 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Online Learning of Optimal Rankings: Dimensionality Reduction via Gradient Descent
Nov 05, 2020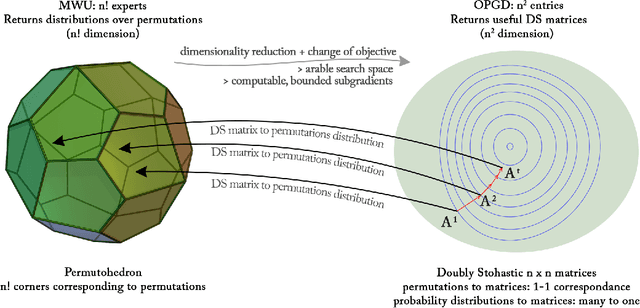
We consider a natural model of online preference aggregation, where sets of preferred items $R_1, R_2, \ldots, R_t$ along with a demand for $k_t$ items in each $R_t$, appear online. Without prior knowledge of $(R_t, k_t)$, the learner maintains a ranking $\pi_t$ aiming that at least $k_t$ items from $R_t$ appear high in $\pi_t$. This is a fundamental problem in preference aggregation with applications to, e.g., ordering product or news items in web pages based on user scrolling and click patterns. The widely studied Generalized Min-Sum-Set-Cover (GMSSC) problem serves as a formal model for the setting above. GMSSC is NP-hard and the standard application of no-regret online learning algorithms is computationally inefficient, because they operate in the space of rankings. In this work, we show how to achieve low regret for GMSSC in polynomial-time. We employ dimensionality reduction from rankings to the space of doubly stochastic matrices, where we apply Online Gradient Descent. A key step is to show how subgradients can be computed efficiently, by solving the dual of a configuration LP. Using oblivious deterministic and randomized rounding schemes, we map doubly stochastic matrices back to rankings with a small loss in the GMSSC objective.
No-regret learning and mixed Nash equilibria: They do not mix
Oct 20, 2020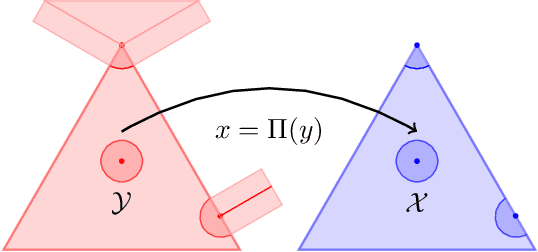

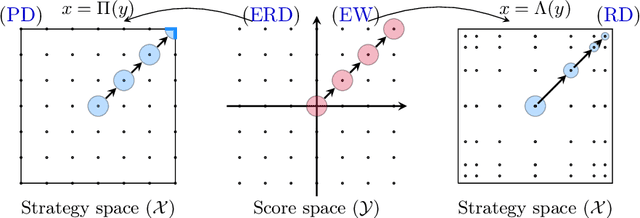
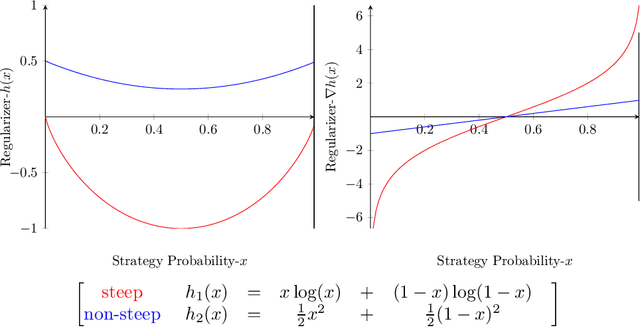
Understanding the behavior of no-regret dynamics in general $N$-player games is a fundamental question in online learning and game theory. A folk result in the field states that, in finite games, the empirical frequency of play under no-regret learning converges to the game's set of coarse correlated equilibria. By contrast, our understanding of how the day-to-day behavior of the dynamics correlates to the game's Nash equilibria is much more limited, and only partial results are known for certain classes of games (such as zero-sum or congestion games). In this paper, we study the dynamics of "follow-the-regularized-leader" (FTRL), arguably the most well-studied class of no-regret dynamics, and we establish a sweeping negative result showing that the notion of mixed Nash equilibrium is antithetical to no-regret learning. Specifically, we show that any Nash equilibrium which is not strict (in that every player has a unique best response) cannot be stable and attracting under the dynamics of FTRL. This result has significant implications for predicting the outcome of a learning process as it shows unequivocally that only strict (and hence, pure) Nash equilibria can emerge as stable limit points thereof.