 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Knowledge-Action Gap by Evaluating LLMs in Dynamic Dental Clinical Scenarios
Jan 19, 2026The transition of Large Language Models (LLMs) from passive knowledge retrievers to autonomous clinical agents demands a shift in evaluation-from static accuracy to dynamic behavioral reliability. To explore this boundary in dentistry, a domain where high-quality AI advice uniquely empowers patient-participatory decision-making, we present the Standardized Clinical Management & Performance Evaluation (SCMPE) benchmark, which comprehensively assesses performance from knowledge-oriented evaluations (static objective tasks) to workflow-based simulations (multi-turn simulated patient interactions). Our analysis reveals that while models demonstrate high proficiency in static objective tasks, their performance precipitates in dynamic clinical dialogues, identifying that the primary bottleneck lies not in knowledge retention, but in the critical challenges of active information gathering and dynamic state tracking. Mapping "Guideline Adherence" versus "Decision Quality" reveals a prevalent "High Efficacy, Low Safety" risk in general models. Furthermore, we quantify the impact of Retrieval-Augmented Generation (RAG). While RAG mitigates hallucinations in static tasks, its efficacy in dynamic workflows is limited and heterogeneous, sometimes causing degradation. This underscores that external knowledge alone cannot bridge the reasoning gap without domain-adaptive pre-training. This study empirically charts the capability boundaries of dental LLMs, providing a roadmap for bridging the gap between standardized knowledge and safe, autonomous clinical practice.
SemanticNN: Compressive and Error-Resilient Semantic Offloading for Extremely Weak Devices
Nov 14, 2025With the rapid growth of the Internet of Things (IoT), integrating artificial intelligence (AI) on extremely weak embedded devices has garnered significant attention, enabling improved real-time performance and enhanced data privacy. However, the resource limitations of such devices and unreliable network conditions necessitate error-resilient device-edge collaboration systems. Traditional approaches focus on bit-level transmission correctness, which can be inefficient under dynamic channel conditions. In contrast, we propose SemanticNN, a semantic codec that tolerates bit-level errors in pursuit of semantic-level correctness, enabling compressive and resilient collaborative inference offloading under strict computational and communication constraints. It incorporates a Bit Error Rate (BER)-aware decoder that adapts to dynamic channel conditions and a Soft Quantization (SQ)-based encoder to learn compact representations. Building on this architecture, we introduce Feature-augmentation Learning, a novel training strategy that enhances offloading efficiency. To address encoder-decoder capability mismatches from asymmetric resources, we propose XAI-based Asymmetry Compensation to enhance decoding semantic fidelity. We conduct extensive experiments on STM32 using three models and six datasets across image classification and object detection tasks. Experimental results demonstrate that, under varying transmission error rates, SemanticNN significantly reduces feature transmission volume by 56.82-344.83x while maintaining superior inference accuracy.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Can Students Beyond The Teacher? Distilling Knowledge from Teacher's Bias
Dec 13, 2024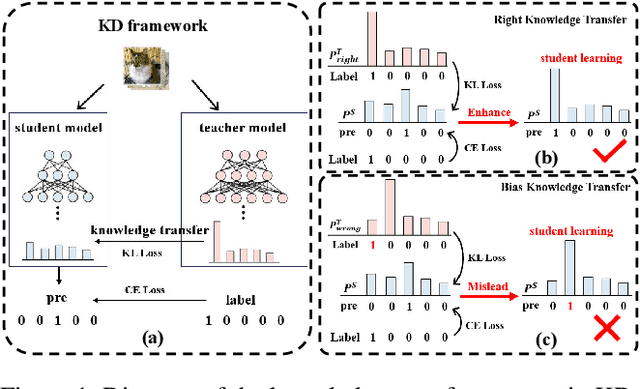
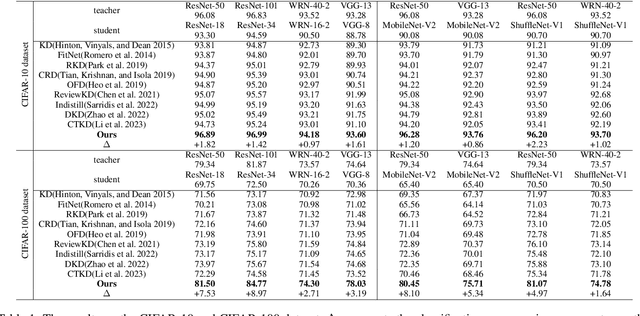
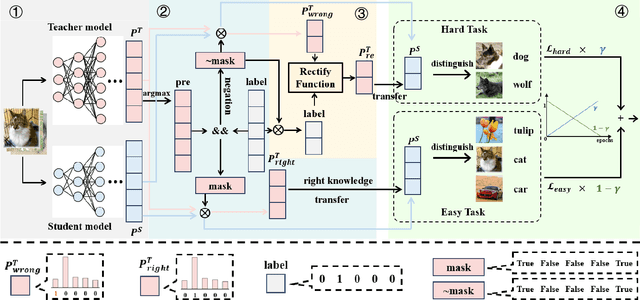
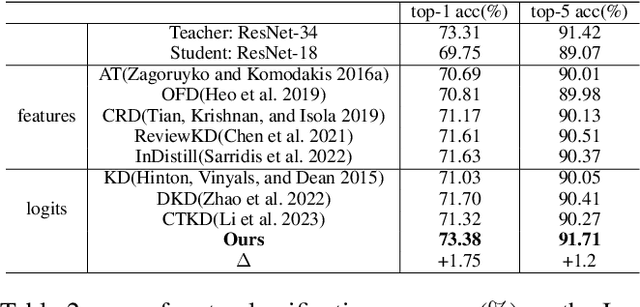
Knowledge distillation (KD) is a model compression technique that transfers knowledge from a large teacher model to a smaller student model to enhance its performance. Existing methods often assume that the student model is inherently inferior to the teacher model. However, we identify that the fundamental issue affecting student performance is the bias transferred by the teacher. Current KD frameworks transmit both right and wrong knowledge, introducing bias that misleads the student model. To address this issue, we propose a novel strategy to rectify bias and greatly improve the student model's performance. Our strategy involves three steps: First, we differentiate knowledge and design a bias elimination method to filter out biases, retaining only the right knowledge for the student model to learn. Next, we propose a bias rectification method to rectify the teacher model's wrong predictions, fundamentally addressing bias interference. The student model learns from both the right knowledge and the rectified biases, greatly improving its prediction accuracy. Additionally, we introduce a dynamic learning approach with a loss function that updates weights dynamically, allowing the student model to quickly learn right knowledge-based easy tasks initially and tackle hard tasks corresponding to biases later, greatly enhancing the student model's learning efficiency. To the best of our knowledge, this is the first strategy enabling the student model to surpass the teacher model. Experiments demonstrate that our strategy, as a plug-and-play module, is versatile across various mainstream KD frameworks. We will release our code after the paper is accepted.
Performance analysis for a rotary compressor at high speed: experimental study and mathematical modeling
Jul 13, 2024This paper conducted a comprehensive study on the performance of a rotary compressor over a rotational speed range of 80Hz to 200Hz through experimental tests and mathematical modeling. A compressor performance test rig was designed to conduct the performance tests, with fast-response pressure sensors and displacement sensors capturing the P-V diagram and dynamic motion of the moving components. Results show that the compressor efficiency degrades at high speeds due to the dominant loss factors of leakage and discharge power loss. Supercharging effects become significant at speeds above 160Hz, and its net effects reduce the compressor efficiency, especially at high speeds. This study identifies and analyzes the loss factors on the mass flow rate and power consumption based on experimental data, and hypothesizes possible mechanisms for each loss factor, which can aid in the design of a high-speed rotary compressor with higher efficiency.
AttenScribble: Attentive Similarity Learning for Scribble-Supervised Medical Image Segmentation
Dec 11, 2023The success of deep networks in medical image segmentation relies heavily on massive labeled training data. However, acquiring dense annotations is a time-consuming process. Weakly-supervised methods normally employ less expensive forms of supervision, among which scribbles started to gain popularity lately thanks to its flexibility. However, due to lack of shape and boundary information, it is extremely challenging to train a deep network on scribbles that generalizes on unlabeled pixels. In this paper, we present a straightforward yet effective scribble supervised learning framework. Inspired by recent advances of transformer based segmentation, we create a pluggable spatial self-attention module which could be attached on top of any internal feature layers of arbitrary fully convolutional network (FCN) backbone. The module infuses global interaction while keeping the efficiency of convolutions. Descended from this module, we construct a similarity metric based on normalized and symmetrized attention. This attentive similarity leads to a novel regularization loss that imposes consistency between segmentation prediction and visual affinity. This attentive similarity loss optimizes the alignment of FCN encoders, attention mapping and model prediction. Ultimately, the proposed FCN+Attention architecture can be trained end-to-end guided by a combination of three learning objectives: partial segmentation loss, a customized masked conditional random fields and the proposed attentive similarity loss. Extensive experiments on public datasets (ACDC and CHAOS) showed that our framework not just out-performs existing state-of-the-art, but also delivers close performance to fully-supervised benchmark. Code will be available upon publication.
A dynamic interactive learning framework for automated 3D medical image segmentation
Dec 11, 2023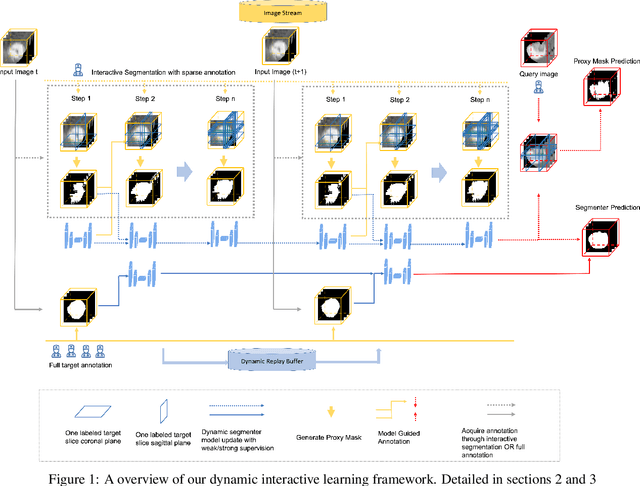
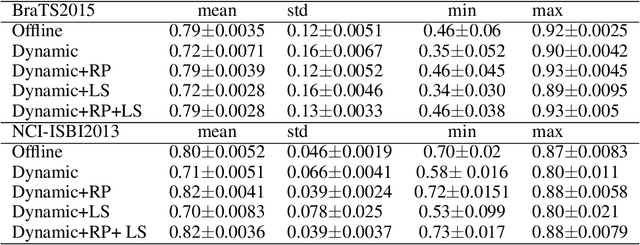
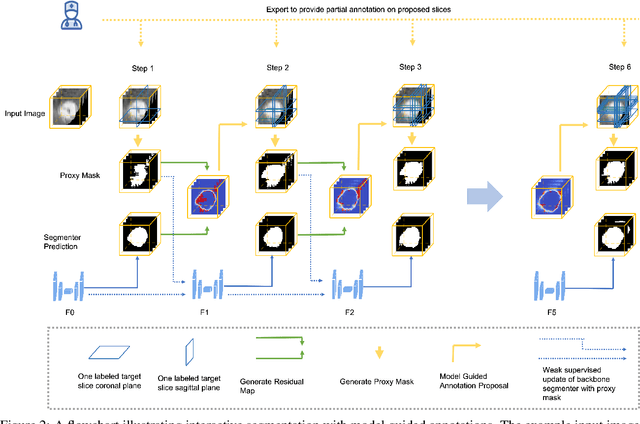
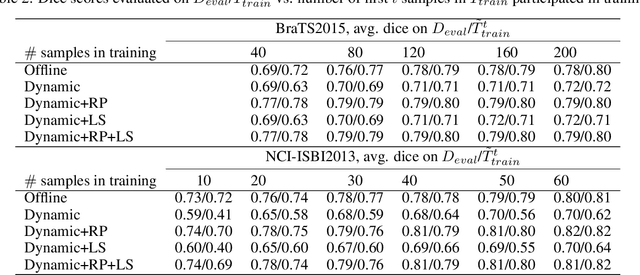
Many deep learning based automated medical image segmentation systems, in reality, face difficulties in deployment due to the cost of massive data annotation and high latency in model iteration. We propose a dynamic interactive learning framework that addresses these challenges by integrating interactive segmentation into end-to-end weak supervised learning with streaming tasks. We develop novel replay and label smoothing schemes that overcome catastrophic forgetting and improve online learning robustness. For each image, our multi-round interactive segmentation module simultaneously optimizes both front-end predictions and deep learning segmenter. In each round, a 3D "proxy mask" is propagated from sparse user inputs based on image registration, serving as weak supervision that enable knowledge distillation from the unknown ground truth. In return, the trained segmenter explicitly guides next step's user interventions according to a spatial residual map from consecutive front or back-end predictions. Evaluation on 3D segmentation tasks (NCI-ISBI2013 and BraTS2015) shows that our framework generates online learning performances that match offline training benchmark. In addition, with a 62% reduction in total annotation efforts, our framework produces competitive dice scores comparing to online and offline learning which equipped with full ground truth. Furthermore, such a framework, with its flexibility and responsiveness, could be deployed behind hospital firewall that guarantees data security and easy maintenance.
Analysis and Applications of Deep Learning with Finite Samples in Full Life-Cycle Intelligence of Nuclear Power Generation
Nov 07, 2023



The advent of Industry 4.0 has precipitated the incorporation of Artificial Intelligence (AI) methods within industrial contexts, aiming to realize intelligent manufacturing, operation as well as maintenance, also known as industrial intelligence. However, intricate industrial milieus, particularly those relating to energy exploration and production, frequently encompass data characterized by long-tailed class distribution, sample imbalance, and domain shift. These attributes pose noteworthy challenges to data-centric Deep Learning (DL) techniques, crucial for the realization of industrial intelligence. The present study centers on the intricate and distinctive industrial scenarios of Nuclear Power Generation (NPG), meticulously scrutinizing the application of DL techniques under the constraints of finite data samples. Initially, the paper expounds on potential employment scenarios for AI across the full life-cycle of NPG. Subsequently, we delve into an evaluative exposition of DL's advancement, grounded in the finite sample perspective. This encompasses aspects such as small-sample learning, few-shot learning, zero-shot learning, and open-set recognition, also referring to the unique data characteristics of NPG. The paper then proceeds to present two specific case studies. The first revolves around the automatic recognition of zirconium alloy metallography, while the second pertains to open-set recognition for signal diagnosis of machinery sensors. These cases, spanning the entirety of NPG's life-cycle, are accompanied by constructive outcomes and insightful deliberations. By exploring and applying DL methodologies within the constraints of finite sample availability, this paper not only furnishes a robust technical foundation but also introduces a fresh perspective toward the secure and efficient advancement and exploitation of this advanced energy source.
Edge Cloud Collaborative Stream Computing for Real-Time Structural Health Monitoring
Oct 11, 2023Structural Health Monitoring (SHM) is crucial for the safety and maintenance of various infrastructures. Due to the large amount of data generated by numerous sensors and the high real-time requirements of many applications, SHM poses significant challenges. Although the cloud-centric stream computing paradigm opens new opportunities for real-time data processing, it consumes too much network bandwidth. In this paper, we propose ECStream, an Edge Cloud collaborative fine-grained stream operator scheduling framework for SHM. We collectively consider atomic and composite operators together with their iterative computability to model and formalize the problem of minimizing bandwidth usage and end-to-end operator processing latency. Preliminary evaluation results show that ECStream can effectively balance bandwidth usage and end-to-end operator computation latency, reducing bandwidth usage by 73.01% and latency by 34.08% on average compared to the cloud-centric approach.
The Solution for the CVPR2023 NICE Image Captioning Challenge
Oct 10, 2023In this paper, we present our solution to the New frontiers for Zero-shot Image Captioning Challenge. Different from the traditional image captioning datasets, this challenge includes a larger new variety of visual concepts from many domains (such as COVID-19) as well as various image types (photographs, illustrations, graphics). For the data level, we collect external training data from Laion-5B, a large-scale CLIP-filtered image-text dataset. For the model level, we use OFA, a large-scale visual-language pre-training model based on handcrafted templates, to perform the image captioning task. In addition, we introduce contrastive learning to align image-text pairs to learn new visual concepts in the pre-training stage. Then, we propose a similarity-bucket strategy and incorporate this strategy into the template to force the model to generate higher quality and more matching captions. Finally, by retrieval-augmented strategy, we construct a content-rich template, containing the most relevant top-k captions from other image-text pairs, to guide the model in generating semantic-rich captions. Our method ranks first on the leaderboard, achieving 105.17 and 325.72 Cider-Score in the validation and test phase, respectively.