 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeClear: Reliable Transparent Object Depth Estimation via Generative Opacification
Mar 20, 2026Monocular depth estimation remains challenging for transparent objects, where refraction and transmission are difficult to model and break the appearance assumptions used by depth networks. As a result, state-of-the-art estimators often produce unstable or incorrect depth predictions for transparent materials. We propose SeeClear, a novel framework that converts transparent objects into generative opaque images, enabling stable monocular depth estimation for transparent objects. Given an input image, we first localize transparent regions and transform their refractive appearance into geometrically consistent opaque shapes using a diffusion-based generative opacification module. The processed image is then fed into an off-the-shelf monocular depth estimator without retraining or architectural changes. To train the opacification model, we construct SeeClear-396k, a synthetic dataset containing 396k paired transparent-opaque renderings. Experiments on both synthetic and real-world datasets show that SeeClear significantly improves depth estimation for transparent objects. Project page: https://heyumeng.com/SeeClear-web/
GDSR: Global-Detail Integration through Dual-Branch Network with Wavelet Losses for Remote Sensing Image Super-Resolution
Jan 07, 2025In recent years, deep neural networks, including Convolutional Neural Networks, Transformers, and State Space Models, have achieved significant progress in Remote Sensing Image (RSI) Super-Resolution (SR). However, existing SR methods typically overlook the complementary relationship between global and local dependencies. These methods either focus on capturing local information or prioritize global information, which results in models that are unable to effectively capture both global and local features simultaneously. Moreover, their computational cost becomes prohibitive when applied to large-scale RSIs. To address these challenges, we introduce the novel application of Receptance Weighted Key Value (RWKV) to RSI-SR, which captures long-range dependencies with linear complexity. To simultaneously model global and local features, we propose the Global-Detail dual-branch structure, GDSR, which performs SR reconstruction by paralleling RWKV and convolutional operations to handle large-scale RSIs. Furthermore, we introduce the Global-Detail Reconstruction Module (GDRM) as an intermediary between the two branches to bridge their complementary roles. In addition, we propose Wavelet Loss, a loss function that effectively captures high-frequency detail information in images, thereby enhancing the visual quality of SR, particularly in terms of detail reconstruction. Extensive experiments on several benchmarks, including AID, AID_CDM, RSSRD-QH, and RSSRD-QH_CDM, demonstrate that GSDR outperforms the state-of-the-art Transformer-based method HAT by an average of 0.05 dB in PSNR, while using only 63% of its parameters and 51% of its FLOPs, achieving an inference speed 2.9 times faster. Furthermore, the Wavelet Loss shows excellent generalization across various architectures, providing a novel perspective for RSI-SR enhancement.
Research on Violent Text Detection System Based on BERT-fasttext Model
Dec 21, 2024



In the digital age of today, the internet has become an indispensable platform for people's lives, work, and information exchange. However, the problem of violent text proliferation in the network environment has arisen, which has brought about many negative effects. In view of this situation, it is particularly important to build an effective system for cutting off violent text. The study of violent text cutting off based on the BERT-fasttext model has significant meaning. BERT is a pre-trained language model with strong natural language understanding ability, which can deeply mine and analyze text semantic information; Fasttext itself is an efficient text classification tool with low complexity and good effect, which can quickly provide basic judgments for text processing. By combining the two and applying them to the system for cutting off violent text, on the one hand, it can accurately identify violent text, and on the other hand, it can efficiently and reasonably cut off the content, preventing harmful information from spreading freely on the network. Compared with the single BERT model and fasttext, the accuracy was improved by 0.7% and 0.8%, respectively. Through this model, it is helpful to purify the network environment, maintain the health of network information, and create a positive, civilized, and harmonious online communication space for netizens, driving the development of social networking, information dissemination, and other aspects in a more benign direction.
MSCPT: Few-shot Whole Slide Image Classification with Multi-scale and Context-focused Prompt Tuning
Aug 21, 2024



Multiple instance learning (MIL) has become a standard paradigm for weakly supervised classification of whole slide images (WSI). However, this paradigm relies on the use of a large number of labelled WSIs for training. The lack of training data and the presence of rare diseases present significant challenges for these methods. Prompt tuning combined with the pre-trained Vision-Language models (VLMs) is an effective solution to the Few-shot Weakly Supervised WSI classification (FSWC) tasks. Nevertheless, applying prompt tuning methods designed for natural images to WSIs presents three significant challenges: 1) These methods fail to fully leverage the prior knowledge from the VLM's text modality; 2) They overlook the essential multi-scale and contextual information in WSIs, leading to suboptimal results; and 3) They lack exploration of instance aggregation methods. To address these problems, we propose a Multi-Scale and Context-focused Prompt Tuning (MSCPT) method for FSWC tasks. Specifically, MSCPT employs the frozen large language model to generate pathological visual language prior knowledge at multi-scale, guiding hierarchical prompt tuning. Additionally, we design a graph prompt tuning module to learn essential contextual information within WSI, and finally, a non-parametric cross-guided instance aggregation module has been introduced to get the WSI-level features. Based on two VLMs, extensive experiments and visualizations on three datasets demonstrated the powerful performance of our MSCPT.
ARFA: An Asymmetric Receptive Field Autoencoder Model for Spatiotemporal Prediction
Sep 01, 2023



Spatiotemporal prediction aims to generate future sequences by paradigms learned from historical contexts. It holds significant importance in numerous domains, including traffic flow prediction and weather forecasting. However, existing methods face challenges in handling spatiotemporal correlations, as they commonly adopt encoder and decoder architectures with identical receptive fields, which adversely affects prediction accuracy. This paper proposes an Asymmetric Receptive Field Autoencoder (ARFA) model to address this issue. Specifically, we design corresponding sizes of receptive field modules tailored to the distinct functionalities of the encoder and decoder. In the encoder, we introduce a large kernel module for global spatiotemporal feature extraction. In the decoder, we develop a small kernel module for local spatiotemporal information reconstruction. To address the scarcity of meteorological prediction data, we constructed the RainBench, a large-scale radar echo dataset specific to the unique precipitation characteristics of inland regions in China for precipitation prediction. Experimental results demonstrate that ARFA achieves consistent state-of-the-art performance on two mainstream spatiotemporal prediction datasets and our RainBench dataset, affirming the effectiveness of our approach. This work not only explores a novel method from the perspective of receptive fields but also provides data support for precipitation prediction, thereby advancing future research in spatiotemporal prediction.
Towards Simultaneous Segmentation of Liver Tumors and Intrahepatic Vessels via Cross-attention Mechanism
Feb 20, 2023Accurate visualization of liver tumors and their surrounding blood vessels is essential for noninvasive diagnosis and prognosis prediction of tumors. In medical image segmentation, there is still a lack of in-depth research on the simultaneous segmentation of liver tumors and peritumoral blood vessels. To this end, we collect the first liver tumor, and vessel segmentation benchmark datasets containing 52 portal vein phase computed tomography images with liver, liver tumor, and vessel annotations. In this case, we propose a 3D U-shaped Cross-Attention Network (UCA-Net) that utilizes a tailored cross-attention mechanism instead of the traditional skip connection to effectively model the encoder and decoder feature. Specifically, the UCA-Net uses a channel-wise cross-attention module to reduce the semantic gap between encoder and decoder and a slice-wise cross-attention module to enhance the contextual semantic learning ability among distinct slices. Experimental results show that the proposed UCA-Net can accurately segment 3D medical images and achieve state-of-the-art performance on the liver tumor and intrahepatic vessel segmentation task.
Are We Ready For Learned Cardinality Estimation?
Dec 15, 2020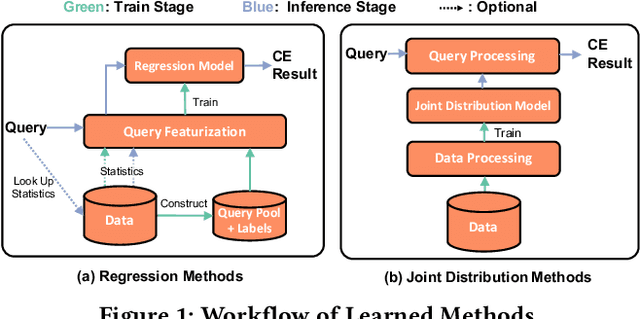
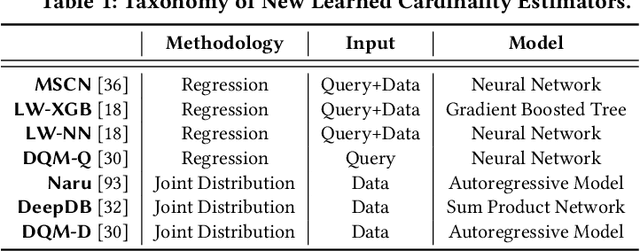
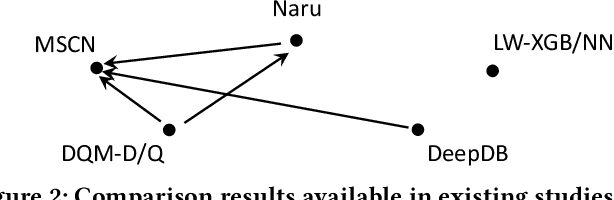
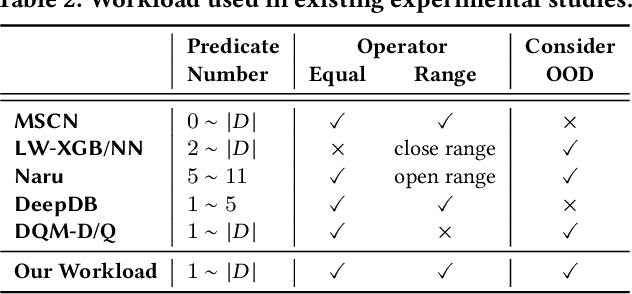
Cardinality estimation is a fundamental but long unresolved problem in query optimization. Recently, multiple papers from different research groups consistently report that learned models have the potential to replace existing cardinality estimators. In this paper, we ask a forward-thinking question: Are we ready to deploy these learned cardinality models in production? Our study consists of three main parts. Firstly, we focus on the static environment (i.e., no data updates) and compare five new learned methods with eight traditional methods on four real-world datasets under a unified workload setting. The results show that learned models are indeed more accurate than traditional methods, but they often suffer from high training and inference costs. Secondly, we explore whether these learned models are ready for dynamic environments (i.e., frequent data updates). We find that they cannot catch up with fast data up-dates and return large errors for different reasons. For less frequent updates, they can perform better but there is no clear winner among themselves. Thirdly, we take a deeper look into learned models and explore when they may go wrong. Our results show that the performance of learned methods can be greatly affected by the changes in correlation, skewness, or domain size. More importantly, their behaviors are much harder to interpret and often unpredictable. Based on these findings, we identify two promising research directions (control the cost of learned models and make learned models trustworthy) and suggest a number of research opportunities. We hope that our study can guide researchers and practitioners to work together to eventually push learned cardinality estimators into real database systems.