 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Semantic-Aided Few-Shot Learning
Nov 30, 2023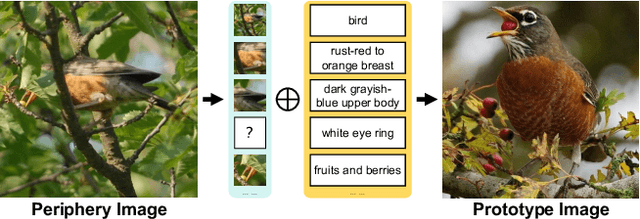
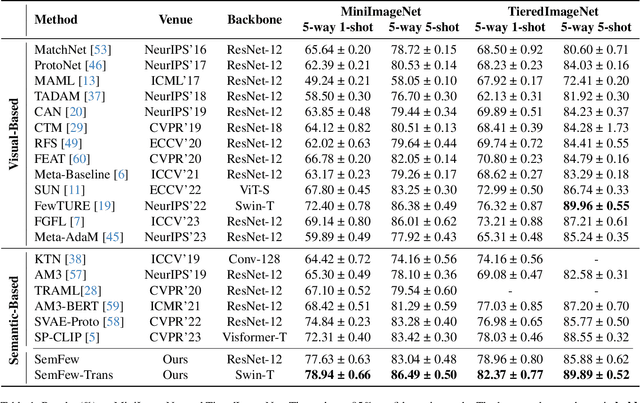
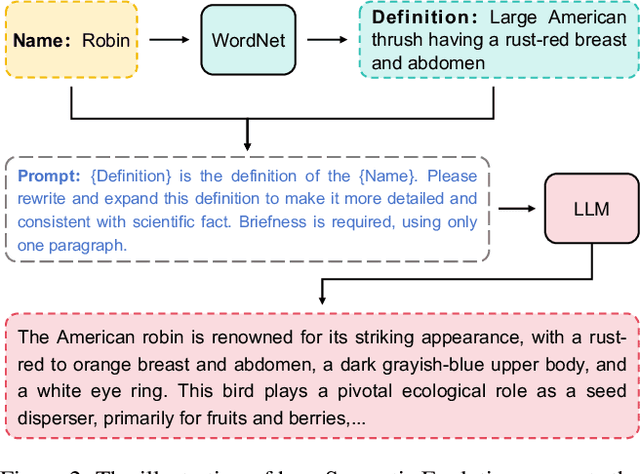
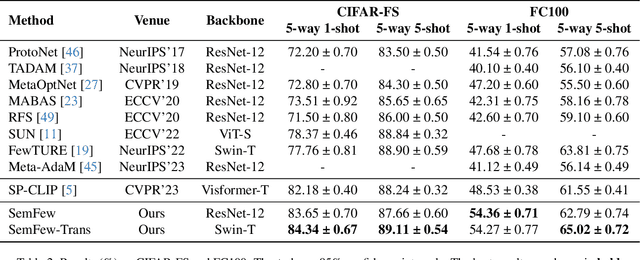
Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in few-shot learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on five benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks.
Analysis and Applications of Deep Learning with Finite Samples in Full Life-Cycle Intelligence of Nuclear Power Generation
Nov 07, 2023



The advent of Industry 4.0 has precipitated the incorporation of Artificial Intelligence (AI) methods within industrial contexts, aiming to realize intelligent manufacturing, operation as well as maintenance, also known as industrial intelligence. However, intricate industrial milieus, particularly those relating to energy exploration and production, frequently encompass data characterized by long-tailed class distribution, sample imbalance, and domain shift. These attributes pose noteworthy challenges to data-centric Deep Learning (DL) techniques, crucial for the realization of industrial intelligence. The present study centers on the intricate and distinctive industrial scenarios of Nuclear Power Generation (NPG), meticulously scrutinizing the application of DL techniques under the constraints of finite data samples. Initially, the paper expounds on potential employment scenarios for AI across the full life-cycle of NPG. Subsequently, we delve into an evaluative exposition of DL's advancement, grounded in the finite sample perspective. This encompasses aspects such as small-sample learning, few-shot learning, zero-shot learning, and open-set recognition, also referring to the unique data characteristics of NPG. The paper then proceeds to present two specific case studies. The first revolves around the automatic recognition of zirconium alloy metallography, while the second pertains to open-set recognition for signal diagnosis of machinery sensors. These cases, spanning the entirety of NPG's life-cycle, are accompanied by constructive outcomes and insightful deliberations. By exploring and applying DL methodologies within the constraints of finite sample availability, this paper not only furnishes a robust technical foundation but also introduces a fresh perspective toward the secure and efficient advancement and exploitation of this advanced energy source.
Attribute Localization and Revision Network for Zero-Shot Learning
Oct 11, 2023Zero-shot learning enables the model to recognize unseen categories with the aid of auxiliary semantic information such as attributes. Current works proposed to detect attributes from local image regions and align extracted features with class-level semantics. In this paper, we find that the choice between local and global features is not a zero-sum game, global features can also contribute to the understanding of attributes. In addition, aligning attribute features with class-level semantics ignores potential intra-class attribute variation. To mitigate these disadvantages, we present Attribute Localization and Revision Network in this paper. First, we design Attribute Localization Module (ALM) to capture both local and global features from image regions, a novel module called Scale Control Unit is incorporated to fuse global and local representations. Second, we propose Attribute Revision Module (ARM), which generates image-level semantics by revising the ground-truth value of each attribute, compensating for performance degradation caused by ignoring intra-class variation. Finally, the output of ALM will be aligned with revised semantics produced by ARM to achieve the training process. Comprehensive experimental results on three widely used benchmarks demonstrate the effectiveness of our model in the zero-shot prediction task.
RMBR: A Regularized Minimum Bayes Risk Reranking Framework for Machine Translation
Mar 01, 2022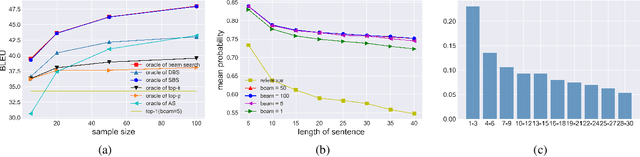

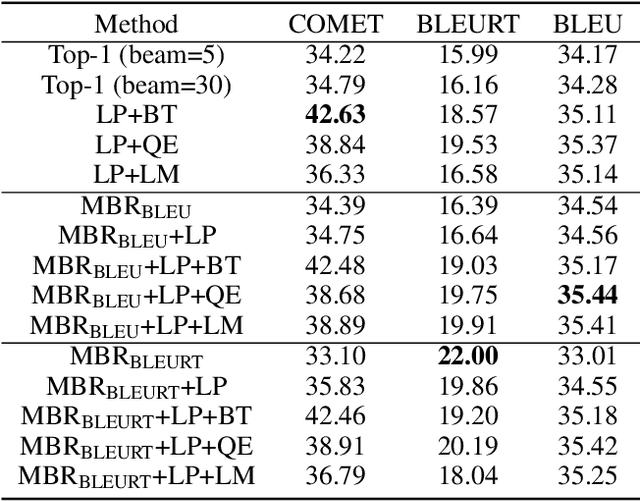
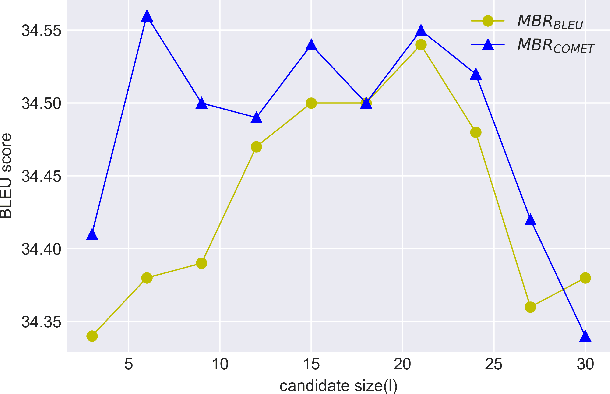
Beam search is the most widely used decoding method for neural machine translation (NMT). In practice, the top-1 candidate with the highest log-probability among the n candidates is selected as the preferred one. However, this top-1 candidate may not be the best overall translation among the n-best list. Recently, Minimum Bayes Risk (MBR) decoding has been proposed to improve the quality for NMT, which seeks for a consensus translation that is closest on average to other candidates from the n-best list. We argue that MBR still suffers from the following problems: The utility function only considers the lexical-level similarity between candidates; The expected utility considers the entire n-best list which is time-consuming and inadequate candidates in the tail list may hurt the performance; Only the relationship between candidates is considered. To solve these issues, we design a regularized MBR reranking framework (RMBR), which considers semantic-based similarity and computes the expected utility for each candidate by truncating the list. We expect the proposed framework to further consider the translation quality and model uncertainty of each candidate. Thus the proposed quality regularizer and uncertainty regularizer are incorporated into the framework. Extensive experiments on multiple translation tasks demonstrate the effectiveness of our method.
A Data-Driven Column Generation Algorithm For Bin Packing Problem in Manufacturing Industry
Feb 25, 2022



The bin packing problem exists widely in real logistic scenarios (e.g., packing pipeline, express delivery), with its goal to improve the packing efficiency and reduce the transportation cost. In this NP-hard combinatorial optimization problem, the position and quantity of each item in the box are strictly restricted by complex constraints and special customer requirements. Existing approaches are hard to obtain the optimal solution since rigorous constraints cannot be handled within a reasonable computation load. In this paper, for handling this difficulty, the packing knowledge is extracted from historical data collected from the packing pipeline of Huawei. First, by fully exploiting the relationship between historical packing records and input orders(orders to be packed) , the problem is reformulated as a set cover problem. Then, two novel strategies, the constraint handling and process acceleration strategies are applied to the classic column generation approach to solve this set cover problem. The cost of solving pricing problem for generating new columns is high due to the complex constraints and customer requirements. The proposed constraints handling strategy exploits the historical packing records with the most negative value of the reduced cost. Those constraints have been implicitly satisfied in these historical packing records so that there is no need to conduct further evaluation on constraints, thus the computational load is saved. To further eliminate the iteration process of column generation algorithm and accelerate the optimization process, a Learning to Price approach called Modified Pointer Network is proposed, by which we can determine which historical packing records should be selected directly. Through experiments on realworld datasets, we show our proposed method can improve the packing success rate and decrease the computation time simultaneously.