 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaterAdmin: Orchestrating Community Water Distribution Optimization via AI Agents
Apr 11, 2026We study the operation of community water systems, where pumps and valves must be scheduled to reliably meet water demands while minimizing energy consumption. While existing optimization-based methods are effective under well-modeled environments, real-world community scenarios exhibit highly dynamic contexts-such as human activities, weather variations, etc-that significantly affect water demand patterns and operational targets across different zones. Traditional optimization approaches struggle to aggregate and adapt to such heterogeneous and rapidly evolving contextual information in real time. While Large Language Model (LLM) agents offer strong capabilities for understanding heterogeneous community context, they are not suitable for directly producing reliable real-time control actions. To address these challenges, we propose a bi-level AI-agent-based framework, WaterAdmin, which integrates LLM-based community context abstraction at the upper level with optimization-based operational control at the lower level. This design leverages the complementary strengths of both paradigms to enable adaptive and reliable operation. We implement WaterAdmin on the hydraulic simulation platform EPANET and demonstrate superior performance in maintaining pressure reliability and reducing energy consumption under highly dynamic community contexts.
3D-Learning: Diffusion-Augmented Distributionally Robust Decision-Focused Learning
Feb 03, 2026Predict-then-Optimize (PTO) pipelines are widely employed in computing and networked systems, where Machine Learning (ML) models are used to predict critical contextual information for downstream decision-making tasks such as cloud LLM serving, data center demand response, and edge workload scheduling. However, these ML predictors are often vulnerable to out-of-distribution (OOD) samples at test time, leading to significant decision performance degradation due to large prediction errors. To address the generalization challenges under OOD conditions, we present the framework of Distributionally Robust Decision-Focused Learning (DR-DFL), which trains ML models to optimize decision performance under the worst-case distribution. Instead of relying on classical Distributionally Robust Optimization (DRO) techniques, we propose Diffusion-Augmented Distributionally Robust Decision-Focused Learning (3D-Learning), which searches for the worst-case distribution within the parameterized space of a diffusion model. By leveraging the powerful distribution modeling capabilities of diffusion models, 3D-Learning identifies worst-case distributions that remain consistent with real data, achieving a favorable balance between average and worst-case scenarios. Empirical results on an LLM resource provisioning task demonstrate that 3D-Learning outperforms existing DRO and Data Augmentation methods in OOD generalization performance.
Illusions in Humans and AI: How Visual Perception Aligns and Diverges
Aug 17, 2025By comparing biological and artificial perception through the lens of illusions, we highlight critical differences in how each system constructs visual reality. Understanding these divergences can inform the development of more robust, interpretable, and human-aligned artificial intelligence (AI) vision systems. In particular, visual illusions expose how human perception is based on contextual assumptions rather than raw sensory data. As artificial vision systems increasingly perform human-like tasks, it is important to ask: does AI experience illusions, too? Does it have unique illusions? This article explores how AI responds to classic visual illusions that involve color, size, shape, and motion. We find that some illusion-like effects can emerge in these models, either through targeted training or as by-products of pattern recognition. In contrast, we also identify illusions unique to AI, such as pixel-level sensitivity and hallucinations, that lack human counterparts. By systematically comparing human and AI responses to visual illusions, we uncover alignment gaps and AI-specific perceptual vulnerabilities invisible to human perception. These findings provide insights for future research on vision systems that preserve human-beneficial perceptual biases while avoiding distortions that undermine trust and safety.
Online Budgeted Matching with General Bids
Nov 06, 2024



Online Budgeted Matching (OBM) is a classic problem with important applications in online advertising, online service matching, revenue management, and beyond. Traditional online algorithms typically assume a small bid setting, where the maximum bid-to-budget ratio (\kappa) is infinitesimally small. While recent algorithms have tried to address scenarios with non-small or general bids, they often rely on the Fractional Last Matching (FLM) assumption, which allows for accepting partial bids when the remaining budget is insufficient. This assumption, however, does not hold for many applications with indivisible bids. In this paper, we remove the FLM assumption and tackle the open problem of OBM with general bids. We first establish an upper bound of 1-\kappa on the competitive ratio for any deterministic online algorithm. We then propose a novel meta algorithm, called MetaAd, which reduces to different algorithms with first known provable competitive ratios parameterized by the maximum bid-to-budget ratio \kappa \in [0, 1]. As a by-product, we extend MetaAd to the FLM setting and get provable competitive algorithms. Finally, we apply our competitive analysis to the design learning-augmented algorithms.
Building Socially-Equitable Public Models
Jun 04, 2024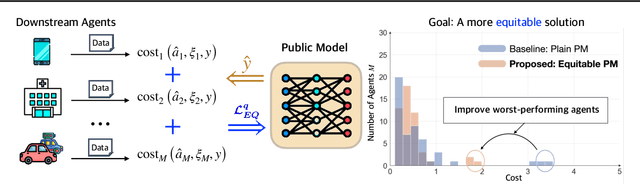
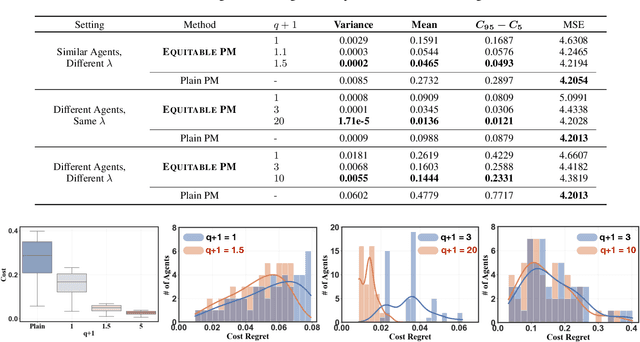
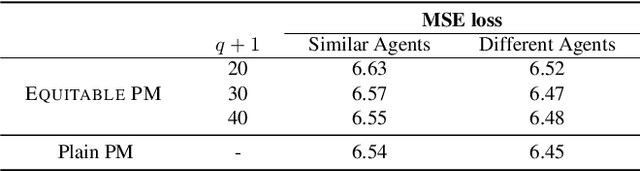
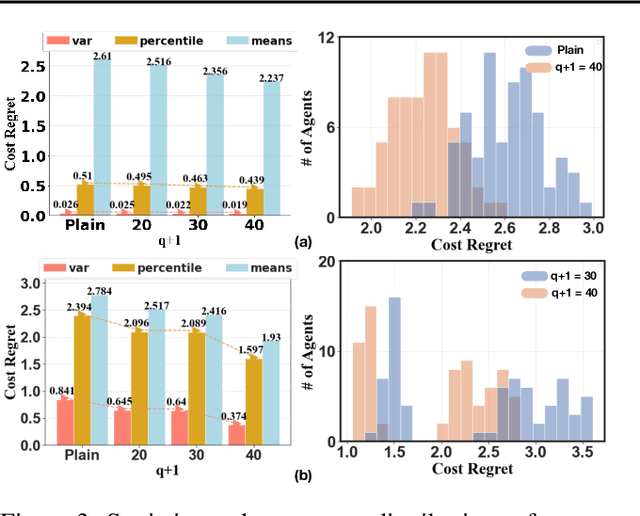
Public models offer predictions to a variety of downstream tasks and have played a crucial role in various AI applications, showcasing their proficiency in accurate predictions. However, the exclusive emphasis on prediction accuracy may not align with the diverse end objectives of downstream agents. Recognizing the public model's predictions as a service, we advocate for integrating the objectives of downstream agents into the optimization process. Concretely, to address performance disparities and foster fairness among heterogeneous agents in training, we propose a novel Equitable Objective. This objective, coupled with a policy gradient algorithm, is crafted to train the public model to produce a more equitable/uniform performance distribution across downstream agents, each with their unique concerns. Both theoretical analysis and empirical case studies have proven the effectiveness of our method in advancing performance equity across diverse downstream agents utilizing the public model for their decision-making. Codes and datasets are released at https://github.com/Ren-Research/Socially-Equitable-Public-Models.
Reconfigurable Frequency Multipliers Based on Complementary Ferroelectric Transistors
Dec 29, 2023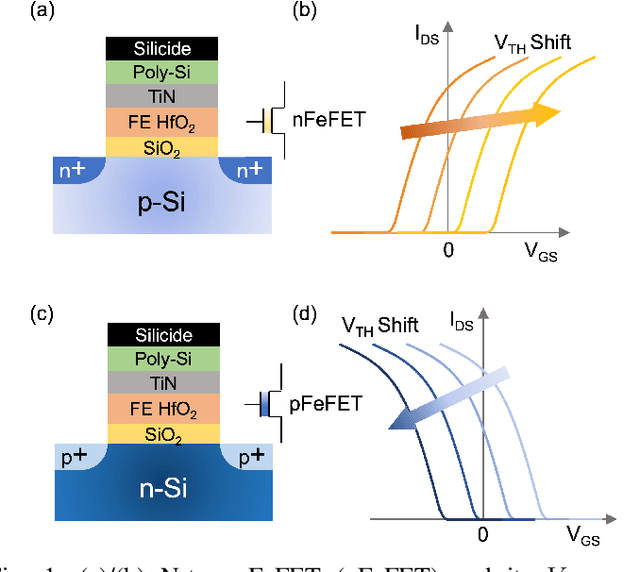
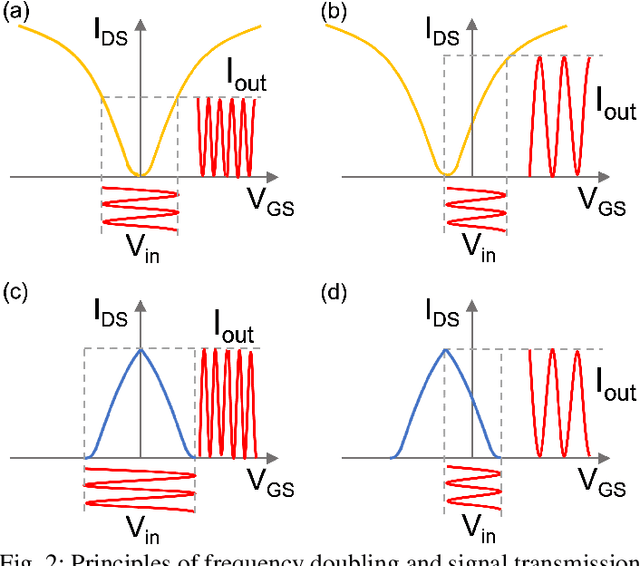
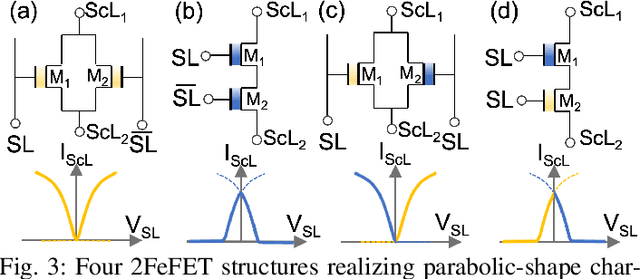
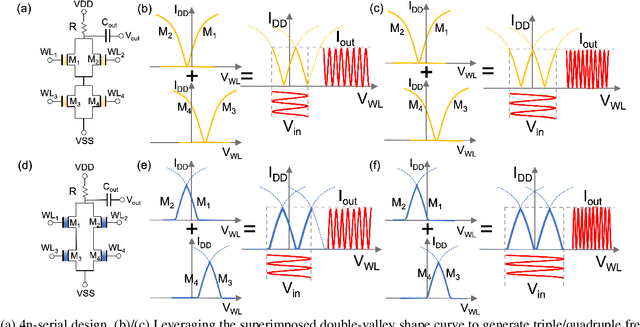
Frequency multipliers, a class of essential electronic components, play a pivotal role in contemporary signal processing and communication systems. They serve as crucial building blocks for generating high-frequency signals by multiplying the frequency of an input signal. However, traditional frequency multipliers that rely on nonlinear devices often require energy- and area-consuming filtering and amplification circuits, and emerging designs based on an ambipolar ferroelectric transistor require costly non-trivial characteristic tuning or complex technology process. In this paper, we show that a pair of standard ferroelectric field effect transistors (FeFETs) can be used to build compact frequency multipliers without aforementioned technology issues. By leveraging the tunable parabolic shape of the 2FeFET structures' transfer characteristics, we propose four reconfigurable frequency multipliers, which can switch between signal transmission and frequency doubling. Furthermore, based on the 2FeFET structures, we propose four frequency multipliers that realize triple, quadruple frequency modes, elucidating a scalable methodology to generate more multiplication harmonics of the input frequency. Performance metrics such as maximum operating frequency, power, etc., are evaluated and compared with existing works. We also implement a practical case of frequency modulation scheme based on the proposed reconfigurable multipliers without additional devices. Our work provides a novel path of scalable and reconfigurable frequency multiplier designs based on devices that have characteristics similar to FeFETs, and show that FeFETs are a promising candidate for signal processing and communication systems in terms of maximum operating frequency and power.
Anytime-Competitive Reinforcement Learning with Policy Prior
Nov 13, 2023This paper studies the problem of Anytime-Competitive Markov Decision Process (A-CMDP). Existing works on Constrained Markov Decision Processes (CMDPs) aim to optimize the expected reward while constraining the expected cost over random dynamics, but the cost in a specific episode can still be unsatisfactorily high. In contrast, the goal of A-CMDP is to optimize the expected reward while guaranteeing a bounded cost in each round of any episode against a policy prior. We propose a new algorithm, called Anytime-Competitive Reinforcement Learning (ACRL), which provably guarantees the anytime cost constraints. The regret analysis shows the policy asymptotically matches the optimal reward achievable under the anytime competitive constraints. Experiments on the application of carbon-intelligent computing verify the reward performance and cost constraint guarantee of ACRL.
Robust Learning for Smoothed Online Convex Optimization with Feedback Delay
Oct 31, 2023We study a challenging form of Smoothed Online Convex Optimization, a.k.a. SOCO, including multi-step nonlinear switching costs and feedback delay. We propose a novel machine learning (ML) augmented online algorithm, Robustness-Constrained Learning (RCL), which combines untrusted ML predictions with a trusted expert online algorithm via constrained projection to robustify the ML prediction. Specifically,we prove that RCL is able to guarantee$(1+\lambda)$-competitiveness against any given expert for any$\lambda>0$, while also explicitly training the ML model in a robustification-aware manner to improve the average-case performance. Importantly,RCL is the first ML-augmented algorithm with a provable robustness guarantee in the case of multi-step switching cost and feedback delay.We demonstrate the improvement of RCL in both robustness and average performance using battery management for electrifying transportationas a case study.
CryoAlign: feature-based method for global and local 3D alignment of EM density maps
Sep 17, 2023



Advances on cryo-electron imaging technologies have led to a rapidly increasing number of density maps. Alignment and comparison of density maps play a crucial role in interpreting structural information, such as conformational heterogeneity analysis using global alignment and atomic model assembly through local alignment. Here, we propose a fast and accurate global and local cryo-electron microscopy density map alignment method CryoAlign, which leverages local density feature descriptors to capture spatial structure similarities. CryoAlign is the first feature-based EM map alignment tool, in which the employment of feature-based architecture enables the rapid establishment of point pair correspondences and robust estimation of alignment parameters. Extensive experimental evaluations demonstrate the superiority of CryoAlign over the existing methods in both alignment accuracy and speed.
Towards Environmentally Equitable AI via Geographical Load Balancing
Jun 20, 2023Fueled by the soaring popularity of large language and foundation models, the accelerated growth of artificial intelligence (AI) models' enormous environmental footprint has come under increased scrutiny. While many approaches have been proposed to make AI more energy-efficient and environmentally friendly, environmental inequity -- the fact that AI's environmental footprint can be disproportionately higher in certain regions than in others -- has emerged, raising social-ecological justice concerns. This paper takes a first step toward addressing AI's environmental inequity by balancing its regional negative environmental impact. Concretely, we focus on the carbon and water footprints of AI model inference and propose equity-aware geographical load balancing (GLB) to explicitly address AI's environmental impacts on the most disadvantaged regions. We run trace-based simulations by considering a set of 10 geographically-distributed data centers that serve inference requests for a large language AI model. The results demonstrate that existing GLB approaches may amplify environmental inequity while our proposed equity-aware GLB can significantly reduce the regional disparity in terms of carbon and water footprints.