 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDendritic Computing with Multi-Gate Ferroelectric Field-Effect Transistors
May 02, 2025



Although inspired by neuronal systems in the brain, artificial neural networks generally employ point-neurons, which offer far less computational complexity than their biological counterparts. Neurons have dendritic arbors that connect to different sets of synapses and offer local non-linear accumulation - playing a pivotal role in processing and learning. Inspired by this, we propose a novel neuron design based on a multi-gate ferroelectric field-effect transistor that mimics dendrites. It leverages ferroelectric nonlinearity for local computations within dendritic branches, while utilizing the transistor action to generate the final neuronal output. The branched architecture paves the way for utilizing smaller crossbar arrays in hardware integration, leading to greater efficiency. Using an experimentally calibrated device-circuit-algorithm co-simulation framework, we demonstrate that networks incorporating our dendritic neurons achieve superior performance in comparison to much larger networks without dendrites ($\sim$17$\times$ fewer trainable weight parameters). These findings suggest that dendritic hardware can significantly improve computational efficiency, and learning capacity of neuromorphic systems optimized for edge applications.
NVCiM-PT: An NVCiM-assisted Prompt Tuning Framework for Edge LLMs
Nov 12, 2024



Large Language Models (LLMs) deployed on edge devices, known as edge LLMs, need to continuously fine-tune their model parameters from user-generated data under limited resource constraints. However, most existing learning methods are not applicable for edge LLMs because of their reliance on high resources and low learning capacity. Prompt tuning (PT) has recently emerged as an effective fine-tuning method for edge LLMs by only modifying a small portion of LLM parameters, but it suffers from user domain shifts, resulting in repetitive training and losing resource efficiency. Conventional techniques to address domain shift issues often involve complex neural networks and sophisticated training, which are incompatible for PT for edge LLMs. Therefore, an open research question is how to address domain shift issues for edge LLMs with limited resources. In this paper, we propose a prompt tuning framework for edge LLMs, exploiting the benefits offered by non-volatile computing-in-memory (NVCiM) architectures. We introduce a novel NVCiM-assisted PT framework, where we narrow down the core operations to matrix-matrix multiplication, which can then be accelerated by performing in-situ computation on NVCiM. To the best of our knowledge, this is the first work employing NVCiM to improve the edge LLM PT performance.
FeBiM: Efficient and Compact Bayesian Inference Engine Empowered with Ferroelectric In-Memory Computing
Oct 25, 2024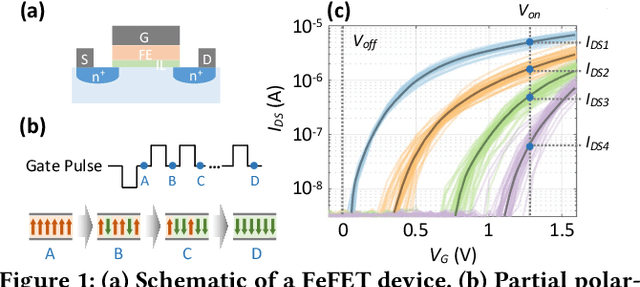
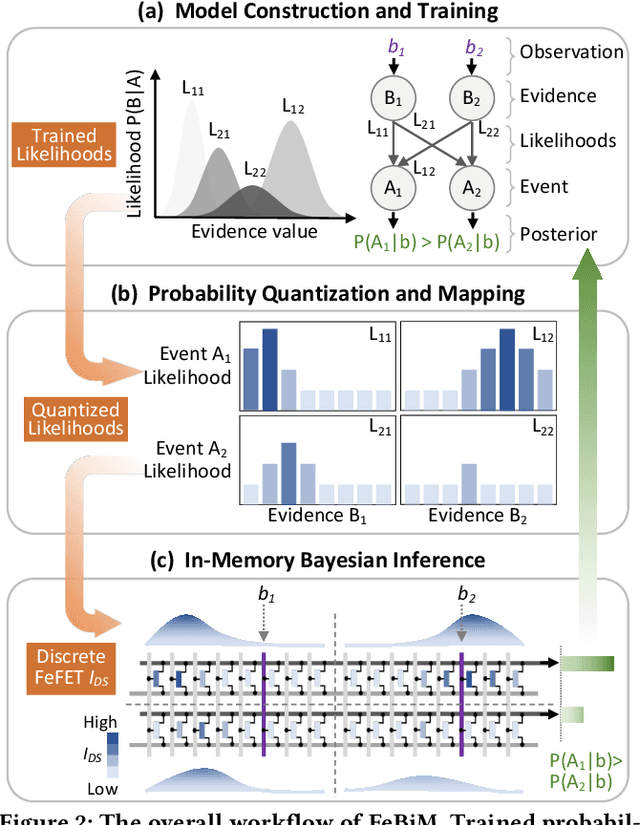
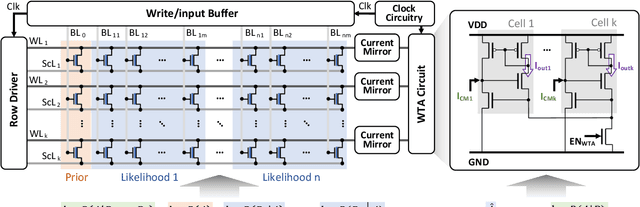
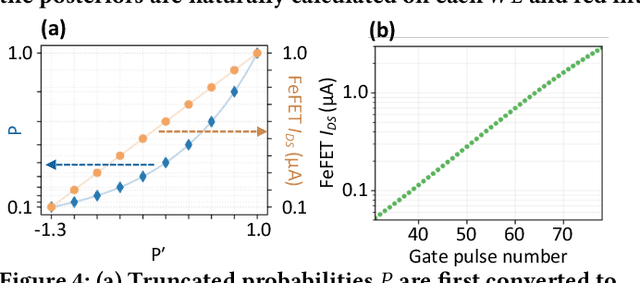
In scenarios with limited training data or where explainability is crucial, conventional neural network-based machine learning models often face challenges. In contrast, Bayesian inference-based algorithms excel in providing interpretable predictions and reliable uncertainty estimation in these scenarios. While many state-of-the-art in-memory computing (IMC) architectures leverage emerging non-volatile memory (NVM) technologies to offer unparalleled computing capacity and energy efficiency for neural network workloads, their application in Bayesian inference is limited. This is because the core operations in Bayesian inference differ significantly from the multiplication-accumulation (MAC) operations common in neural networks, rendering them generally unsuitable for direct implementation in most existing IMC designs. In this paper, we propose FeBiM, an efficient and compact Bayesian inference engine powered by multi-bit ferroelectric field-effect transistor (FeFET)-based IMC. FeBiM effectively encodes the trained probabilities of a Bayesian inference model within a compact FeFET-based crossbar. It maps quantized logarithmic probabilities to discrete FeFET states. As a result, the accumulated outputs of the crossbar naturally represent the posterior probabilities, i.e., the Bayesian inference model's output given a set of observations. This approach enables efficient in-memory Bayesian inference without the need for additional calculation circuitry. As the first FeFET-based in-memory Bayesian inference engine, FeBiM achieves an impressive storage density of 26.32 Mb/mm$^{2}$ and a computing efficiency of 581.40 TOPS/W in a representative Bayesian classification task. These results demonstrate 10.7$\times$/43.4$\times$ improvement in compactness/efficiency compared to the state-of-the-art hardware implementation of Bayesian inference.
A Remedy to Compute-in-Memory with Dynamic Random Access Memory: 1FeFET-1C Technology for Neuro-Symbolic AI
Oct 20, 2024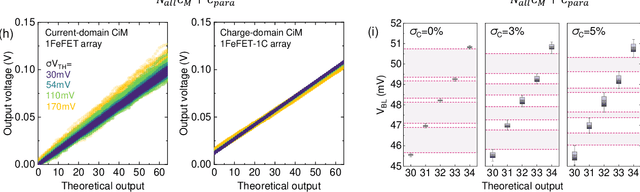
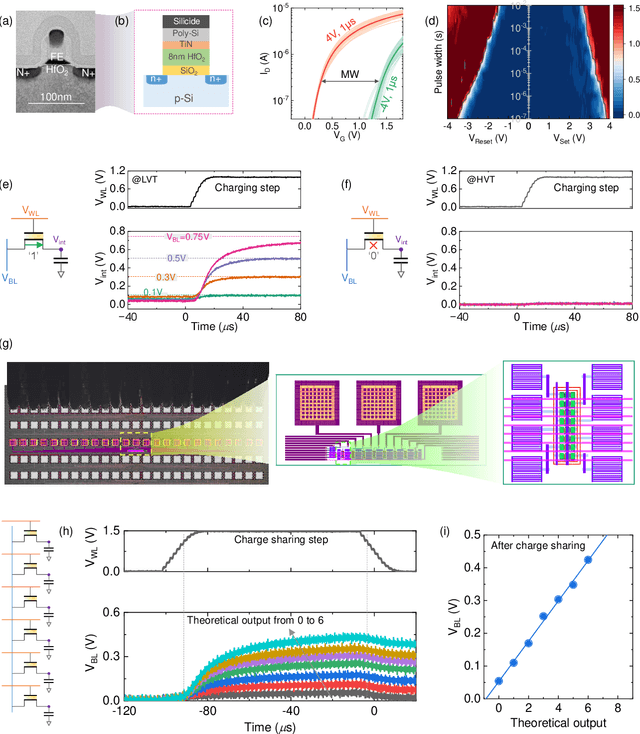
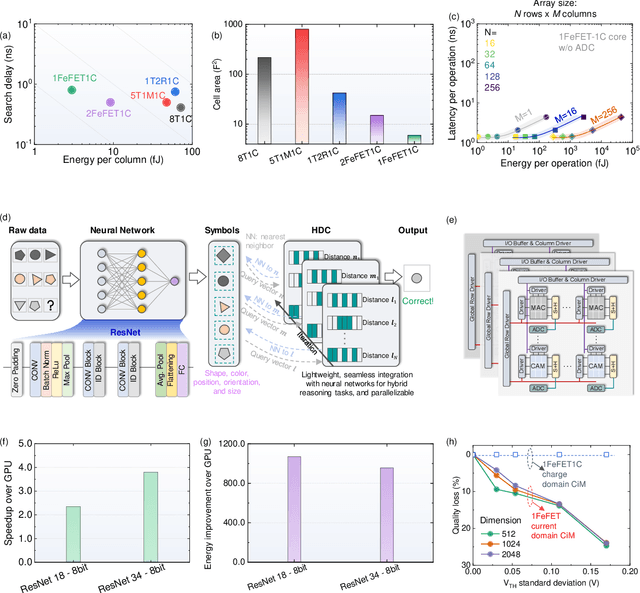
Neuro-symbolic artificial intelligence (AI) excels at learning from noisy and generalized patterns, conducting logical inferences, and providing interpretable reasoning. Comprising a 'neuro' component for feature extraction and a 'symbolic' component for decision-making, neuro-symbolic AI has yet to fully benefit from efficient hardware accelerators. Additionally, current hardware struggles to accommodate applications requiring dynamic resource allocation between these two components. To address these challenges-and mitigate the typical data-transfer bottleneck of classical Von Neumann architectures-we propose a ferroelectric charge-domain compute-in-memory (CiM) array as the foundational processing element for neuro-symbolic AI. This array seamlessly handles both the critical multiply-accumulate (MAC) operations of the 'neuro' workload and the parallel associative search operations of the 'symbolic' workload. To enable this approach, we introduce an innovative 1FeFET-1C cell, combining a ferroelectric field-effect transistor (FeFET) with a capacitor. This design, overcomes the destructive sensing limitations of DRAM in CiM applications, while capable of capitalizing decades of DRAM expertise with a similar cell structure as DRAM, achieves high immunity against FeFET variation-crucial for neuro-symbolic AI-and demonstrates superior energy efficiency. The functionalities of our design have been successfully validated through SPICE simulations and prototype fabrication and testing. Our hardware platform has been benchmarked in executing typical neuro-symbolic AI reasoning tasks, showing over 2x improvement in latency and 1000x improvement in energy efficiency compared to GPU-based implementations.
DynamicTrack: Advancing Gigapixel Tracking in Crowded Scenes
Jul 26, 2024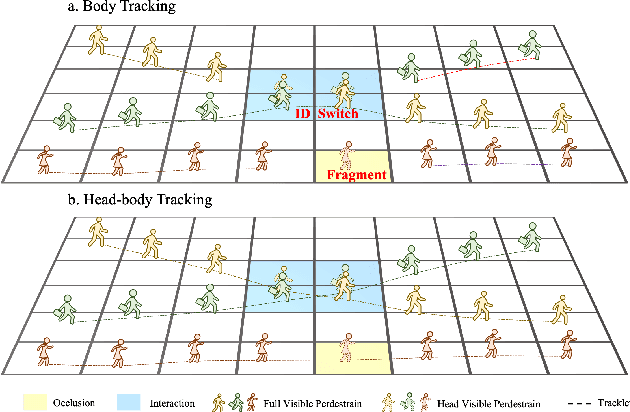
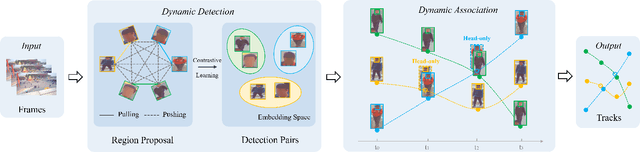
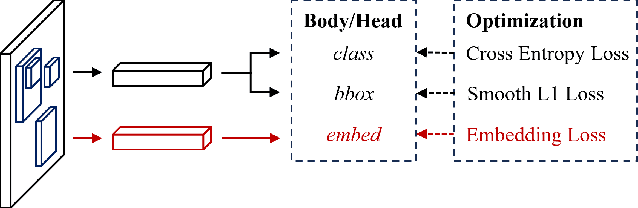

Tracking in gigapixel scenarios holds numerous potential applications in video surveillance and pedestrian analysis. Existing algorithms attempt to perform tracking in crowded scenes by utilizing multiple cameras or group relationships. However, their performance significantly degrades when confronted with complex interaction and occlusion inherent in gigapixel images. In this paper, we introduce DynamicTrack, a dynamic tracking framework designed to address gigapixel tracking challenges in crowded scenes. In particular, we propose a dynamic detector that utilizes contrastive learning to jointly detect the head and body of pedestrians. Building upon this, we design a dynamic association algorithm that effectively utilizes head and body information for matching purposes. Extensive experiments show that our tracker achieves state-of-the-art performance on widely used tracking benchmarks specifically designed for gigapixel crowded scenes.
Robust Implementation of Retrieval-Augmented Generation on Edge-based Computing-in-Memory Architectures
May 07, 2024



Large Language Models (LLMs) deployed on edge devices learn through fine-tuning and updating a certain portion of their parameters. Although such learning methods can be optimized to reduce resource utilization, the overall required resources remain a heavy burden on edge devices. Instead, Retrieval-Augmented Generation (RAG), a resource-efficient LLM learning method, can improve the quality of the LLM-generated content without updating model parameters. However, the RAG-based LLM may involve repetitive searches on the profile data in every user-LLM interaction. This search can lead to significant latency along with the accumulation of user data. Conventional efforts to decrease latency result in restricting the size of saved user data, thus reducing the scalability of RAG as user data continuously grows. It remains an open question: how to free RAG from the constraints of latency and scalability on edge devices? In this paper, we propose a novel framework to accelerate RAG via Computing-in-Memory (CiM) architectures. It accelerates matrix multiplications by performing in-situ computation inside the memory while avoiding the expensive data transfer between the computing unit and memory. Our framework, Robust CiM-backed RAG (RoCR), utilizing a novel contrastive learning-based training method and noise-aware training, can enable RAG to efficiently search profile data with CiM. To the best of our knowledge, this is the first work utilizing CiM to accelerate RAG.
Reconfigurable Frequency Multipliers Based on Complementary Ferroelectric Transistors
Dec 29, 2023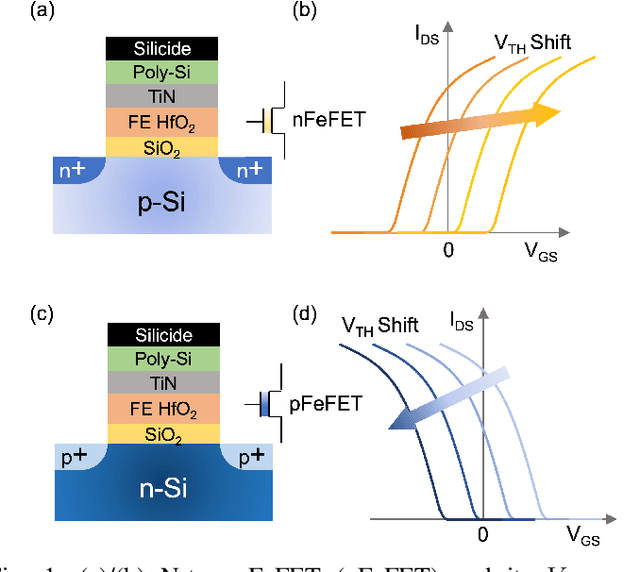
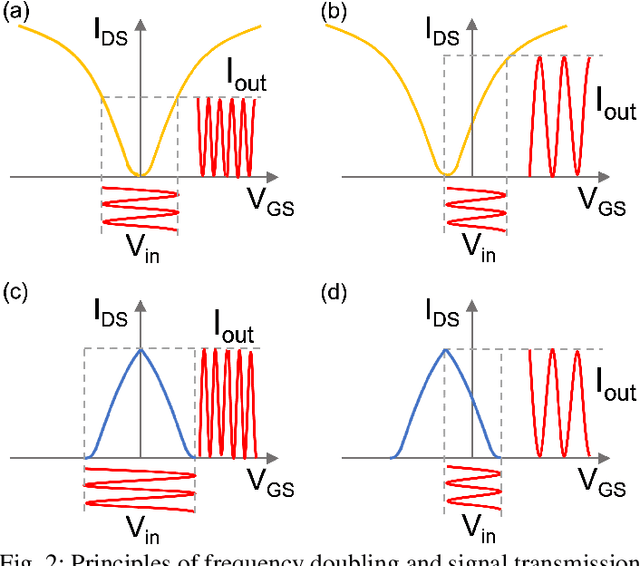
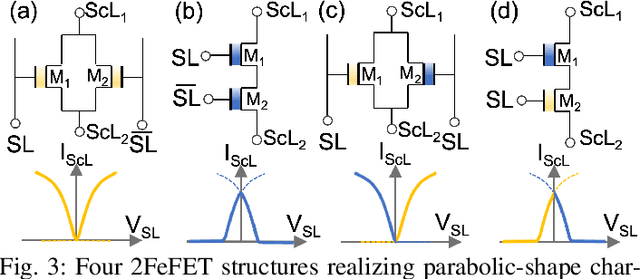
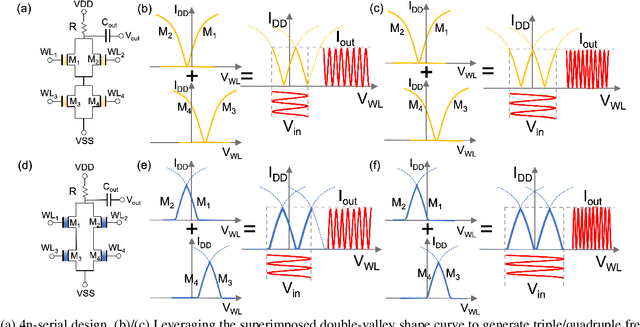
Frequency multipliers, a class of essential electronic components, play a pivotal role in contemporary signal processing and communication systems. They serve as crucial building blocks for generating high-frequency signals by multiplying the frequency of an input signal. However, traditional frequency multipliers that rely on nonlinear devices often require energy- and area-consuming filtering and amplification circuits, and emerging designs based on an ambipolar ferroelectric transistor require costly non-trivial characteristic tuning or complex technology process. In this paper, we show that a pair of standard ferroelectric field effect transistors (FeFETs) can be used to build compact frequency multipliers without aforementioned technology issues. By leveraging the tunable parabolic shape of the 2FeFET structures' transfer characteristics, we propose four reconfigurable frequency multipliers, which can switch between signal transmission and frequency doubling. Furthermore, based on the 2FeFET structures, we propose four frequency multipliers that realize triple, quadruple frequency modes, elucidating a scalable methodology to generate more multiplication harmonics of the input frequency. Performance metrics such as maximum operating frequency, power, etc., are evaluated and compared with existing works. We also implement a practical case of frequency modulation scheme based on the proposed reconfigurable multipliers without additional devices. Our work provides a novel path of scalable and reconfigurable frequency multiplier designs based on devices that have characteristics similar to FeFETs, and show that FeFETs are a promising candidate for signal processing and communication systems in terms of maximum operating frequency and power.
Ground Plane Matters: Picking Up Ground Plane Prior in Monocular 3D Object Detection
Nov 03, 2022The ground plane prior is a very informative geometry clue in monocular 3D object detection (M3OD). However, it has been neglected by most mainstream methods. In this paper, we identify two key factors that limit the applicability of ground plane prior: the projection point localization issue and the ground plane tilt issue. To pick up the ground plane prior for M3OD, we propose a Ground Plane Enhanced Network (GPENet) which resolves both issues at one go. For the projection point localization issue, instead of using the bottom vertices or bottom center of the 3D bounding box (BBox), we leverage the object's ground contact points, which are explicit pixels in the image and easy for the neural network to detect. For the ground plane tilt problem, our GPENet estimates the horizon line in the image and derives a novel mathematical expression to accurately estimate the ground plane equation. An unsupervised vertical edge mining algorithm is also proposed to address the occlusion of the horizon line. Furthermore, we design a novel 3D bounding box deduction method based on a dynamic back projection algorithm, which could take advantage of the accurate contact points and the ground plane equation. Additionally, using only M3OD labels, contact point and horizon line pseudo labels can be easily generated with NO extra data collection and label annotation cost. Extensive experiments on the popular KITTI benchmark show that our GPENet can outperform other methods and achieve state-of-the-art performance, well demonstrating the effectiveness and the superiority of the proposed approach. Moreover, our GPENet works better than other methods in cross-dataset evaluation on the nuScenes dataset. Our code and models will be published.
A Homogeneous Processing Fabric for Matrix-Vector Multiplication and Associative Search Using Ferroelectric Time-Domain Compute-in-Memory
Sep 24, 2022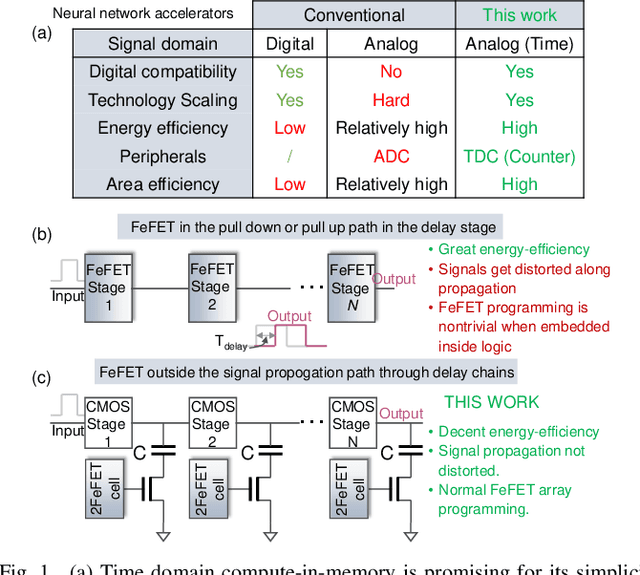
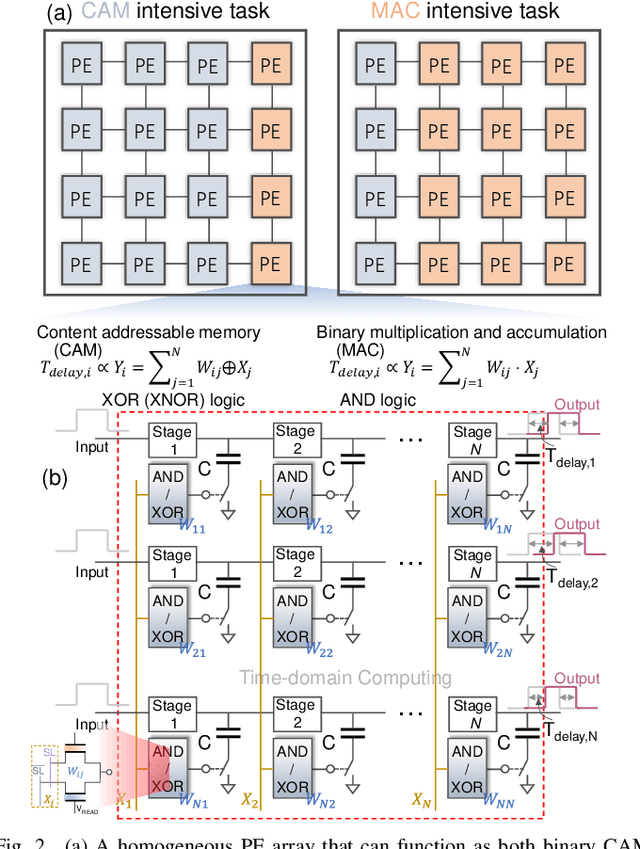
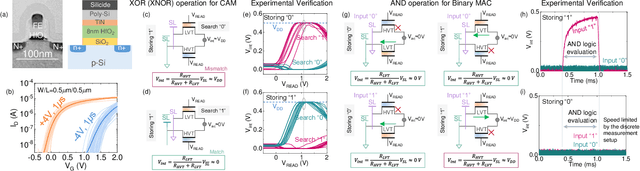
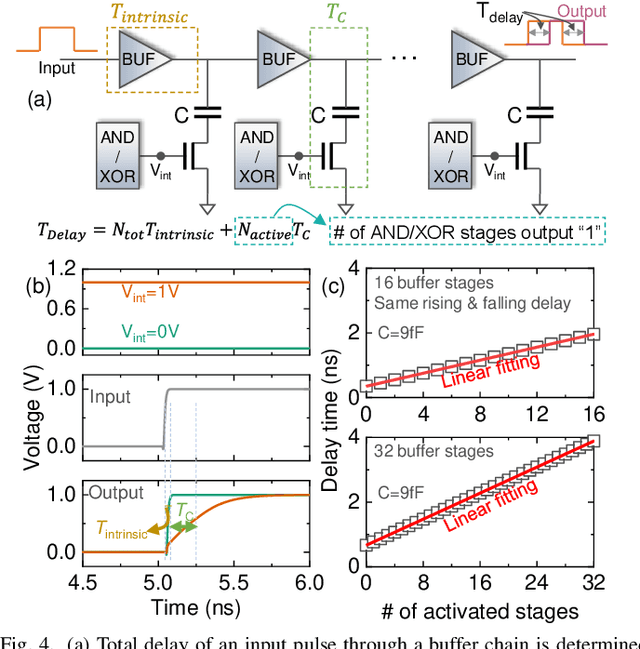
In this work, we propose a ferroelectric FET(FeFET) time-domain compute-in-memory (TD-CiM) array as a homogeneous processing fabric for binary multiplication-accumulation (MAC) and content addressable memory (CAM). We demonstrate that: i) the XOR(XNOR)/AND logic function can be realized using a single cell composed of 2FeFETs connected in series; ii) a two-phase computation in an inverter chain with each stage featuring the XOR/AND cell to control the associated capacitor loading and the computation results of binary MAC and CAM are reflected in the chain output signal delay, illustrating full digital compatibility; iii) comprehensive theoretical and experimental validation of the proposed 2FeFET cell and inverter delay chains and their robustness against FeFET variation; iv) the homogeneous processing fabric is applied in hyperdimensional computing to show dynamic and fine-grain resource allocation to accommodate different tasks requiring varying demands over the binary MAC and CAM resources.
An Ultra-Compact Single FeFET Binary and Multi-Bit Associative Search Engine
Mar 15, 2022Content addressable memory (CAM) is widely used in associative search tasks for its highly parallel pattern matching capability. To accommodate the increasingly complex and data-intensive pattern matching tasks, it is critical to keep improving the CAM density to enhance the performance and area efficiency. In this work, we demonstrate: i) a novel ultra-compact 1FeFET CAM design that enables parallel associative search and in-memory hamming distance calculation; ii) a multi-bit CAM for exact search using the same CAM cell; iii) compact device designs that integrate the series resistor current limiter into the intrinsic FeFET structure to turn the 1FeFET1R into an effective 1FeFET cell; iv) a successful 2-step search operation and a sufficient sensing margin of the proposed binary and multi-bit 1FeFET1R CAM array with sizes of practical interests in both experiments and simulations, given the existing unoptimized FeFET device variation; v) 89.9x speedup and 66.5x energy efficiency improvement over the state-of-the art alignment tools on GPU in accelerating genome pattern matching applications through the hyperdimensional computing paradigm.