 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBQSched: A Non-intrusive Scheduler for Batch Concurrent Queries via Reinforcement Learning
Apr 27, 2025



Most large enterprises build predefined data pipelines and execute them periodically to process operational data using SQL queries for various tasks. A key issue in minimizing the overall makespan of these pipelines is the efficient scheduling of concurrent queries within the pipelines. Existing tools mainly rely on simple heuristic rules due to the difficulty of expressing the complex features and mutual influences of queries. The latest reinforcement learning (RL) based methods have the potential to capture these patterns from feedback, but it is non-trivial to apply them directly due to the large scheduling space, high sampling cost, and poor sample utilization. Motivated by these challenges, we propose BQSched, a non-intrusive Scheduler for Batch concurrent Queries via reinforcement learning. Specifically, BQSched designs an attention-based state representation to capture the complex query patterns, and proposes IQ-PPO, an auxiliary task-enhanced proximal policy optimization (PPO) algorithm, to fully exploit the rich signals of Individual Query completion in logs. Based on the RL framework above, BQSched further introduces three optimization strategies, including adaptive masking to prune the action space, scheduling gain-based query clustering to deal with large query sets, and an incremental simulator to reduce sampling cost. To our knowledge, BQSched is the first non-intrusive batch query scheduler via RL. Extensive experiments show that BQSched can significantly improve the efficiency and stability of batch query scheduling, while also achieving remarkable scalability and adaptability in both data and queries. For example, across all DBMSs and scales tested, BQSched reduces the overall makespan of batch queries on TPC-DS benchmark by an average of 34% and 13%, compared with the commonly used heuristic strategy and the adapted RL-based scheduler, respectively.
Auto-FP: An Experimental Study of Automated Feature Preprocessing for Tabular Data
Oct 04, 2023

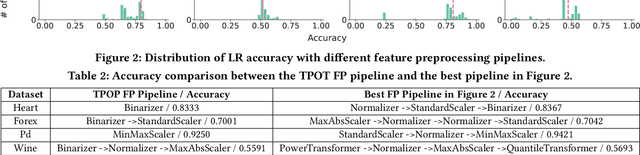

Classical machine learning models, such as linear models and tree-based models, are widely used in industry. These models are sensitive to data distribution, thus feature preprocessing, which transforms features from one distribution to another, is a crucial step to ensure good model quality. Manually constructing a feature preprocessing pipeline is challenging because data scientists need to make difficult decisions about which preprocessors to select and in which order to compose them. In this paper, we study how to automate feature preprocessing (Auto-FP) for tabular data. Due to the large search space, a brute-force solution is prohibitively expensive. To address this challenge, we interestingly observe that Auto-FP can be modelled as either a hyperparameter optimization (HPO) or a neural architecture search (NAS) problem. This observation enables us to extend a variety of HPO and NAS algorithms to solve the Auto-FP problem. We conduct a comprehensive evaluation and analysis of 15 algorithms on 45 public ML datasets. Overall, evolution-based algorithms show the leading average ranking. Surprisingly, the random search turns out to be a strong baseline. Many surrogate-model-based and bandit-based search algorithms, which achieve good performance for HPO and NAS, do not outperform random search for Auto-FP. We analyze the reasons for our findings and conduct a bottleneck analysis to identify the opportunities to improve these algorithms. Furthermore, we explore how to extend Auto-FP to support parameter search and compare two ways to achieve this goal. In the end, we evaluate Auto-FP in an AutoML context and discuss the limitations of popular AutoML tools. To the best of our knowledge, this is the first study on automated feature preprocessing. We hope our work can inspire researchers to develop new algorithms tailored for Auto-FP.
Explaining Inference Queries with Bayesian Optimization
Feb 10, 2021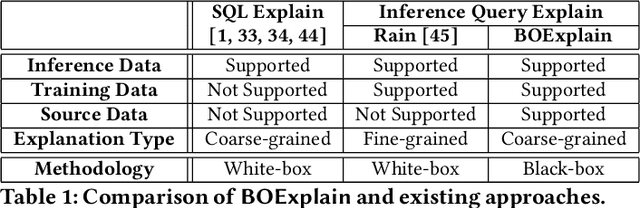
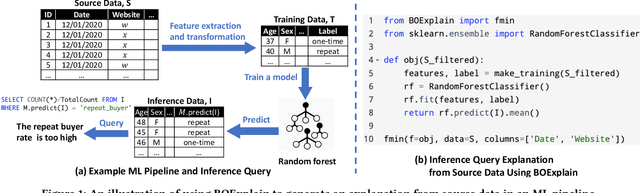
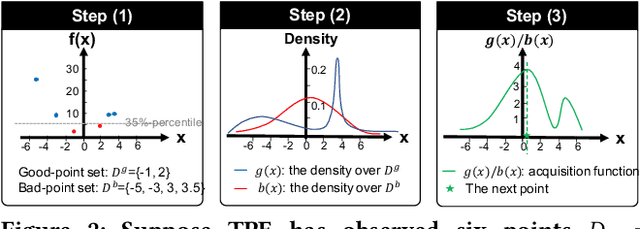
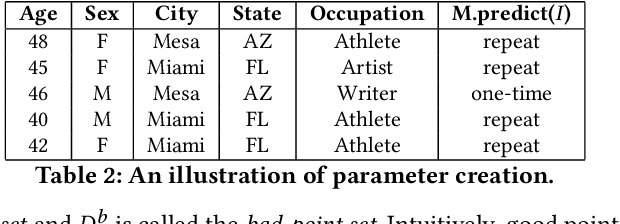
Obtaining an explanation for an SQL query result can enrich the analysis experience, reveal data errors, and provide deeper insight into the data. Inference query explanation seeks to explain unexpected aggregate query results on inference data; such queries are challenging to explain because an explanation may need to be derived from the source, training, or inference data in an ML pipeline. In this paper, we model an objective function as a black-box function and propose BOExplain, a novel framework for explaining inference queries using Bayesian optimization (BO). An explanation is a predicate defining the input tuples that should be removed so that the query result of interest is significantly affected. BO - a technique for finding the global optimum of a black-box function - is used to find the best predicate. We develop two new techniques (individual contribution encoding and warm start) to handle categorical variables. We perform experiments showing that the predicates found by BOExplain have a higher degree of explanation compared to those found by the state-of-the-art query explanation engines. We also show that BOExplain is effective at deriving explanations for inference queries from source and training data on three real-world datasets.