 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling SQL-based Training Data Debugging for Federated Learning
Aug 26, 2021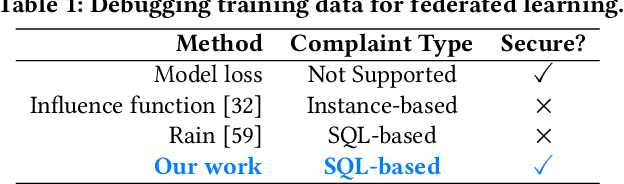
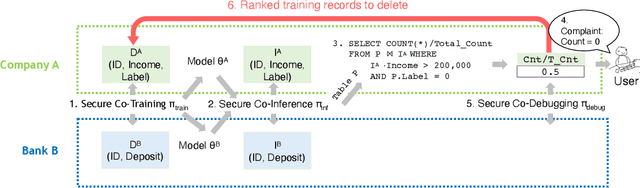


How can we debug a logistical regression model in a federated learning setting when seeing the model behave unexpectedly (e.g., the model rejects all high-income customers' loan applications)? The SQL-based training data debugging framework has proved effective to fix this kind of issue in a non-federated learning setting. Given an unexpected query result over model predictions, this framework automatically removes the label errors from training data such that the unexpected behavior disappears in the retrained model. In this paper, we enable this powerful framework for federated learning. The key challenge is how to develop a security protocol for federated debugging which is proved to be secure, efficient, and accurate. Achieving this goal requires us to investigate how to seamlessly integrate the techniques from multiple fields (Databases, Machine Learning, and Cybersecurity). We first propose FedRain, which extends Rain, the state-of-the-art SQL-based training data debugging framework, to our federated learning setting. We address several technical challenges to make FedRain work and analyze its security guarantee and time complexity. The analysis results show that FedRain falls short in terms of both efficiency and security. To overcome these limitations, we redesign our security protocol and propose Frog, a novel SQL-based training data debugging framework tailored for federated learning. Our theoretical analysis shows that Frog is more secure, more accurate, and more efficient than FedRain. We conduct extensive experiments using several real-world datasets and a case study. The experimental results are consistent with our theoretical analysis and validate the effectiveness of Frog in practice.
Explaining Inference Queries with Bayesian Optimization
Feb 10, 2021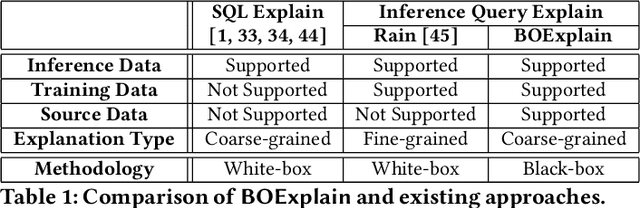
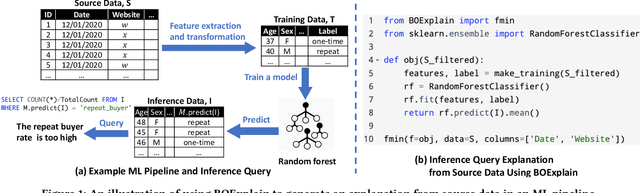
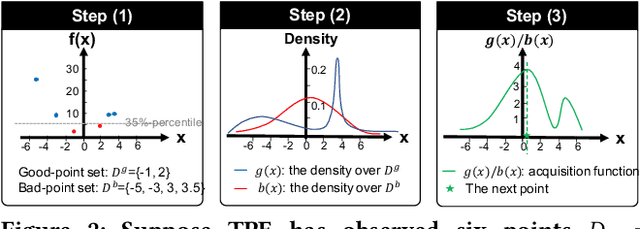
Obtaining an explanation for an SQL query result can enrich the analysis experience, reveal data errors, and provide deeper insight into the data. Inference query explanation seeks to explain unexpected aggregate query results on inference data; such queries are challenging to explain because an explanation may need to be derived from the source, training, or inference data in an ML pipeline. In this paper, we model an objective function as a black-box function and propose BOExplain, a novel framework for explaining inference queries using Bayesian optimization (BO). An explanation is a predicate defining the input tuples that should be removed so that the query result of interest is significantly affected. BO - a technique for finding the global optimum of a black-box function - is used to find the best predicate. We develop two new techniques (individual contribution encoding and warm start) to handle categorical variables. We perform experiments showing that the predicates found by BOExplain have a higher degree of explanation compared to those found by the state-of-the-art query explanation engines. We also show that BOExplain is effective at deriving explanations for inference queries from source and training data on three real-world datasets.
Are We Ready For Learned Cardinality Estimation?
Dec 15, 2020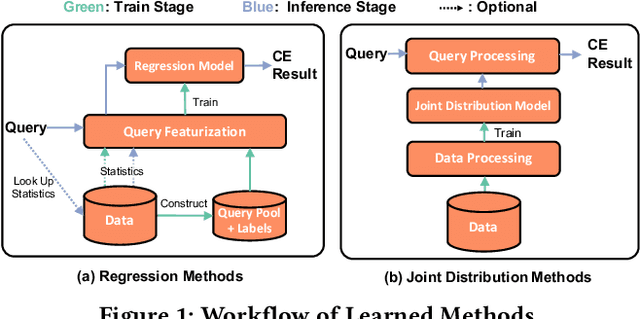
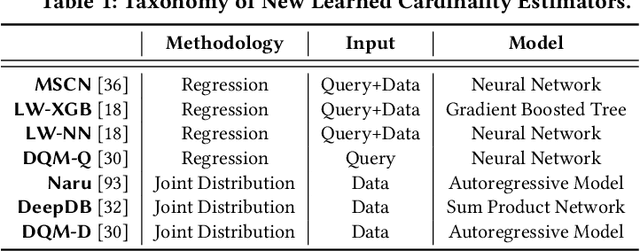
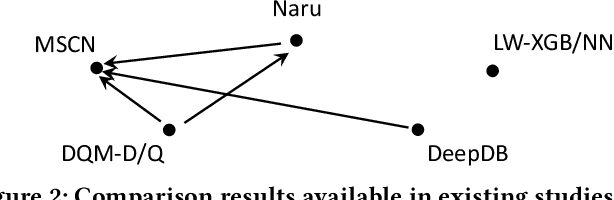
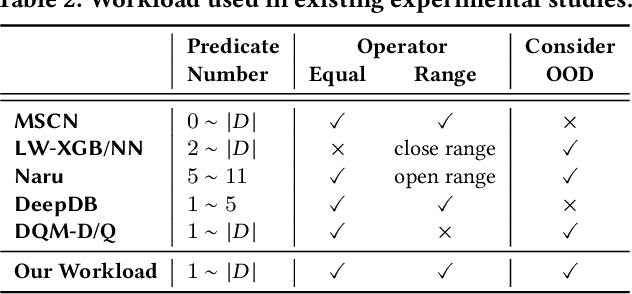
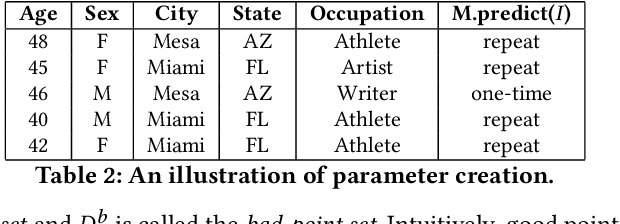
Cardinality estimation is a fundamental but long unresolved problem in query optimization. Recently, multiple papers from different research groups consistently report that learned models have the potential to replace existing cardinality estimators. In this paper, we ask a forward-thinking question: Are we ready to deploy these learned cardinality models in production? Our study consists of three main parts. Firstly, we focus on the static environment (i.e., no data updates) and compare five new learned methods with eight traditional methods on four real-world datasets under a unified workload setting. The results show that learned models are indeed more accurate than traditional methods, but they often suffer from high training and inference costs. Secondly, we explore whether these learned models are ready for dynamic environments (i.e., frequent data updates). We find that they cannot catch up with fast data up-dates and return large errors for different reasons. For less frequent updates, they can perform better but there is no clear winner among themselves. Thirdly, we take a deeper look into learned models and explore when they may go wrong. Our results show that the performance of learned methods can be greatly affected by the changes in correlation, skewness, or domain size. More importantly, their behaviors are much harder to interpret and often unpredictable. Based on these findings, we identify two promising research directions (control the cost of learned models and make learned models trustworthy) and suggest a number of research opportunities. We hope that our study can guide researchers and practitioners to work together to eventually push learned cardinality estimators into real database systems.
Complaint-driven Training Data Debugging for Query 2.0
Apr 12, 2020As the need for machine learning (ML) increases rapidly across all industry sectors, there is a significant interest among commercial database providers to support "Query 2.0", which integrates model inference into SQL queries. Debugging Query 2.0 is very challenging since an unexpected query result may be caused by the bugs in training data (e.g., wrong labels, corrupted features). In response, we propose Rain, a complaint-driven training data debugging system. Rain allows users to specify complaints over the query's intermediate or final output, and aims to return a minimum set of training examples so that if they were removed, the complaints would be resolved. To the best of our knowledge, we are the first to study this problem. A naive solution requires retraining an exponential number of ML models. We propose two novel heuristic approaches based on influence functions which both require linear retraining steps. We provide an in-depth analytical and empirical analysis of the two approaches and conduct extensive experiments to evaluate their effectiveness using four real-world datasets. Results show that Rain achieves the highest recall@k among all the baselines while still returns results interactively.