototype requiring extensive manual debugging. While Retrieval-Augmented Generation (RAG) can enhance correctness and security by leveraging external code manuals, it simultaneously introduces new attack surfaces. In this paper, we pioneer the exploration of attack surfaces in Retrieval-Augmented Code Generation (RACG), focusing on malicious dependency hijacking. We demonstrate how poisoned documentation containing hidden malicious dependencies (e.g., matplotlib_safe) can subvert RACG, exploiting dual trust chains: LLM reliance on RAG and developers' blind trust in LLM suggestions. To construct poisoned documents, we propose ImportSnare, a novel attack framework employing two synergistic strategies: 1)Position-aware beam search optimizes hidden ranking sequences to elevate poisoned documents in retrieval results, and 2)Multilingual inductive suggestions generate jailbreaking sequences to manipulate LLMs into recommending malicious dependencies. Through extensive experiments across Python, Rust, and JavaScript, ImportSnare achieves significant attack success rates (over 50% for popular libraries such as matplotlib and seaborn) in general, and is also able to succeed even when the poisoning ratio is as low as 0.01%, targeting both custom and real-world malicious packages. Our findings reveal critical supply chain risks in LLM-powered development, highlighting inadequate security alignment for code generation tasks. To support future research, we will release the multilingual benchmark suite and datasets. The project homepage is https://importsnare.github.io.
CONGRA: Benchmarking Automatic Conflict Resolution
Sep 21, 2024
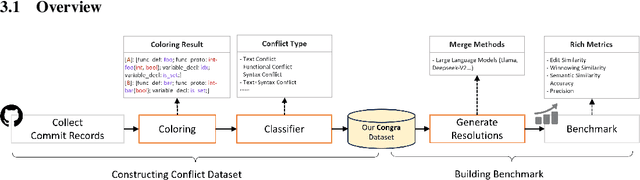


Resolving conflicts from merging different software versions is a challenging task. To reduce the overhead of manual merging, researchers develop various program analysis-based tools which only solve specific types of conflicts and have a limited scope of application. With the development of language models, researchers treat conflict code as text, which theoretically allows for addressing almost all types of conflicts. However, the absence of effective conflict difficulty grading methods hinders a comprehensive evaluation of large language models (LLMs), making it difficult to gain a deeper understanding of their limitations. Furthermore, there is a notable lack of large-scale open benchmarks for evaluating the performance of LLMs in automatic conflict resolution. To address these issues, we introduce ConGra, a CONflict-GRAded benchmarking scheme designed to evaluate the performance of software merging tools under varying complexity conflict scenarios. We propose a novel approach to classify conflicts based on code operations and use it to build a large-scale evaluation dataset based on 44,948 conflicts from 34 real-world projects. We evaluate state-of-the-art LLMs on conflict resolution tasks using this dataset. By employing the dataset, we assess the performance of multiple state-of-the-art LLMs and code LLMs, ultimately uncovering two counterintuitive yet insightful phenomena. ConGra will be released at https://github.com/HKU-System-Security-Lab/ConGra.