 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpacts Towards a comprehensive assessment of the book impact by integrating multiple evaluation sources
Jul 22, 2021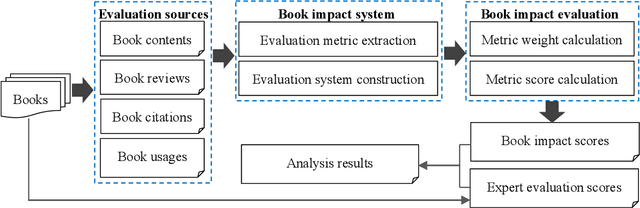
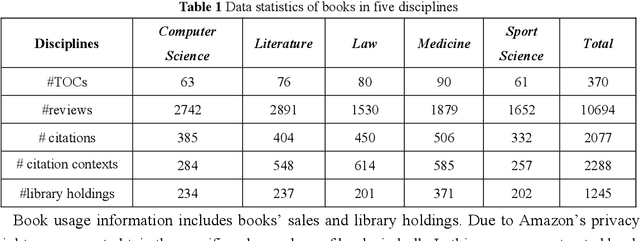

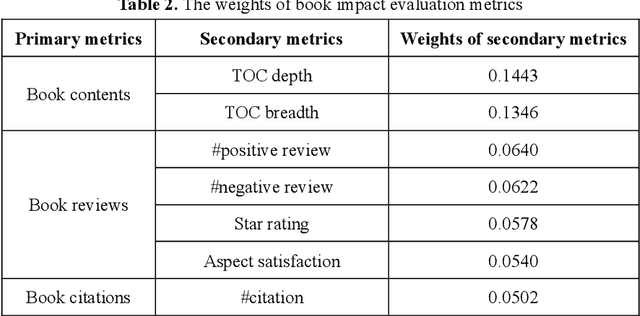
The surge in the number of books published makes the manual evaluation methods difficult to efficiently evaluate books. The use of books' citations and alternative evaluation metrics can assist manual evaluation and reduce the cost of evaluation. However, most existing evaluation research was based on a single evaluation source with coarse-grained analysis, which may obtain incomprehensive or one-sided evaluation results of book impact. Meanwhile, relying on a single resource for book assessment may lead to the risk that the evaluation results cannot be obtained due to the lack of the evaluation data, especially for newly published books. Hence, this paper measured book impact based on an evaluation system constructed by integrating multiple evaluation sources. Specifically, we conducted finer-grained mining on the multiple evaluation sources, including books' internal evaluation resources and external evaluation resources. Various technologies (e.g. topic extraction, sentiment analysis, text classification) were used to extract corresponding evaluation metrics from the internal and external evaluation resources. Then, Expert evaluation combined with analytic hierarchy process was used to integrate the evaluation metrics and construct a book impact evaluation system. Finally, the reliability of the evaluation system was verified by comparing with the results of expert evaluation, detailed and diversified evaluation results were then obtained. The experimental results reveal that differential evaluation resources can measure the books' impacts from different dimensions, and the integration of multiple evaluation data can assess books more comprehensively. Meanwhile, the book impact evaluation system can provide personalized evaluation results according to the users' evaluation purposes. In addition, the disciplinary differences should be considered for assessing books' impacts.
Breaking Community Boundary: Comparing Academic and Social Communication Preferences regarding Global Pandemics
Apr 12, 2021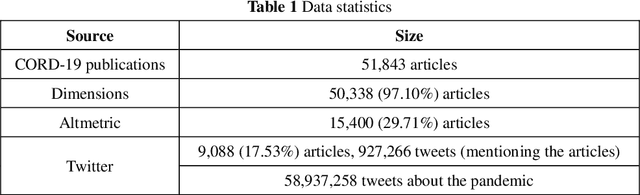
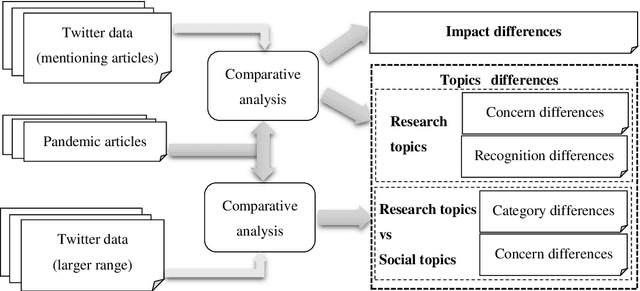
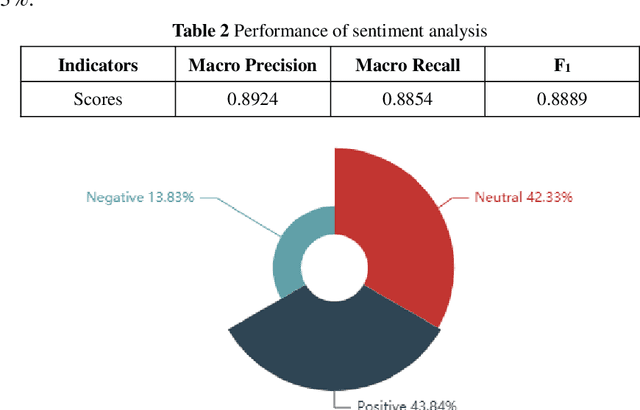
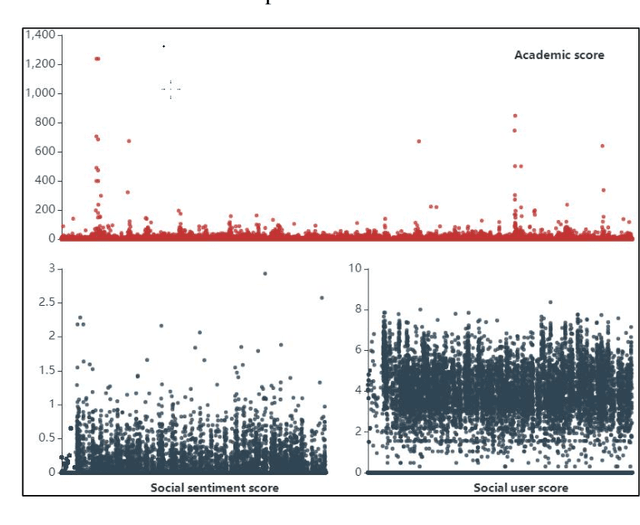
The global spread of COVID-19 has caused pandemics to be widely discussed. This is evident in the large number of scientific articles and the amount of user-generated content on social media. This paper aims to compare academic communication and social communication about the pandemic from the perspective of communication preference differences. It aims to provide information for the ongoing research on global pandemics, thereby eliminating knowledge barriers and information inequalities between the academic and the social communities. First, we collected the full text and the metadata of pandemic-related articles and Twitter data mentioning the articles. Second, we extracted and analyzed the topics and sentiment tendencies of the articles and related tweets. Finally, we conducted pandemic-related differential analysis on the academic community and the social community. We mined the resulting data to generate pandemic communication preferences (e.g., information needs, attitude tendencies) of researchers and the public, respectively. The research results from 50,338 articles and 927,266 corresponding tweets mentioning the articles revealed communication differences about global pandemics between the academic and the social communities regarding the consistency of research recognition and the preferences for particular research topics. The analysis of large-scale pandemic-related tweets also confirmed the communication preference differences between the two communities.
Are We Ready For Learned Cardinality Estimation?
Dec 15, 2020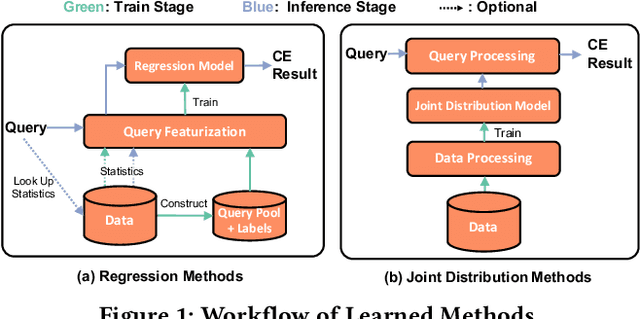
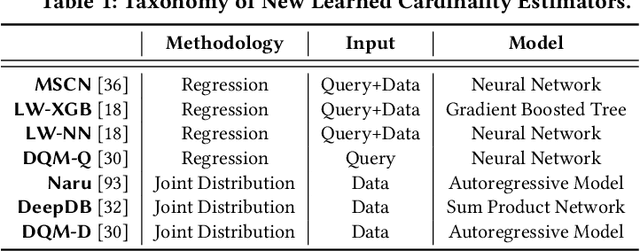
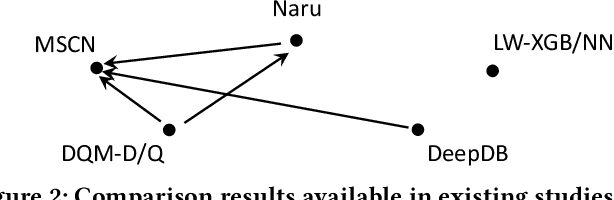
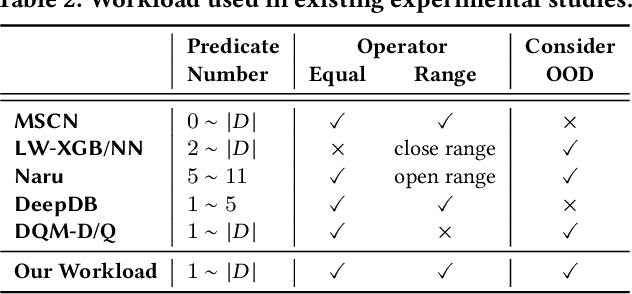
Cardinality estimation is a fundamental but long unresolved problem in query optimization. Recently, multiple papers from different research groups consistently report that learned models have the potential to replace existing cardinality estimators. In this paper, we ask a forward-thinking question: Are we ready to deploy these learned cardinality models in production? Our study consists of three main parts. Firstly, we focus on the static environment (i.e., no data updates) and compare five new learned methods with eight traditional methods on four real-world datasets under a unified workload setting. The results show that learned models are indeed more accurate than traditional methods, but they often suffer from high training and inference costs. Secondly, we explore whether these learned models are ready for dynamic environments (i.e., frequent data updates). We find that they cannot catch up with fast data up-dates and return large errors for different reasons. For less frequent updates, they can perform better but there is no clear winner among themselves. Thirdly, we take a deeper look into learned models and explore when they may go wrong. Our results show that the performance of learned methods can be greatly affected by the changes in correlation, skewness, or domain size. More importantly, their behaviors are much harder to interpret and often unpredictable. Based on these findings, we identify two promising research directions (control the cost of learned models and make learned models trustworthy) and suggest a number of research opportunities. We hope that our study can guide researchers and practitioners to work together to eventually push learned cardinality estimators into real database systems.
Measuring Book Impact Based on the Multi-granularity Online Review Mining
Mar 26, 2016
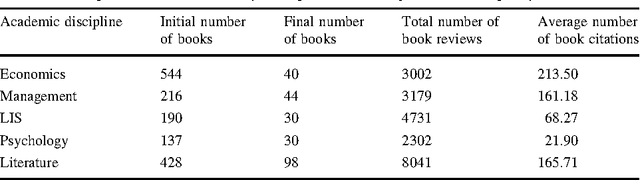
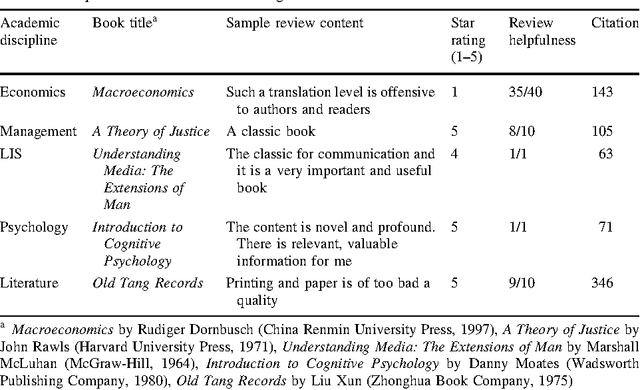
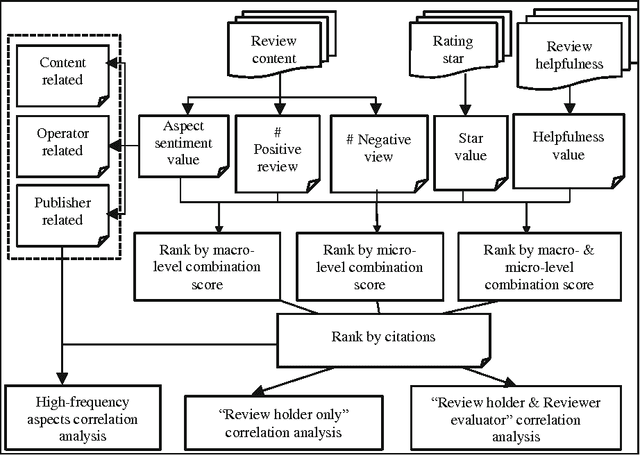
As with articles and journals, the customary methods for measuring books' academic impact mainly involve citations, which is easy but limited to interrogating traditional citation databases and scholarly book reviews, Researchers have attempted to use other metrics, such as Google Books, libcitation, and publisher prestige. However, these approaches lack content-level information and cannot determine the citation intentions of users. Meanwhile, the abundant online review resources concerning academic books can be used to mine deeper information and content utilizing altmetric perspectives. In this study, we measure the impacts of academic books by multi-granularity mining online reviews, and we identify factors that affect a book's impact. First, online reviews of a sample of academic books on Amazon.cn are crawled and processed. Then, multi-granularity review mining is conducted to identify review sentiment polarities and aspects' sentiment values. Lastly, the numbers of positive reviews and negative reviews, aspect sentiment values, star values, and information regarding helpfulness are integrated via the entropy method, and lead to the calculation of the final book impact scores. The results of a correlation analysis of book impact scores obtained via our method versus traditional book citations show that, although there are substantial differences between subject areas, online book reviews tend to reflect the academic impact. Thus, we infer that online reviews represent a promising source for mining book impact within the altmetric perspective and at the multi-granularity content level. Moreover, our proposed method might also be a means by which to measure other books besides academic publications.
Online shopping behavior study based on multi-granularity opinion mining: China vs. America
Mar 26, 2016
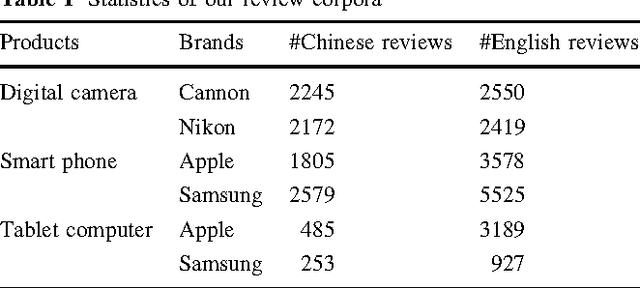
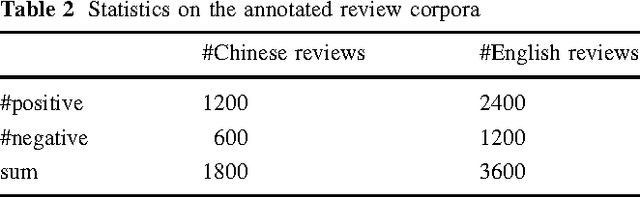
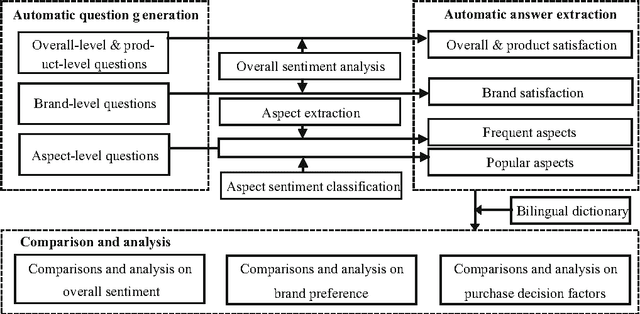
With the development of e-commerce, many products are now being sold worldwide, and manufacturers are eager to obtain a better understanding of customer behavior in various regions. To achieve this goal, most previous efforts have focused mainly on questionnaires, which are time-consuming and costly. The tremendous volume of product reviews on e-commerce websites has seen a new trend emerge, whereby manufacturers attempt to understand user preferences by analyzing online reviews. Following this trend, this paper addresses the problem of studying customer behavior by exploiting recently developed opinion mining techniques. This work is novel for three reasons. First, questionnaire-based investigation is automatically enabled by employing algorithms for template-based question generation and opinion mining-based answer extraction. Using this system, manufacturers are able to obtain reports of customer behavior featuring a much larger sample size, more direct information, a higher degree of automation, and a lower cost. Second, international customer behavior study is made easier by integrating tools for multilingual opinion mining. Third, this is the first time an automatic questionnaire investigation has been conducted to compare customer behavior in China and America, where product reviews are written and read in Chinese and English, respectively. Our study on digital cameras, smartphones, and tablet computers yields three findings. First, Chinese customers follow the Doctrine of the Mean, and often use euphemistic expressions, while American customers express their opinions more directly. Second, Chinese customers care more about general feelings, while American customers pay more attention to product details. Third, Chinese customers focus on external features, while American customers care more about the internal features of products.