 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-Regularized Online Optimization with Switching Costs
Dec 11, 2025Fairness and action smoothness are two crucial considerations in many online optimization problems, but they have yet to be addressed simultaneously. In this paper, we study a new and challenging setting of fairness-regularized smoothed online convex optimization with switching costs. First, to highlight the fundamental challenges introduced by the long-term fairness regularizer evaluated based on the entire sequence of actions, we prove that even without switching costs, no online algorithms can possibly achieve a sublinear regret or finite competitive ratio compared to the offline optimal algorithm as the problem episode length $T$ increases. Then, we propose FairOBD (Fairness-regularized Online Balanced Descent), which reconciles the tension between minimizing the hitting cost, switching cost, and fairness cost. Concretely, FairOBD decomposes the long-term fairness cost into a sequence of online costs by introducing an auxiliary variable and then leverages the auxiliary variable to regularize the online actions for fair outcomes. Based on a new approach to account for switching costs, we prove that FairOBD offers a worst-case asymptotic competitive ratio against a novel benchmark -- the optimal offline algorithm with parameterized constraints -- by considering $T\to\infty$. Finally, we run trace-driven experiments of dynamic computing resource provisioning for socially responsible AI inference to empirically evaluate FairOBD, showing that FairOBD can effectively reduce the total fairness-regularized cost and better promote fair outcomes compared to existing baseline solutions.
ConQuER: Modular Architectures for Control and Bias Mitigation in IQP Quantum Generative Models
Sep 26, 2025Quantum generative models based on instantaneous quantum polynomial (IQP) circuits show great promise in learning complex distributions while maintaining classical trainability. However, current implementations suffer from two key limitations: lack of controllability over generated outputs and severe generation bias towards certain expected patterns. We present a Controllable Quantum Generative Framework, ConQuER, which addresses both challenges through a modular circuit architecture. ConQuER embeds a lightweight controller circuit that can be directly combined with pre-trained IQP circuits to precisely control the output distribution without full retraining. Leveraging the advantages of IQP, our scheme enables precise control over properties such as the Hamming Weight distribution with minimal parameter and gate overhead. In addition, inspired by the controller design, we extend this modular approach through data-driven optimization to embed implicit control paths in the underlying IQP architecture, significantly reducing generation bias on structured datasets. ConQuER retains efficient classical training properties and high scalability. We experimentally validate ConQuER on multiple quantum state datasets, demonstrating its superior control accuracy and balanced generation performance, only with very low overhead cost over original IQP circuits. Our framework bridges the gap between the advantages of quantum computing and the practical needs of controllable generation modeling.
ProDiF: Protecting Domain-Invariant Features to Secure Pre-Trained Models Against Extraction
Mar 17, 2025Pre-trained models are valuable intellectual property, capturing both domain-specific and domain-invariant features within their weight spaces. However, model extraction attacks threaten these assets by enabling unauthorized source-domain inference and facilitating cross-domain transfer via the exploitation of domain-invariant features. In this work, we introduce **ProDiF**, a novel framework that leverages targeted weight space manipulation to secure pre-trained models against extraction attacks. **ProDiF** quantifies the transferability of filters and perturbs the weights of critical filters in unsecured memory, while preserving actual critical weights in a Trusted Execution Environment (TEE) for authorized users. A bi-level optimization further ensures resilience against adaptive fine-tuning attacks. Experimental results show that **ProDiF** reduces source-domain accuracy to near-random levels and decreases cross-domain transferability by 74.65\%, providing robust protection for pre-trained models. This work offers comprehensive protection for pre-trained DNN models and highlights the potential of weight space manipulation as a novel approach to model security.
Towards Vector Optimization on Low-Dimensional Vector Symbolic Architecture
Feb 19, 2025



Vector Symbolic Architecture (VSA) is emerging in machine learning due to its efficiency, but they are hindered by issues of hyperdimensionality and accuracy. As a promising mitigation, the Low-Dimensional Computing (LDC) method significantly reduces the vector dimension by ~100 times while maintaining accuracy, by employing a gradient-based optimization. Despite its potential, LDC optimization for VSA is still underexplored. Our investigation into vector updates underscores the importance of stable, adaptive dynamics in LDC training. We also reveal the overlooked yet critical roles of batch normalization (BN) and knowledge distillation (KD) in standard approaches. Besides the accuracy boost, BN does not add computational overhead during inference, and KD significantly enhances inference confidence. Through extensive experiments and ablation studies across multiple benchmarks, we provide a thorough evaluation of our approach and extend the interpretability of binary neural network optimization similar to LDC, previously unaddressed in BNN literature.
Towards Environmentally Equitable AI
Dec 21, 2024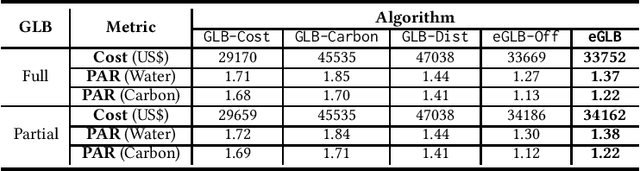
The skyrocketing demand for artificial intelligence (AI) has created an enormous appetite for globally deployed power-hungry servers. As a result, the environmental footprint of AI systems has come under increasing scrutiny. More crucially, the current way that we exploit AI workloads' flexibility and manage AI systems can lead to wildly different environmental impacts across locations, increasingly raising environmental inequity concerns and creating unintended sociotechnical consequences. In this paper, we advocate environmental equity as a priority for the management of future AI systems, advancing the boundaries of existing resource management for sustainable AI and also adding a unique dimension to AI fairness. Concretely, we uncover the potential of equity-aware geographical load balancing to fairly re-distribute the environmental cost across different regions, followed by algorithmic challenges. We conclude by discussing a few future directions to exploit the full potential of system management approaches to mitigate AI's environmental inequity.
A Water Efficiency Dataset for African Data Centers
Dec 04, 2024AI computing and data centers consume a large amount of freshwater, both directly for cooling and indirectly for electricity generation. While most attention has been paid to developed countries such as the U.S., this paper presents the first-of-its-kind dataset that combines nation-level weather and electricity generation data to estimate water usage efficiency for data centers in 41 African countries across five different climate regions. We also use our dataset to evaluate and estimate the water consumption of inference on two large language models (i.e., Llama-3-70B and GPT-4) in 11 selected African countries. Our findings show that writing a 10-page report using Llama-3-70B could consume about \textbf{0.7 liters} of water, while the water consumption by GPT-4 for the same task may go up to about 60 liters. For writing a medium-length email of 120-200 words, Llama-3-70B and GPT-4 could consume about \textbf{0.13 liters} and 3 liters of water, respectively. Interestingly, given the same AI model, 8 out of the 11 selected African countries consume less water than the global average, mainly because of lower water intensities for electricity generation. However, water consumption can be substantially higher in some African countries with a steppe climate than the U.S. and global averages, prompting more attention when deploying AI computing in these countries. Our dataset is publicly available on \href{https://huggingface.co/datasets/masterlion/WaterEfficientDatasetForAfricanCountries/tree/main}{Hugging Face}.
Safe Exploitative Play with Untrusted Type Beliefs
Nov 12, 2024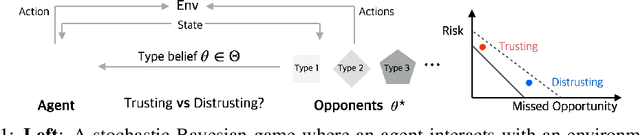

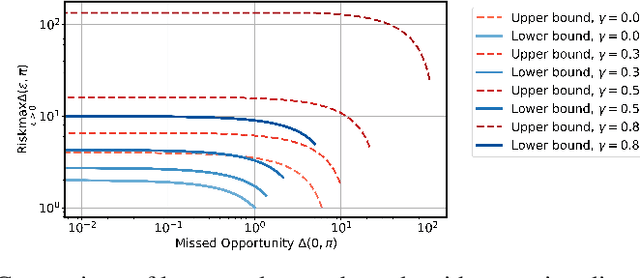

The combination of the Bayesian game and learning has a rich history, with the idea of controlling a single agent in a system composed of multiple agents with unknown behaviors given a set of types, each specifying a possible behavior for the other agents. The idea is to plan an agent's own actions with respect to those types which it believes are most likely to maximize the payoff. However, the type beliefs are often learned from past actions and likely to be incorrect. With this perspective in mind, we consider an agent in a game with type predictions of other components, and investigate the impact of incorrect beliefs to the agent's payoff. In particular, we formally define a tradeoff between risk and opportunity by comparing the payoff obtained against the optimal payoff, which is represented by a gap caused by trusting or distrusting the learned beliefs. Our main results characterize the tradeoff by establishing upper and lower bounds on the Pareto front for both normal-form and stochastic Bayesian games, with numerical results provided.
Online Budgeted Matching with General Bids
Nov 06, 2024



Online Budgeted Matching (OBM) is a classic problem with important applications in online advertising, online service matching, revenue management, and beyond. Traditional online algorithms typically assume a small bid setting, where the maximum bid-to-budget ratio (\kappa) is infinitesimally small. While recent algorithms have tried to address scenarios with non-small or general bids, they often rely on the Fractional Last Matching (FLM) assumption, which allows for accepting partial bids when the remaining budget is insufficient. This assumption, however, does not hold for many applications with indivisible bids. In this paper, we remove the FLM assumption and tackle the open problem of OBM with general bids. We first establish an upper bound of 1-\kappa on the competitive ratio for any deterministic online algorithm. We then propose a novel meta algorithm, called MetaAd, which reduces to different algorithms with first known provable competitive ratios parameterized by the maximum bid-to-budget ratio \kappa \in [0, 1]. As a by-product, we extend MetaAd to the FLM setting and get provable competitive algorithms. Finally, we apply our competitive analysis to the design learning-augmented algorithms.
Bileve: Securing Text Provenance in Large Language Models Against Spoofing with Bi-level Signature
Jun 04, 2024



Text watermarks for large language models (LLMs) have been commonly used to identify the origins of machine-generated content, which is promising for assessing liability when combating deepfake or harmful content. While existing watermarking techniques typically prioritize robustness against removal attacks, unfortunately, they are vulnerable to spoofing attacks: malicious actors can subtly alter the meanings of LLM-generated responses or even forge harmful content, potentially misattributing blame to the LLM developer. To overcome this, we introduce a bi-level signature scheme, Bileve, which embeds fine-grained signature bits for integrity checks (mitigating spoofing attacks) as well as a coarse-grained signal to trace text sources when the signature is invalid (enhancing detectability) via a novel rank-based sampling strategy. Compared to conventional watermark detectors that only output binary results, Bileve can differentiate 5 scenarios during detection, reliably tracing text provenance and regulating LLMs. The experiments conducted on OPT-1.3B and LLaMA-7B demonstrate the effectiveness of Bileve in defeating spoofing attacks with enhanced detectability.
Building Socially-Equitable Public Models
Jun 04, 2024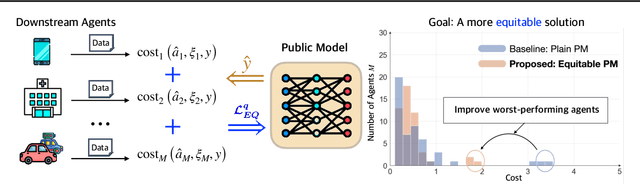
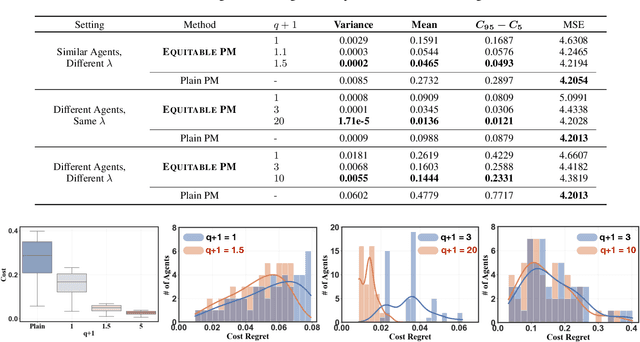
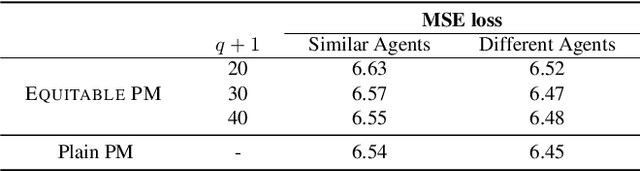
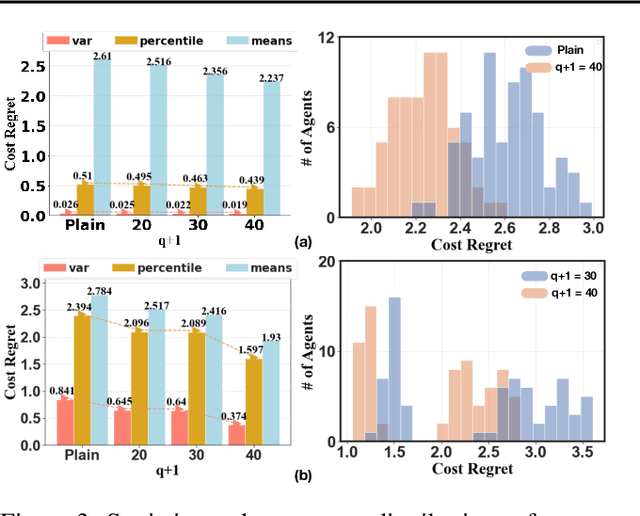
Public models offer predictions to a variety of downstream tasks and have played a crucial role in various AI applications, showcasing their proficiency in accurate predictions. However, the exclusive emphasis on prediction accuracy may not align with the diverse end objectives of downstream agents. Recognizing the public model's predictions as a service, we advocate for integrating the objectives of downstream agents into the optimization process. Concretely, to address performance disparities and foster fairness among heterogeneous agents in training, we propose a novel Equitable Objective. This objective, coupled with a policy gradient algorithm, is crafted to train the public model to produce a more equitable/uniform performance distribution across downstream agents, each with their unique concerns. Both theoretical analysis and empirical case studies have proven the effectiveness of our method in advancing performance equity across diverse downstream agents utilizing the public model for their decision-making. Codes and datasets are released at https://github.com/Ren-Research/Socially-Equitable-Public-Models.