 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Students Beyond The Teacher? Distilling Knowledge from Teacher's Bias
Paper and Code
Dec 13, 2024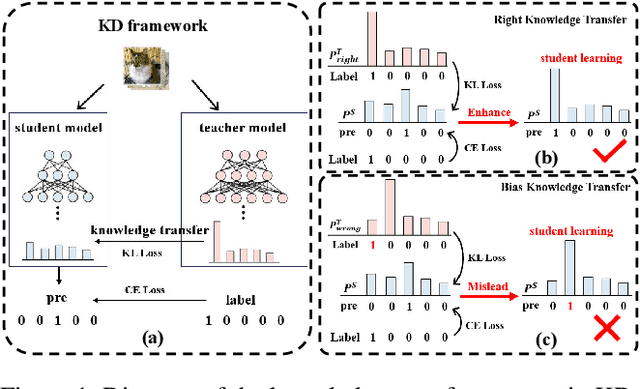
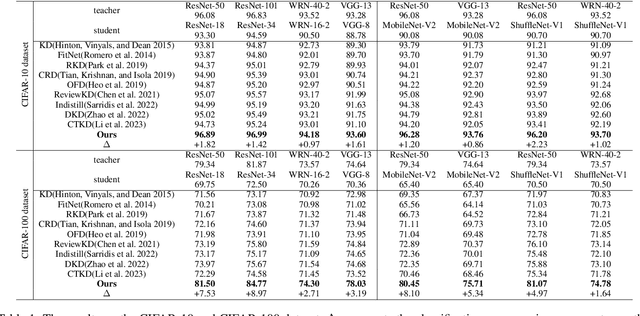
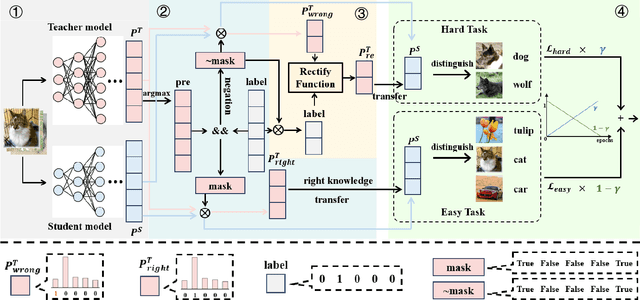
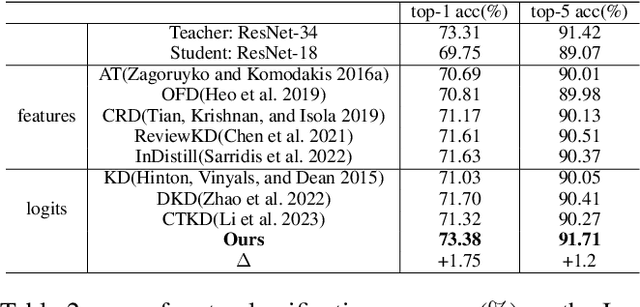
Knowledge distillation (KD) is a model compression technique that transfers knowledge from a large teacher model to a smaller student model to enhance its performance. Existing methods often assume that the student model is inherently inferior to the teacher model. However, we identify that the fundamental issue affecting student performance is the bias transferred by the teacher. Current KD frameworks transmit both right and wrong knowledge, introducing bias that misleads the student model. To address this issue, we propose a novel strategy to rectify bias and greatly improve the student model's performance. Our strategy involves three steps: First, we differentiate knowledge and design a bias elimination method to filter out biases, retaining only the right knowledge for the student model to learn. Next, we propose a bias rectification method to rectify the teacher model's wrong predictions, fundamentally addressing bias interference. The student model learns from both the right knowledge and the rectified biases, greatly improving its prediction accuracy. Additionally, we introduce a dynamic learning approach with a loss function that updates weights dynamically, allowing the student model to quickly learn right knowledge-based easy tasks initially and tackle hard tasks corresponding to biases later, greatly enhancing the student model's learning efficiency. To the best of our knowledge, this is the first strategy enabling the student model to surpass the teacher model. Experiments demonstrate that our strategy, as a plug-and-play module, is versatile across various mainstream KD frameworks. We will release our code after the paper is accepted.