 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Attention Patterns Exist: A Unifying Temporal Perspective Analysis
Jan 29, 2026Attention patterns play a crucial role in both training and inference of large language models (LLMs). Prior works have identified individual patterns such as retrieval heads, sink heads, and diagonal traces, yet these observations remain fragmented and lack a unifying explanation. To bridge this gap, we introduce \textbf{Temporal Attention Pattern Predictability Analysis (TAPPA), a unifying framework that explains diverse attention patterns by analyzing their underlying mathematical formulations} from a temporally continuous perspective. TAPPA both deepens the understanding of attention behavior and guides inference acceleration approaches. Specifically, TAPPA characterizes attention patterns as predictable patterns with clear regularities and unpredictable patterns that appear effectively random. Our analysis further reveals that this distinction can be explained by the degree of query self-similarity along the temporal dimension. Focusing on the predictable patterns, we further provide a detailed mathematical analysis of three representative cases through the joint effect of queries, keys, and Rotary Positional Embeddings (RoPE). We validate TAPPA by applying its insights to KV cache compression and LLM pruning tasks. Across these tasks, a simple metric motivated by TAPPA consistently improves performance over baseline methods. The code is available at https://github.com/MIRALab-USTC/LLM-TAPPA.
Discovering Interpretable Programmatic Policies via Multimodal LLM-assisted Evolutionary Search
Aug 07, 2025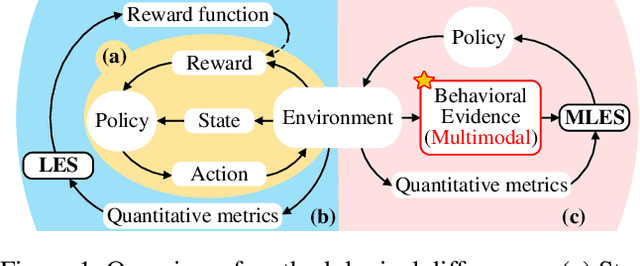
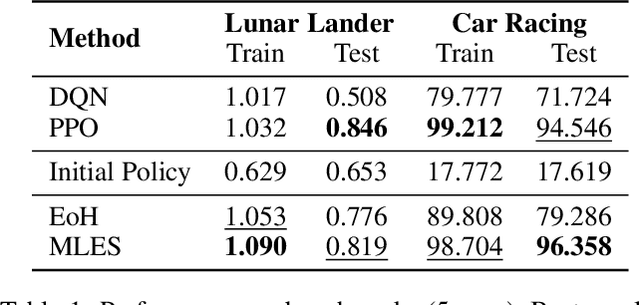
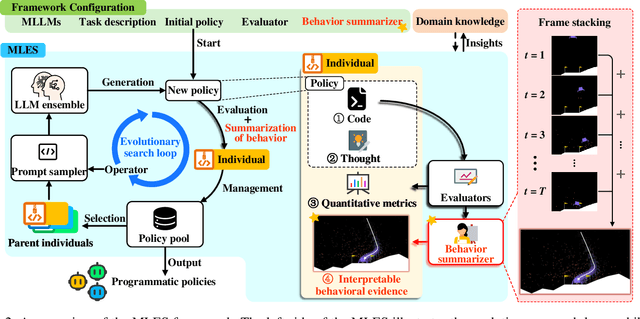
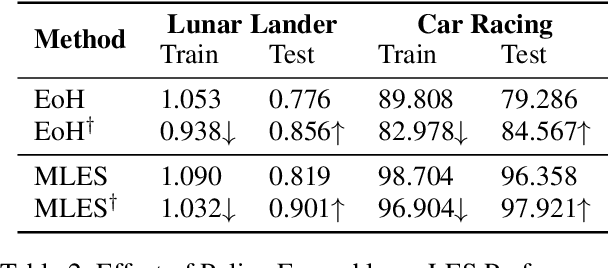
Interpretability and high performance are essential goals in designing control policies, particularly for safety-critical tasks. Deep reinforcement learning has greatly enhanced performance, yet its inherent lack of interpretability often undermines trust and hinders real-world deployment. This work addresses these dual challenges by introducing a novel approach for programmatic policy discovery, called Multimodal Large Language Model-assisted Evolutionary Search (MLES). MLES utilizes multimodal large language models as policy generators, combining them with evolutionary mechanisms for automatic policy optimization. It integrates visual feedback-driven behavior analysis within the policy generation process to identify failure patterns and facilitate targeted improvements, enhancing the efficiency of policy discovery and producing adaptable, human-aligned policies. Experimental results show that MLES achieves policy discovery capabilities and efficiency comparable to Proximal Policy Optimization (PPO) across two control tasks, while offering transparent control logic and traceable design processes. This paradigm overcomes the limitations of predefined domain-specific languages, facilitates knowledge transfer and reuse, and is scalable across various control tasks. MLES shows promise as a leading approach for the next generation of interpretable control policy discovery.
Fitness Landscape of Large Language Model-Assisted Automated Algorithm Search
May 01, 2025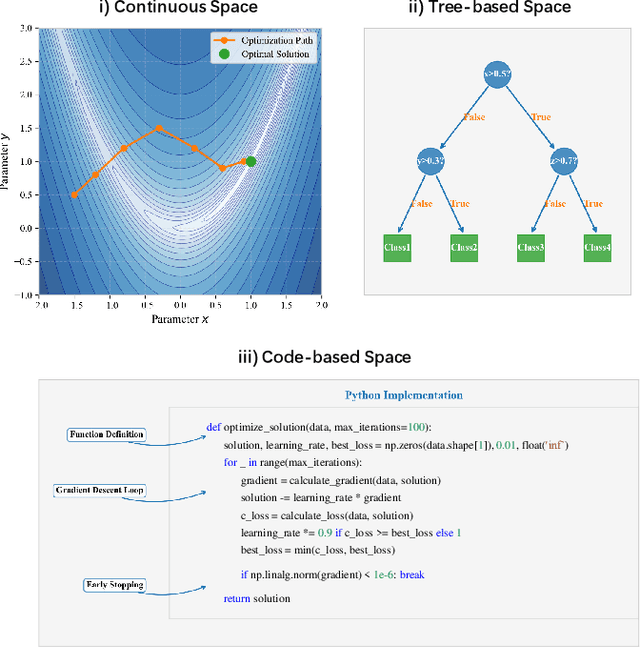
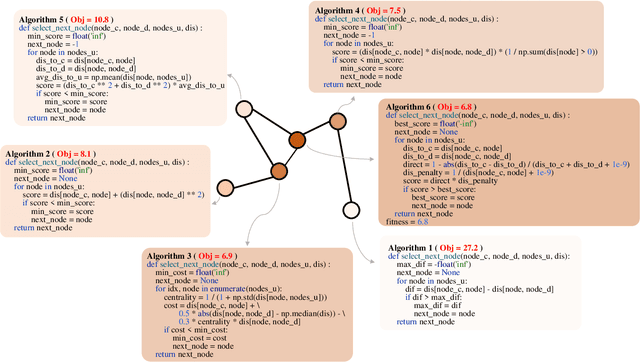
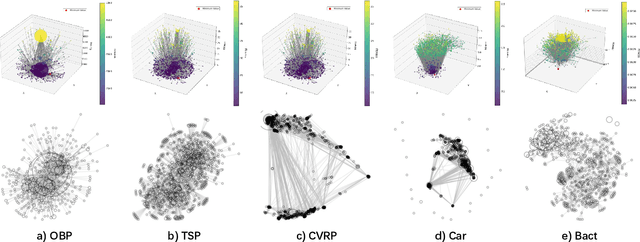
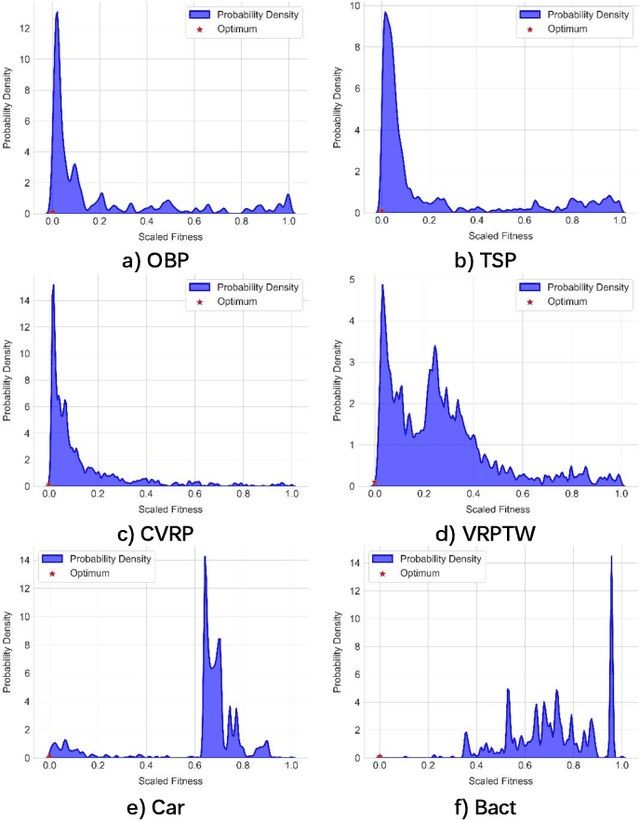
Large Language Models (LLMs) have demonstrated significant potential in algorithm design. However, when integrated into search frameworks for iterative algorithm search, the underlying fitness landscape--critical for understanding search behaviou--remains underexplored. In this paper, we illustrate and analyze the fitness landscape of LLM-assisted Algorithm Search (LAS) using a graph-based approach, where nodes represent algorithms and edges denote transitions between them. We conduct extensive evaluations across six algorithm design tasks and six commonly used LLMs. Our findings reveal that LAS landscapes are highly multimodal and rugged, particularly in combinatorial optimization tasks, with distinct structural variations across tasks and LLMs. For instance, heuristic design tasks exhibit dense clusters of high-performing algorithms, while symbolic regression tasks show sparse, scattered distributions. Additionally, we demonstrate how population size influences exploration-exploitation trade-offs and the evolving trajectory of elite algorithms. These insights not only advance our understanding of LAS landscapes but also provide practical guidance for designing more effective LAS methods.
ARS: Automatic Routing Solver with Large Language Models
Feb 21, 2025



Real-world Vehicle Routing Problems (VRPs) are characterized by a variety of practical constraints, making manual solver design both knowledge-intensive and time-consuming. Although there is increasing interest in automating the design of routing algorithms, existing research has explored only a limited array of VRP variants and fails to adequately address the complex and prevalent constraints encountered in real-world situations. To fill this gap, this paper introduces RoutBench, a benchmark of 1,000 VRP variants derived from 24 attributes, for evaluating the effectiveness of automatic routing solvers in addressing complex constraints. Along with RoutBench, we present the Automatic Routing Solver (ARS), which employs Large Language Model (LLM) agents to enhance a backbone algorithm framework by automatically generating constraint-aware heuristic code, based on problem descriptions and several representative constraints selected from a database. Our experiments show that ARS outperforms state-of-the-art LLM-based methods and commonly used solvers, automatically solving 91.67% of common VRPs and achieving at least a 30% improvement across all benchmarks.
DPN: Decoupling Partition and Navigation for Neural Solvers of Min-max Vehicle Routing Problems
May 27, 2024


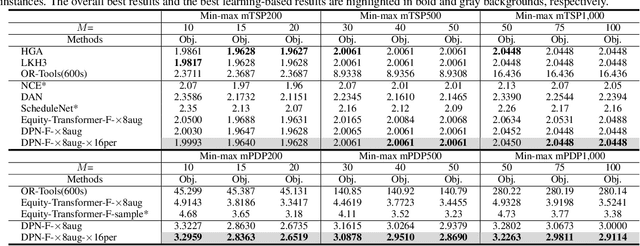
The min-max vehicle routing problem (min-max VRP) traverses all given customers by assigning several routes and aims to minimize the length of the longest route. Recently, reinforcement learning (RL)-based sequential planning methods have exhibited advantages in solving efficiency and optimality. However, these methods fail to exploit the problem-specific properties in learning representations, resulting in less effective features for decoding optimal routes. This paper considers the sequential planning process of min-max VRPs as two coupled optimization tasks: customer partition for different routes and customer navigation in each route (i.e., partition and navigation). To effectively process min-max VRP instances, we present a novel attention-based Partition-and-Navigation encoder (P&N Encoder) that learns distinct embeddings for partition and navigation. Furthermore, we utilize an inherent symmetry in decoding routes and develop an effective agent-permutation-symmetric (APS) loss function. Experimental results demonstrate that the proposed Decoupling-Partition-Navigation (DPN) method significantly surpasses existing learning-based methods in both single-depot and multi-depot min-max VRPs. Our code is available at
Prompt Learning for Generalized Vehicle Routing
May 20, 2024Neural combinatorial optimization (NCO) is a promising learning-based approach to solving various vehicle routing problems without much manual algorithm design. However, the current NCO methods mainly focus on the in-distribution performance, while the real-world problem instances usually come from different distributions. A costly fine-tuning approach or generalized model retraining from scratch could be needed to tackle the out-of-distribution instances. Unlike the existing methods, this work investigates an efficient prompt learning approach in NCO for cross-distribution adaptation. To be concrete, we propose a novel prompt learning method to facilitate fast zero-shot adaptation of a pre-trained model to solve routing problem instances from different distributions. The proposed model learns a set of prompts among various distributions and then selects the best-matched one to prompt a pre-trained attention model for each problem instance. Extensive experiments show that the proposed prompt learning approach facilitates the fast adaptation of pre-trained routing models. It also outperforms existing generalized models on both in-distribution prediction and zero-shot generalization to a diverse set of new tasks. Our code implementation is available online https://github.com/FeiLiu36/PromptVRP.
Instance-Conditioned Adaptation for Large-scale Generalization of Neural Combinatorial Optimization
May 03, 2024

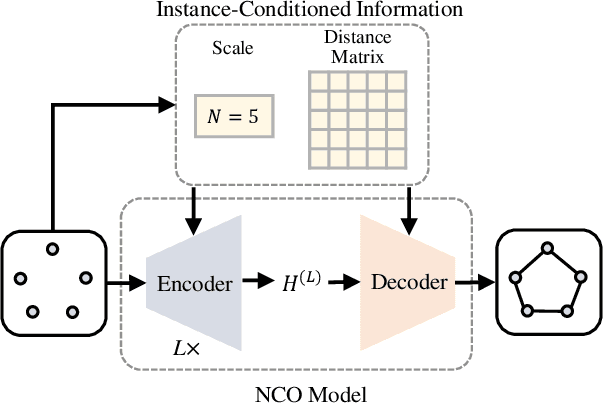

The neural combinatorial optimization (NCO) approach has shown great potential for solving routing problems without the requirement of expert knowledge. However, existing constructive NCO methods cannot directly solve large-scale instances, which significantly limits their application prospects. To address these crucial shortcomings, this work proposes a novel Instance-Conditioned Adaptation Model (ICAM) for better large-scale generalization of neural combinatorial optimization. In particular, we design a powerful yet lightweight instance-conditioned adaptation module for the NCO model to generate better solutions for instances across different scales. In addition, we develop an efficient three-stage reinforcement learning-based training scheme that enables the model to learn cross-scale features without any labeled optimal solution. Experimental results show that our proposed method is capable of obtaining excellent results with a very fast inference time in solving Traveling Salesman Problems (TSPs) and Capacitated Vehicle Routing Problems (CVRPs) across different scales. To the best of our knowledge, our model achieves state-of-the-art performance among all RL-based constructive methods for TSP and CVRP with up to 1,000 nodes.
Self-Improved Learning for Scalable Neural Combinatorial Optimization
Mar 30, 2024The end-to-end neural combinatorial optimization (NCO) method shows promising performance in solving complex combinatorial optimization problems without the need for expert design. However, existing methods struggle with large-scale problems, hindering their practical applicability. To overcome this limitation, this work proposes a novel Self-Improved Learning (SIL) method for better scalability of neural combinatorial optimization. Specifically, we develop an efficient self-improved mechanism that enables direct model training on large-scale problem instances without any labeled data. Powered by an innovative local reconstruction approach, this method can iteratively generate better solutions by itself as pseudo-labels to guide efficient model training. In addition, we design a linear complexity attention mechanism for the model to efficiently handle large-scale combinatorial problem instances with low computation overhead. Comprehensive experiments on the Travelling Salesman Problem (TSP) and the Capacitated Vehicle Routing Problem (CVRP) with up to 100K nodes in both uniform and real-world distributions demonstrate the superior scalability of our method.
Multi-Task Learning for Routing Problem with Cross-Problem Zero-Shot Generalization
Feb 23, 2024Vehicle routing problems (VRPs), which can be found in numerous real-world applications, have been an important research topic for several decades. Recently, the neural combinatorial optimization (NCO) approach that leverages a learning-based model to solve VRPs without manual algorithm design has gained substantial attention. However, current NCO methods typically require building one model for each routing problem, which significantly hinders their practical application for real-world industry problems with diverse attributes. In this work, we make the first attempt to tackle the crucial challenge of cross-problem generalization. In particular, we formulate VRPs as different combinations of a set of shared underlying attributes and solve them simultaneously via a single model through attribute composition. In this way, our proposed model can successfully solve VRPs with unseen attribute combinations in a zero-shot generalization manner. Extensive experiments are conducted on eleven VRP variants, benchmark datasets, and industry logistic scenarios. The results show that the unified model demonstrates superior performance in the eleven VRPs, reducing the average gap to around 5% from over 20% in the existing approach and achieving a significant performance boost on benchmark datasets as well as a real-world logistics application.
An Example of Evolutionary Computation + Large Language Model Beating Human: Design of Efficient Guided Local Search
Jan 04, 2024It is often very tedious for human experts to design efficient algorithms. Recently, we have proposed a novel Algorithm Evolution using Large Language Model (AEL) framework for automatic algorithm design. AEL combines the power of a large language model and the paradigm of evolutionary computation to design, combine, and modify algorithms automatically. In this paper, we use AEL to design the guide algorithm for guided local search (GLS) to solve the well-known traveling salesman problem (TSP). AEL automatically evolves elite GLS algorithms in two days, with minimal human effort and no model training. Experimental results on 1,000 TSP20-TSP100 instances and TSPLib instances show that AEL-designed GLS outperforms state-of-the-art human-designed GLS with the same iteration budget. It achieves a 0% gap on TSP20 and TSP50 and a 0.032% gap on TSP100 in 1,000 iterations. Our findings mark the emergence of a new era in automatic algorithm design.