 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChorus: Harmonizing Context and Sensing Signals for Data-Free Model Customization in IoT
Dec 17, 2025In real-world IoT applications, sensor data is usually collected under diverse and dynamic contextual conditions where factors such as sensor placements or ambient environments can significantly affect data patterns and downstream performance. Traditional domain adaptation or generalization methods often ignore such context information or use simplistic integration strategies, making them ineffective in handling unseen context shifts after deployment. In this paper, we propose Chorus, a context-aware, data-free model customization approach that adapts models to unseen deployment conditions without requiring target-domain data. The key idea is to learn effective context representations that capture their influence on sensor data patterns and to adaptively integrate them based on the degree of context shift. Specifically, Chorus first performs unsupervised cross-modal reconstruction between unlabeled sensor data and language-based context embeddings, while regularizing the context embedding space to learn robust, generalizable context representations. Then, it trains a lightweight gated head on limited labeled samples to dynamically balance sensor and context contributions-favoring context when sensor evidence is ambiguous and vice versa. To further reduce inference latency, Chorus employs a context-caching mechanism that reuses cached context representations and updates only upon detected context shifts. Experiments on IMU, speech, and WiFi sensing tasks under diverse context shifts show that Chorus outperforms state-of-the-art baselines by up to 11.3% in unseen contexts, while maintaining comparable latency on smartphone and edge devices.
Towards Vector Optimization on Low-Dimensional Vector Symbolic Architecture
Feb 19, 2025



Vector Symbolic Architecture (VSA) is emerging in machine learning due to its efficiency, but they are hindered by issues of hyperdimensionality and accuracy. As a promising mitigation, the Low-Dimensional Computing (LDC) method significantly reduces the vector dimension by ~100 times while maintaining accuracy, by employing a gradient-based optimization. Despite its potential, LDC optimization for VSA is still underexplored. Our investigation into vector updates underscores the importance of stable, adaptive dynamics in LDC training. We also reveal the overlooked yet critical roles of batch normalization (BN) and knowledge distillation (KD) in standard approaches. Besides the accuracy boost, BN does not add computational overhead during inference, and KD significantly enhances inference confidence. Through extensive experiments and ablation studies across multiple benchmarks, we provide a thorough evaluation of our approach and extend the interpretability of binary neural network optimization similar to LDC, previously unaddressed in BNN literature.
Building Socially-Equitable Public Models
Jun 04, 2024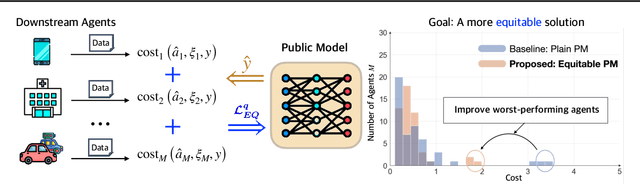
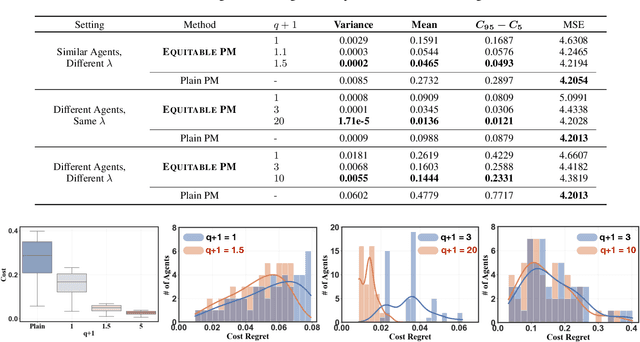
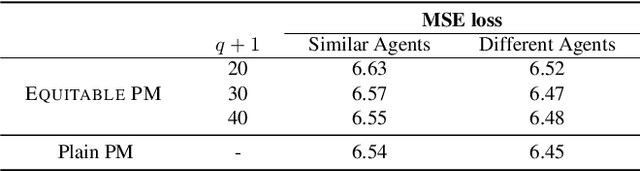
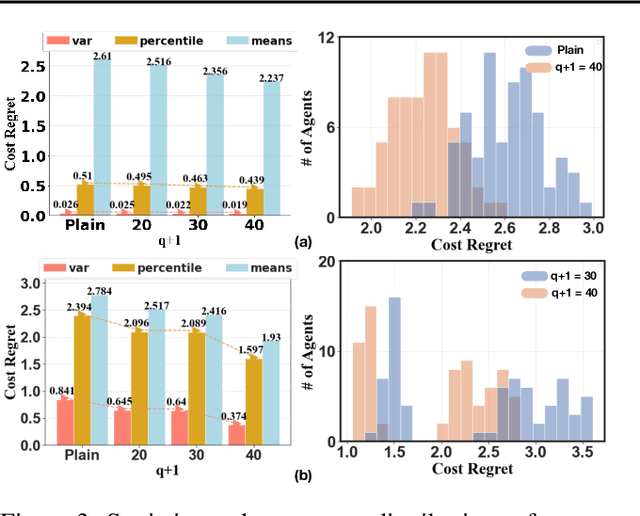
Public models offer predictions to a variety of downstream tasks and have played a crucial role in various AI applications, showcasing their proficiency in accurate predictions. However, the exclusive emphasis on prediction accuracy may not align with the diverse end objectives of downstream agents. Recognizing the public model's predictions as a service, we advocate for integrating the objectives of downstream agents into the optimization process. Concretely, to address performance disparities and foster fairness among heterogeneous agents in training, we propose a novel Equitable Objective. This objective, coupled with a policy gradient algorithm, is crafted to train the public model to produce a more equitable/uniform performance distribution across downstream agents, each with their unique concerns. Both theoretical analysis and empirical case studies have proven the effectiveness of our method in advancing performance equity across diverse downstream agents utilizing the public model for their decision-making. Codes and datasets are released at https://github.com/Ren-Research/Socially-Equitable-Public-Models.
Scheduled Knowledge Acquisition on Lightweight Vector Symbolic Architectures for Brain-Computer Interfaces
Mar 18, 2024Brain-Computer interfaces (BCIs) are typically designed to be lightweight and responsive in real-time to provide users timely feedback. Classical feature engineering is computationally efficient but has low accuracy, whereas the recent neural networks (DNNs) improve accuracy but are computationally expensive and incur high latency. As a promising alternative, the low-dimensional computing (LDC) classifier based on vector symbolic architecture (VSA), achieves small model size yet higher accuracy than classical feature engineering methods. However, its accuracy still lags behind that of modern DNNs, making it challenging to process complex brain signals. To improve the accuracy of a small model, knowledge distillation is a popular method. However, maintaining a constant level of distillation between the teacher and student models may not be the best way for a growing student during its progressive learning stages. In this work, we propose a simple scheduled knowledge distillation method based on curriculum data order to enable the student to gradually build knowledge from the teacher model, controlled by an $\alpha$ scheduler. Meanwhile, we employ the LDC/VSA as the student model to enhance the on-device inference efficiency for tiny BCI devices that demand low latency. The empirical results have demonstrated that our approach achieves better tradeoff between accuracy and hardware efficiency compared to other methods.
ProSGNeRF: Progressive Dynamic Neural Scene Graph with Frequency Modulated Auto-Encoder in Urban Scenes
Dec 15, 2023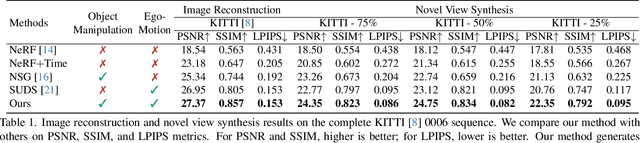
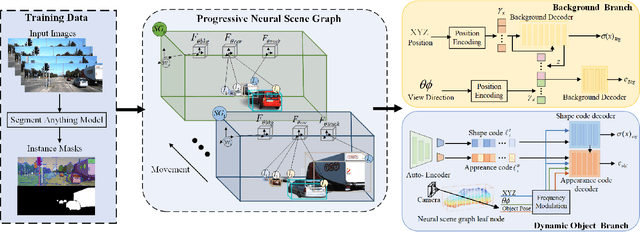
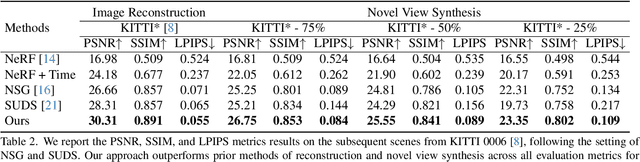
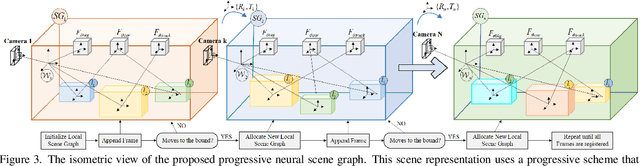
Implicit neural representation has demonstrated promising results in view synthesis for large and complex scenes. However, existing approaches either fail to capture the fast-moving objects or need to build the scene graph without camera ego-motions, leading to low-quality synthesized views of the scene. We aim to jointly solve the view synthesis problem of large-scale urban scenes and fast-moving vehicles, which is more practical and challenging. To this end, we first leverage a graph structure to learn the local scene representations of dynamic objects and the background. Then, we design a progressive scheme that dynamically allocates a new local scene graph trained with frames within a temporal window, allowing us to scale up the representation to an arbitrarily large scene. Besides, the training views of urban scenes are relatively sparse, which leads to a significant decline in reconstruction accuracy for dynamic objects. Therefore, we design a frequency auto-encoder network to encode the latent code and regularize the frequency range of objects, which can enhance the representation of dynamic objects and address the issue of sparse image inputs. Additionally, we employ lidar point projection to maintain geometry consistency in large-scale urban scenes. Experimental results demonstrate that our method achieves state-of-the-art view synthesis accuracy, object manipulation, and scene roaming ability. The code will be open-sourced upon paper acceptance.
MetaLDC: Meta Learning of Low-Dimensional Computing Classifiers for Fast On-Device Adaption
Feb 23, 2023Fast model updates for unseen tasks on intelligent edge devices are crucial but also challenging due to the limited computational power. In this paper,we propose MetaLDC, which meta-trains braininspired ultra-efficient low-dimensional computing classifiers to enable fast adaptation on tiny devices with minimal computational costs. Concretely, during the meta-training stage, MetaLDC meta trains a representation offline by explicitly taking into account that the final (binary) class layer will be fine-tuned for fast adaptation for unseen tasks on tiny devices; during the meta-testing stage, MetaLDC uses closed-form gradients of the loss function to enable fast adaptation of the class layer. Unlike traditional neural networks, MetaLDC is designed based on the emerging LDC framework to enable ultra-efficient on-device inference. Our experiments have demonstrated that compared to SOTA baselines, MetaLDC achieves higher accuracy, robustness against random bit errors, as well as cost-efficient hardware computation.
Navigating Memory Construction by Global Pseudo-Task Simulation for Continual Learning
Oct 16, 2022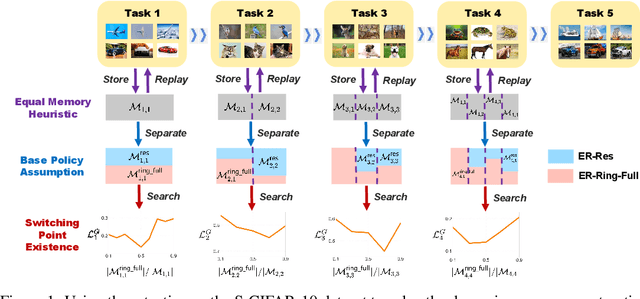
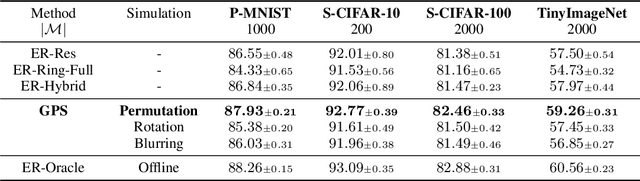
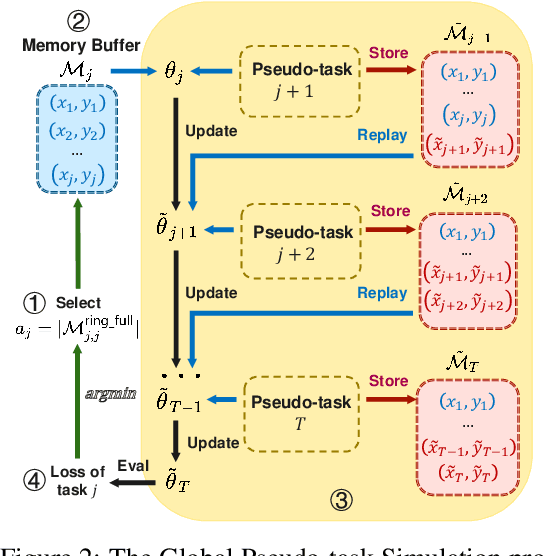
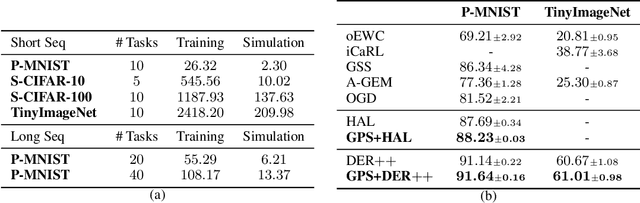
Continual learning faces a crucial challenge of catastrophic forgetting. To address this challenge, experience replay (ER) that maintains a tiny subset of samples from previous tasks has been commonly used. Existing ER works usually focus on refining the learning objective for each task with a static memory construction policy. In this paper, we formulate the dynamic memory construction in ER as a combinatorial optimization problem, which aims at directly minimizing the global loss across all experienced tasks. We first apply three tactics to solve the problem in the offline setting as a starting point. To provide an approximate solution to this problem in the online continual learning setting, we further propose the Global Pseudo-task Simulation (GPS), which mimics future catastrophic forgetting of the current task by permutation. Our empirical results and analyses suggest that the GPS consistently improves accuracy across four commonly used vision benchmarks. We have also shown that our GPS can serve as the unified framework for integrating various memory construction policies in existing ER works.
LeHDC: Learning-Based Hyperdimensional Computing Classifier
Apr 01, 2022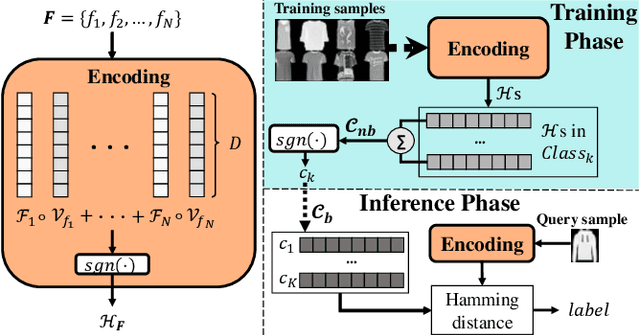


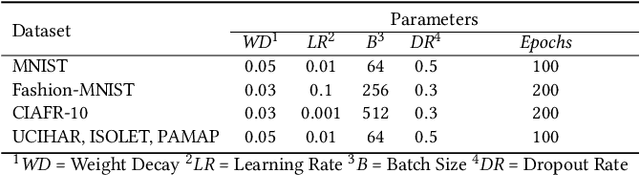
Thanks to the tiny storage and efficient execution, hyperdimensional Computing (HDC) is emerging as a lightweight learning framework on resource-constrained hardware. Nonetheless, the existing HDC training relies on various heuristic methods, significantly limiting their inference accuracy. In this paper, we propose a new HDC framework, called LeHDC, which leverages a principled learning approach to improve the model accuracy. Concretely, LeHDC maps the existing HDC framework into an equivalent Binary Neural Network architecture, and employs a corresponding training strategy to minimize the training loss. Experimental validation shows that LeHDC outperforms previous HDC training strategies and can improve on average the inference accuracy over 15% compared to the baseline HDC.
Enabling SQL-based Training Data Debugging for Federated Learning
Aug 26, 2021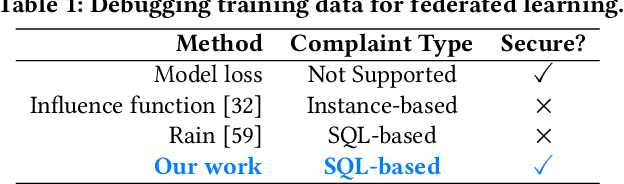
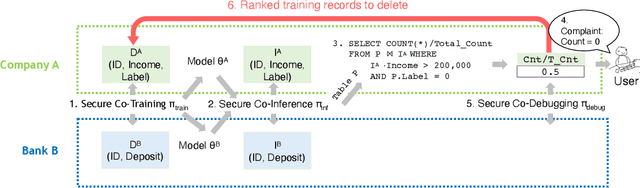


How can we debug a logistical regression model in a federated learning setting when seeing the model behave unexpectedly (e.g., the model rejects all high-income customers' loan applications)? The SQL-based training data debugging framework has proved effective to fix this kind of issue in a non-federated learning setting. Given an unexpected query result over model predictions, this framework automatically removes the label errors from training data such that the unexpected behavior disappears in the retrained model. In this paper, we enable this powerful framework for federated learning. The key challenge is how to develop a security protocol for federated debugging which is proved to be secure, efficient, and accurate. Achieving this goal requires us to investigate how to seamlessly integrate the techniques from multiple fields (Databases, Machine Learning, and Cybersecurity). We first propose FedRain, which extends Rain, the state-of-the-art SQL-based training data debugging framework, to our federated learning setting. We address several technical challenges to make FedRain work and analyze its security guarantee and time complexity. The analysis results show that FedRain falls short in terms of both efficiency and security. To overcome these limitations, we redesign our security protocol and propose Frog, a novel SQL-based training data debugging framework tailored for federated learning. Our theoretical analysis shows that Frog is more secure, more accurate, and more efficient than FedRain. We conduct extensive experiments using several real-world datasets and a case study. The experimental results are consistent with our theoretical analysis and validate the effectiveness of Frog in practice.
Model Trees for Identifying Exceptional Players in the NHL Draft
Feb 23, 2018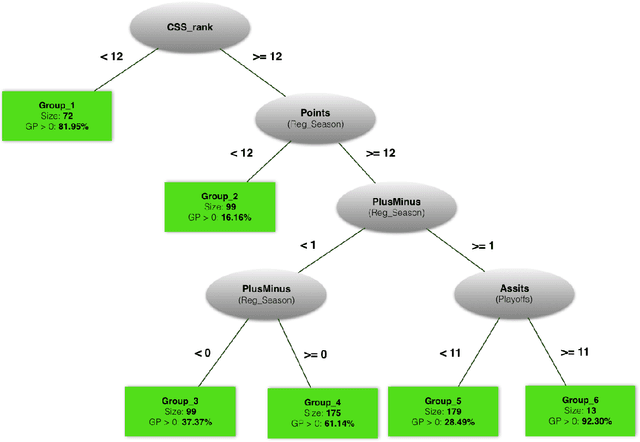
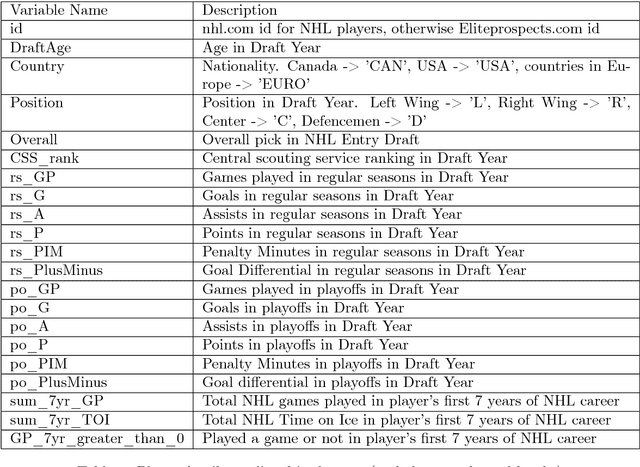

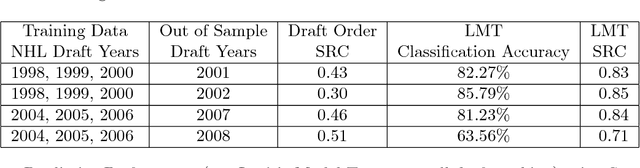
Drafting strong players is crucial for the team success. We describe a new data-driven interpretable approach for assessing draft prospects in the National Hockey League. Successful previous approaches have built a predictive model based on player features, or derived performance predictions from the observed performance of comparable players in a cohort. This paper develops model tree learning, which incorporates strengths of both model-based and cohort-based approaches. A model tree partitions the feature space according to the values of discrete features, or learned thresholds for continuous features. Each leaf node in the tree defines a group of players, easily described to hockey experts, with its own group regression model. Compared to a single model, the model tree forms an ensemble that increases predictive power. Compared to cohort-based approaches, the groups of comparables are discovered from the data, without requiring a similarity metric. The performance predictions of the model tree are competitive with the state-of-the-art methods, which validates our model empirically. We show in case studies that the model tree player ranking can be used to highlight strong and weak points of players.