 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL2R: Learning to Reduce Search Space for Generalizable Neural Routing Solver
Mar 05, 2025Constructive neural combinatorial optimization (NCO) has attracted growing research attention due to its ability to solve complex routing problems without relying on handcrafted rules. However, existing NCO methods face significant challenges in generalizing to large-scale problems due to high computational complexity and inefficient capture of structural patterns. To address this issue, we propose a novel learning-based search space reduction method that adaptively selects a small set of promising candidate nodes at each step of the constructive NCO process. Unlike traditional methods that rely on fixed heuristics, our selection model dynamically prioritizes nodes based on learned patterns, significantly reducing the search space while maintaining solution quality. Experimental results demonstrate that our method, trained solely on 100-node instances from uniform distribution, generalizes remarkably well to large-scale Traveling Salesman Problem (TSP) and Capacitated Vehicle Routing Problem (CVRP) instances with up to 1 million nodes from the uniform distribution and over 80K nodes from other distributions.
UDC: A Unified Neural Divide-and-Conquer Framework for Large-Scale Combinatorial Optimization Problems
Jun 29, 2024Single-stage neural combinatorial optimization solvers have achieved near-optimal results on various small-scale combinatorial optimization (CO) problems without needing expert knowledge. However, these solvers exhibit significant performance degradation when applied to large-scale CO problems. Recently, two-stage neural methods with divide-and-conquer strategies have shown superiorities in addressing large-scale CO problems. Nevertheless, the efficiency of these methods highly relies on problem-specific heuristics in either the divide or the conquer procedure, which limits their applicability to general CO problems. Moreover, these methods employ separate training schemes and ignore the interdependencies between the dividing and conquering strategies, which often leads to sub-optimal solutions. To tackle these drawbacks, this article develops a unified neural divide-and-conquer framework (i.e., UDC) for solving general large-scale CO problems. UDC offers a Divide-Conquer-Reunion (DCR) training method to eliminate the negative impact of a sub-optimal dividing policy. Employing a high-efficiency Graph Neural Network (GNN) for global dividing and a fixed-length sub-path solver for conquering sub-problems, the proposed UDC framework demonstrates extensive applicability, achieving superior performance in 10 representative large-scale CO problems.
Instance-Conditioned Adaptation for Large-scale Generalization of Neural Combinatorial Optimization
May 03, 2024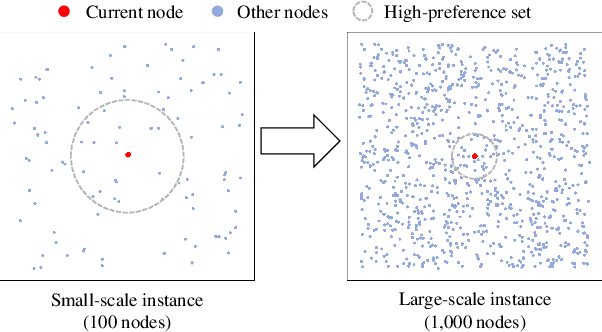

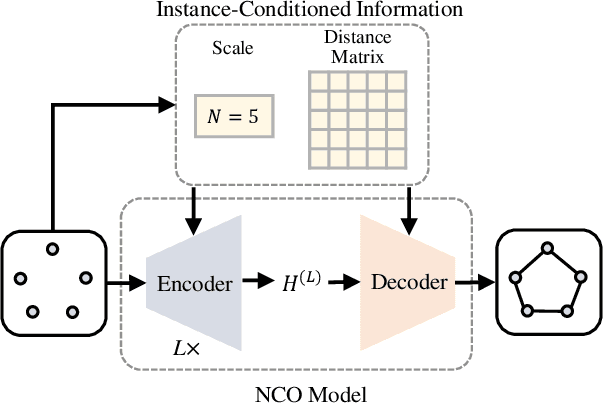

The neural combinatorial optimization (NCO) approach has shown great potential for solving routing problems without the requirement of expert knowledge. However, existing constructive NCO methods cannot directly solve large-scale instances, which significantly limits their application prospects. To address these crucial shortcomings, this work proposes a novel Instance-Conditioned Adaptation Model (ICAM) for better large-scale generalization of neural combinatorial optimization. In particular, we design a powerful yet lightweight instance-conditioned adaptation module for the NCO model to generate better solutions for instances across different scales. In addition, we develop an efficient three-stage reinforcement learning-based training scheme that enables the model to learn cross-scale features without any labeled optimal solution. Experimental results show that our proposed method is capable of obtaining excellent results with a very fast inference time in solving Traveling Salesman Problems (TSPs) and Capacitated Vehicle Routing Problems (CVRPs) across different scales. To the best of our knowledge, our model achieves state-of-the-art performance among all RL-based constructive methods for TSP and CVRP with up to 1,000 nodes.
Distilling Autoregressive Models to Obtain High-Performance Non-Autoregressive Solvers for Vehicle Routing Problems with Faster Inference Speed
Dec 19, 2023Neural construction models have shown promising performance for Vehicle Routing Problems (VRPs) by adopting either the Autoregressive (AR) or Non-Autoregressive (NAR) learning approach. While AR models produce high-quality solutions, they generally have a high inference latency due to their sequential generation nature. Conversely, NAR models generate solutions in parallel with a low inference latency but generally exhibit inferior performance. In this paper, we propose a generic Guided Non-Autoregressive Knowledge Distillation (GNARKD) method to obtain high-performance NAR models having a low inference latency. GNARKD removes the constraint of sequential generation in AR models while preserving the learned pivotal components in the network architecture to obtain the corresponding NAR models through knowledge distillation. We evaluate GNARKD by applying it to three widely adopted AR models to obtain NAR VRP solvers for both synthesized and real-world instances. The experimental results demonstrate that GNARKD significantly reduces the inference time (4-5 times faster) with acceptable performance drop (2-3\%). To the best of our knowledge, this study is first-of-its-kind to obtain NAR VRP solvers from AR ones through knowledge distillation.