 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Weight Initialization for Hypernetworks
Dec 13, 2023Hypernetworks are meta neural networks that generate weights for a main neural network in an end-to-end differentiable manner. Despite extensive applications ranging from multi-task learning to Bayesian deep learning, the problem of optimizing hypernetworks has not been studied to date. We observe that classical weight initialization methods like Glorot & Bengio (2010) and He et al. (2015), when applied directly on a hypernet, fail to produce weights for the mainnet in the correct scale. We develop principled techniques for weight initialization in hypernets, and show that they lead to more stable mainnet weights, lower training loss, and faster convergence.
Assessing SATNet's Ability to Solve the Symbol Grounding Problem
Dec 13, 2023SATNet is an award-winning MAXSAT solver that can be used to infer logical rules and integrated as a differentiable layer in a deep neural network. It had been shown to solve Sudoku puzzles visually from examples of puzzle digit images, and was heralded as an impressive achievement towards the longstanding AI goal of combining pattern recognition with logical reasoning. In this paper, we clarify SATNet's capabilities by showing that in the absence of intermediate labels that identify individual Sudoku digit images with their logical representations, SATNet completely fails at visual Sudoku (0% test accuracy). More generally, the failure can be pinpointed to its inability to learn to assign symbols to perceptual phenomena, also known as the symbol grounding problem, which has long been thought to be a prerequisite for intelligent agents to perform real-world logical reasoning. We propose an MNIST based test as an easy instance of the symbol grounding problem that can serve as a sanity check for differentiable symbolic solvers in general. Naive applications of SATNet on this test lead to performance worse than that of models without logical reasoning capabilities. We report on the causes of SATNet's failure and how to prevent them.
Chaos persists in large-scale multi-agent learning despite adaptive learning rates
Jun 01, 2023



Multi-agent learning is intrinsically harder, more unstable and unpredictable than single agent optimization. For this reason, numerous specialized heuristics and techniques have been designed towards the goal of achieving convergence to equilibria in self-play. One such celebrated approach is the use of dynamically adaptive learning rates. Although such techniques are known to allow for improved convergence guarantees in small games, it has been much harder to analyze them in more relevant settings with large populations of agents. These settings are particularly hard as recent work has established that learning with fixed rates will become chaotic given large enough populations.In this work, we show that chaos persists in large population congestion games despite using adaptive learning rates even for the ubiquitous Multiplicative Weight Updates algorithm, even in the presence of only two strategies. At a technical level, due to the non-autonomous nature of the system, our approach goes beyond conventional period-three techniques Li-Yorke by studying fundamental properties of the dynamics including invariant sets, volume expansion and turbulent sets. We complement our theoretical insights with experiments showcasing that slight variations to system parameters lead to a wide variety of unpredictable behaviors.
Enabling SQL-based Training Data Debugging for Federated Learning
Aug 26, 2021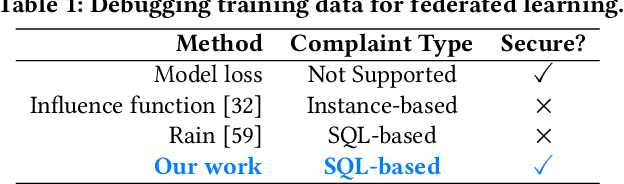
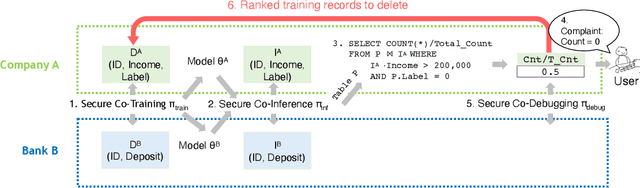


How can we debug a logistical regression model in a federated learning setting when seeing the model behave unexpectedly (e.g., the model rejects all high-income customers' loan applications)? The SQL-based training data debugging framework has proved effective to fix this kind of issue in a non-federated learning setting. Given an unexpected query result over model predictions, this framework automatically removes the label errors from training data such that the unexpected behavior disappears in the retrained model. In this paper, we enable this powerful framework for federated learning. The key challenge is how to develop a security protocol for federated debugging which is proved to be secure, efficient, and accurate. Achieving this goal requires us to investigate how to seamlessly integrate the techniques from multiple fields (Databases, Machine Learning, and Cybersecurity). We first propose FedRain, which extends Rain, the state-of-the-art SQL-based training data debugging framework, to our federated learning setting. We address several technical challenges to make FedRain work and analyze its security guarantee and time complexity. The analysis results show that FedRain falls short in terms of both efficiency and security. To overcome these limitations, we redesign our security protocol and propose Frog, a novel SQL-based training data debugging framework tailored for federated learning. Our theoretical analysis shows that Frog is more secure, more accurate, and more efficient than FedRain. We conduct extensive experiments using several real-world datasets and a case study. The experimental results are consistent with our theoretical analysis and validate the effectiveness of Frog in practice.
Solving Min-Max Optimization with Hidden Structure via Gradient Descent Ascent
Jan 13, 2021


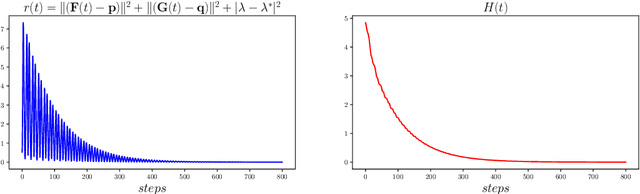
Many recent AI architectures are inspired by zero-sum games, however, the behavior of their dynamics is still not well understood. Inspired by this, we study standard gradient descent ascent (GDA) dynamics in a specific class of non-convex non-concave zero-sum games, that we call hidden zero-sum games. In this class, players control the inputs of smooth but possibly non-linear functions whose outputs are being applied as inputs to a convex-concave game. Unlike general zero-sum games, these games have a well-defined notion of solution; outcomes that implement the von-Neumann equilibrium of the "hidden" convex-concave game. We prove that if the hidden game is strictly convex-concave then vanilla GDA converges not merely to local Nash, but typically to the von-Neumann solution. If the game lacks strict convexity properties, GDA may fail to converge to any equilibrium, however, by applying standard regularization techniques we can prove convergence to a von-Neumann solution of a slightly perturbed zero-sum game. Our convergence guarantees are non-local, which as far as we know is a first-of-its-kind type of result in non-convex non-concave games. Finally, we discuss connections of our framework with generative adversarial networks.
No-regret learning and mixed Nash equilibria: They do not mix
Oct 20, 2020

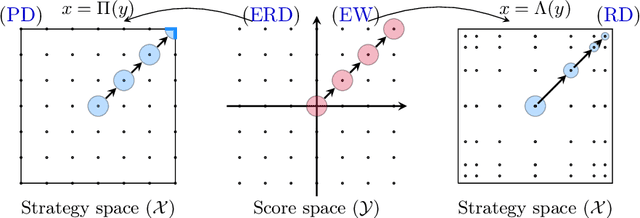
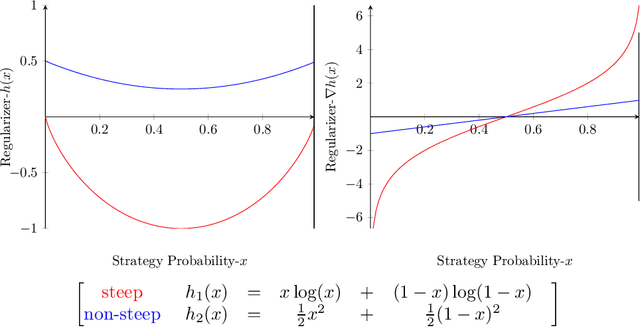
Understanding the behavior of no-regret dynamics in general $N$-player games is a fundamental question in online learning and game theory. A folk result in the field states that, in finite games, the empirical frequency of play under no-regret learning converges to the game's set of coarse correlated equilibria. By contrast, our understanding of how the day-to-day behavior of the dynamics correlates to the game's Nash equilibria is much more limited, and only partial results are known for certain classes of games (such as zero-sum or congestion games). In this paper, we study the dynamics of "follow-the-regularized-leader" (FTRL), arguably the most well-studied class of no-regret dynamics, and we establish a sweeping negative result showing that the notion of mixed Nash equilibrium is antithetical to no-regret learning. Specifically, we show that any Nash equilibrium which is not strict (in that every player has a unique best response) cannot be stable and attracting under the dynamics of FTRL. This result has significant implications for predicting the outcome of a learning process as it shows unequivocally that only strict (and hence, pure) Nash equilibria can emerge as stable limit points thereof.
Complaint-driven Training Data Debugging for Query 2.0
Apr 12, 2020As the need for machine learning (ML) increases rapidly across all industry sectors, there is a significant interest among commercial database providers to support "Query 2.0", which integrates model inference into SQL queries. Debugging Query 2.0 is very challenging since an unexpected query result may be caused by the bugs in training data (e.g., wrong labels, corrupted features). In response, we propose Rain, a complaint-driven training data debugging system. Rain allows users to specify complaints over the query's intermediate or final output, and aims to return a minimum set of training examples so that if they were removed, the complaints would be resolved. To the best of our knowledge, we are the first to study this problem. A naive solution requires retraining an exponential number of ML models. We propose two novel heuristic approaches based on influence functions which both require linear retraining steps. We provide an in-depth analytical and empirical analysis of the two approaches and conduct extensive experiments to evaluate their effectiveness using four real-world datasets. Results show that Rain achieves the highest recall@k among all the baselines while still returns results interactively.
Efficiently avoiding saddle points with zero order methods: No gradients required
Oct 29, 2019


We consider the case of derivative-free algorithms for non-convex optimization, also known as zero order algorithms, that use only function evaluations rather than gradients. For a wide variety of gradient approximators based on finite differences, we establish asymptotic convergence to second order stationary points using a carefully tailored application of the Stable Manifold Theorem. Regarding efficiency, we introduce a noisy zero-order method that converges to second order stationary points, i.e avoids saddle points. Our algorithm uses only $\tilde{\mathcal{O}}(1 / \epsilon^2)$ approximate gradient calculations and, thus, it matches the converge rate guarantees of their exact gradient counterparts up to constants. In contrast to previous work, our convergence rate analysis avoids imposing additional dimension dependent slowdowns in the number of iterations required for non-convex zero order optimization.
Poincaré Recurrence, Cycles and Spurious Equilibria in Gradient-Descent-Ascent for Non-Convex Non-Concave Zero-Sum Games
Oct 28, 2019


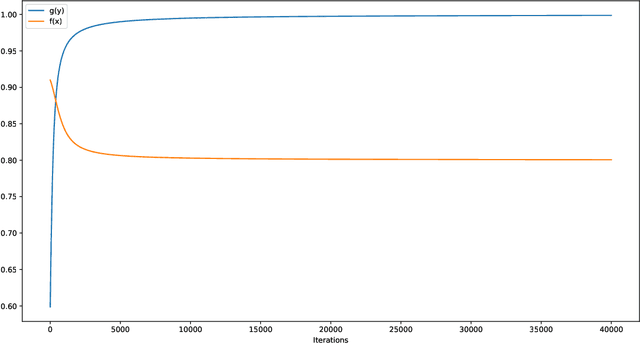
We study a wide class of non-convex non-concave min-max games that generalizes over standard bilinear zero-sum games. In this class, players control the inputs of a smooth function whose output is being applied to a bilinear zero-sum game. This class of games is motivated by the indirect nature of the competition in Generative Adversarial Networks, where players control the parameters of a neural network while the actual competition happens between the distributions that the generator and discriminator capture. We establish theoretically, that depending on the specific instance of the problem gradient-descent-ascent dynamics can exhibit a variety of behaviors antithetical to convergence to the game theoretically meaningful min-max solution. Specifically, different forms of recurrent behavior (including periodicity and Poincar\'e recurrence) are possible as well as convergence to spurious (non-min-max) equilibria for a positive measure of initial conditions. At the technical level, our analysis combines tools from optimization theory, game theory and dynamical systems.