 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint Matters: Multi-Modal Representation for Reducing Mixed-Integer Linear programming
Aug 26, 2025Model reduction, which aims to learn a simpler model of the original mixed integer linear programming (MILP), can solve large-scale MILP problems much faster. Most existing model reduction methods are based on variable reduction, which predicts a solution value for a subset of variables. From a dual perspective, constraint reduction that transforms a subset of inequality constraints into equalities can also reduce the complexity of MILP, but has been largely ignored. Therefore, this paper proposes a novel constraint-based model reduction approach for the MILP. Constraint-based MILP reduction has two challenges: 1) which inequality constraints are critical such that reducing them can accelerate MILP solving while preserving feasibility, and 2) how to predict these critical constraints efficiently. To identify critical constraints, we first label these tight-constraints at the optimal solution as potential critical constraints and design a heuristic rule to select a subset of critical tight-constraints. To learn the critical tight-constraints, we propose a multi-modal representation technique that leverages information from both instance-level and abstract-level MILP formulations. The experimental results show that, compared to the state-of-the-art methods, our method improves the quality of the solution by over 50\% and reduces the computation time by 17.47\%.
Dendritic Computing with Multi-Gate Ferroelectric Field-Effect Transistors
May 02, 2025



Although inspired by neuronal systems in the brain, artificial neural networks generally employ point-neurons, which offer far less computational complexity than their biological counterparts. Neurons have dendritic arbors that connect to different sets of synapses and offer local non-linear accumulation - playing a pivotal role in processing and learning. Inspired by this, we propose a novel neuron design based on a multi-gate ferroelectric field-effect transistor that mimics dendrites. It leverages ferroelectric nonlinearity for local computations within dendritic branches, while utilizing the transistor action to generate the final neuronal output. The branched architecture paves the way for utilizing smaller crossbar arrays in hardware integration, leading to greater efficiency. Using an experimentally calibrated device-circuit-algorithm co-simulation framework, we demonstrate that networks incorporating our dendritic neurons achieve superior performance in comparison to much larger networks without dendrites ($\sim$17$\times$ fewer trainable weight parameters). These findings suggest that dendritic hardware can significantly improve computational efficiency, and learning capacity of neuromorphic systems optimized for edge applications.
Fast and Interpretable Mixed-Integer Linear Program Solving by Learning Model Reduction
Dec 31, 2024



By exploiting the correlation between the structure and the solution of Mixed-Integer Linear Programming (MILP), Machine Learning (ML) has become a promising method for solving large-scale MILP problems. Existing ML-based MILP solvers mainly focus on end-to-end solution learning, which suffers from the scalability issue due to the high dimensionality of the solution space. Instead of directly learning the optimal solution, this paper aims to learn a reduced and equivalent model of the original MILP as an intermediate step. The reduced model often corresponds to interpretable operations and is much simpler, enabling us to solve large-scale MILP problems much faster than existing commercial solvers. However, current approaches rely only on the optimal reduced model, overlooking the significant preference information of all reduced models. To address this issue, this paper proposes a preference-based model reduction learning method, which considers the relative performance (i.e., objective cost and constraint feasibility) of all reduced models on each MILP instance as preferences. We also introduce an attention mechanism to capture and represent preference information, which helps improve the performance of model reduction learning tasks. Moreover, we propose a SetCover based pruning method to control the number of reduced models (i.e., labels), thereby simplifying the learning process. Evaluation on real-world MILP problems shows that 1) compared to the state-of-the-art model reduction ML methods, our method obtains nearly 20% improvement on solution accuracy, and 2) compared to the commercial solver Gurobi, two to four orders of magnitude speedups are achieved.
A Remedy to Compute-in-Memory with Dynamic Random Access Memory: 1FeFET-1C Technology for Neuro-Symbolic AI
Oct 20, 2024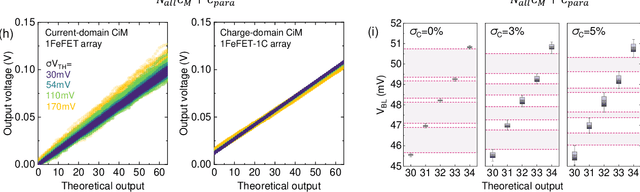
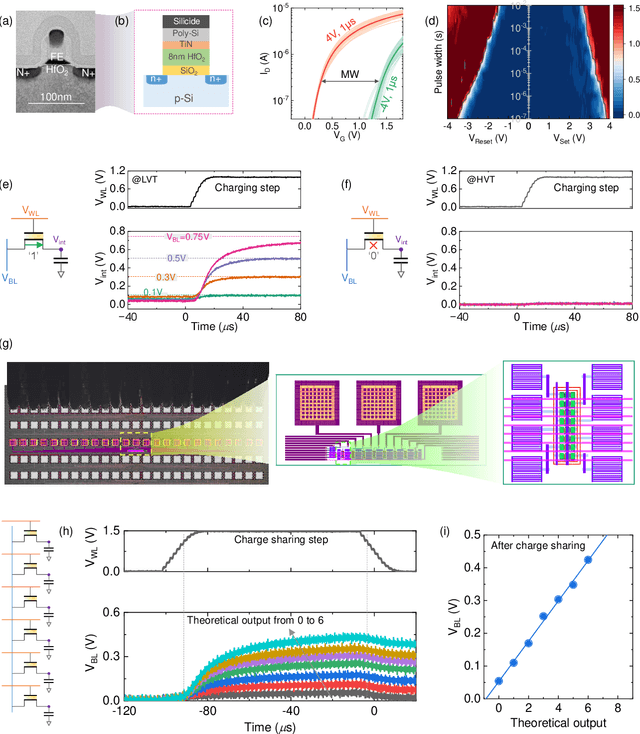
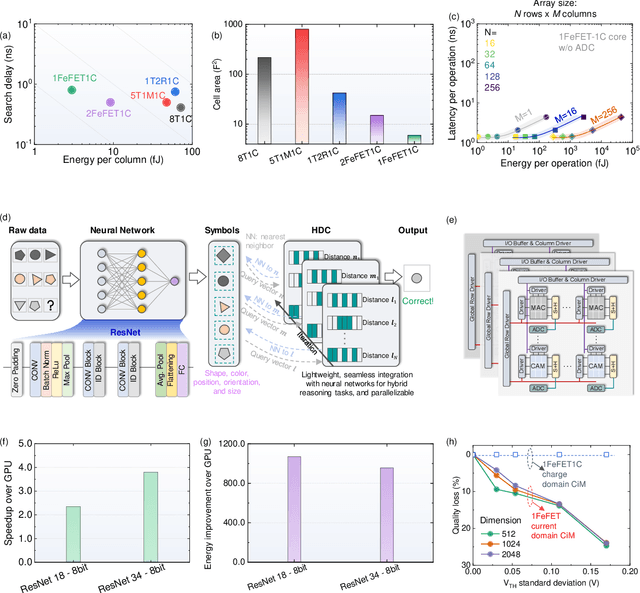
Neuro-symbolic artificial intelligence (AI) excels at learning from noisy and generalized patterns, conducting logical inferences, and providing interpretable reasoning. Comprising a 'neuro' component for feature extraction and a 'symbolic' component for decision-making, neuro-symbolic AI has yet to fully benefit from efficient hardware accelerators. Additionally, current hardware struggles to accommodate applications requiring dynamic resource allocation between these two components. To address these challenges-and mitigate the typical data-transfer bottleneck of classical Von Neumann architectures-we propose a ferroelectric charge-domain compute-in-memory (CiM) array as the foundational processing element for neuro-symbolic AI. This array seamlessly handles both the critical multiply-accumulate (MAC) operations of the 'neuro' workload and the parallel associative search operations of the 'symbolic' workload. To enable this approach, we introduce an innovative 1FeFET-1C cell, combining a ferroelectric field-effect transistor (FeFET) with a capacitor. This design, overcomes the destructive sensing limitations of DRAM in CiM applications, while capable of capitalizing decades of DRAM expertise with a similar cell structure as DRAM, achieves high immunity against FeFET variation-crucial for neuro-symbolic AI-and demonstrates superior energy efficiency. The functionalities of our design have been successfully validated through SPICE simulations and prototype fabrication and testing. Our hardware platform has been benchmarked in executing typical neuro-symbolic AI reasoning tasks, showing over 2x improvement in latency and 1000x improvement in energy efficiency compared to GPU-based implementations.
A Data-Driven Column Generation Algorithm For Bin Packing Problem in Manufacturing Industry
Feb 25, 2022



The bin packing problem exists widely in real logistic scenarios (e.g., packing pipeline, express delivery), with its goal to improve the packing efficiency and reduce the transportation cost. In this NP-hard combinatorial optimization problem, the position and quantity of each item in the box are strictly restricted by complex constraints and special customer requirements. Existing approaches are hard to obtain the optimal solution since rigorous constraints cannot be handled within a reasonable computation load. In this paper, for handling this difficulty, the packing knowledge is extracted from historical data collected from the packing pipeline of Huawei. First, by fully exploiting the relationship between historical packing records and input orders(orders to be packed) , the problem is reformulated as a set cover problem. Then, two novel strategies, the constraint handling and process acceleration strategies are applied to the classic column generation approach to solve this set cover problem. The cost of solving pricing problem for generating new columns is high due to the complex constraints and customer requirements. The proposed constraints handling strategy exploits the historical packing records with the most negative value of the reduced cost. Those constraints have been implicitly satisfied in these historical packing records so that there is no need to conduct further evaluation on constraints, thus the computational load is saved. To further eliminate the iteration process of column generation algorithm and accelerate the optimization process, a Learning to Price approach called Modified Pointer Network is proposed, by which we can determine which historical packing records should be selected directly. Through experiments on realworld datasets, we show our proposed method can improve the packing success rate and decrease the computation time simultaneously.
Rethink AI-based Power Grid Control: Diving Into Algorithm Design
Dec 23, 2020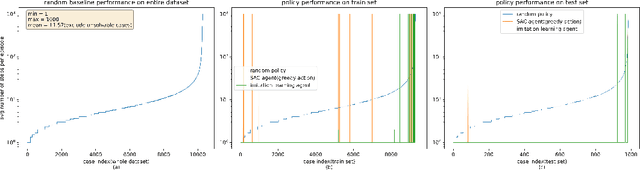

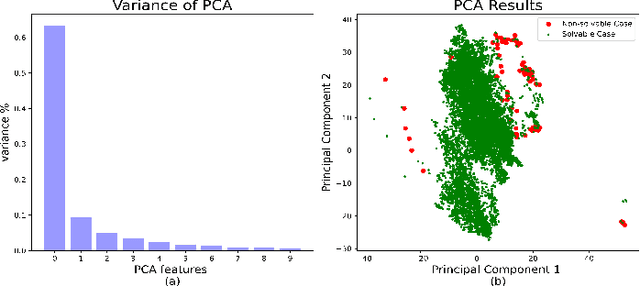
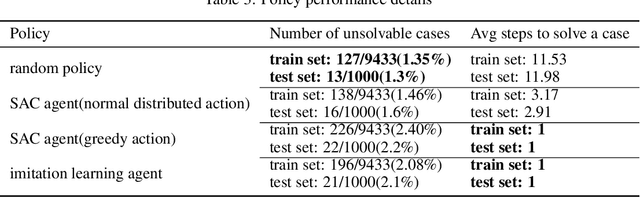
Recently, deep reinforcement learning (DRL)-based approach has shown promisein solving complex decision and control problems in power engineering domain.In this paper, we present an in-depth analysis of DRL-based voltage control fromaspects of algorithm selection, state space representation, and reward engineering.To resolve observed issues, we propose a novel imitation learning-based approachto directly map power grid operating points to effective actions without any interimreinforcement learning process. The performance results demonstrate that theproposed approach has strong generalization ability with much less training time.The agent trained by imitation learning is effective and robust to solve voltagecontrol problem and outperforms the former RL agents.