 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSGNeRF: Progressive Dynamic Neural Scene Graph with Frequency Modulated Auto-Encoder in Urban Scenes
Paper and Code
Dec 15, 2023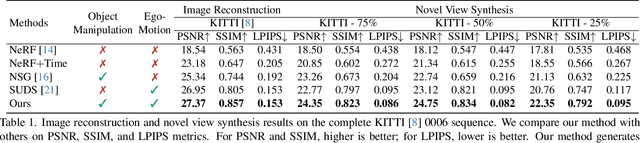
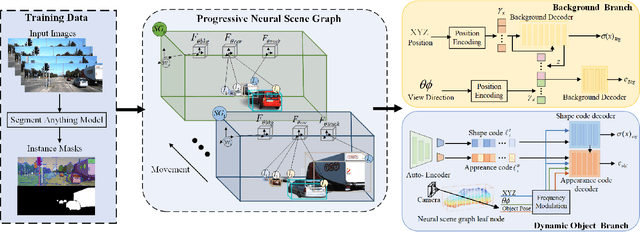
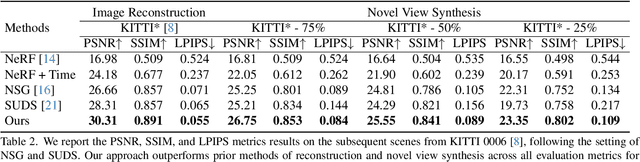
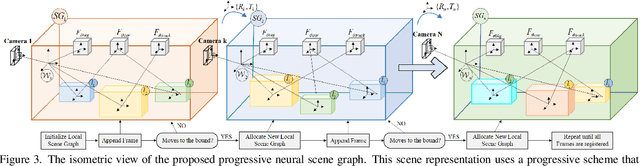
Implicit neural representation has demonstrated promising results in view synthesis for large and complex scenes. However, existing approaches either fail to capture the fast-moving objects or need to build the scene graph without camera ego-motions, leading to low-quality synthesized views of the scene. We aim to jointly solve the view synthesis problem of large-scale urban scenes and fast-moving vehicles, which is more practical and challenging. To this end, we first leverage a graph structure to learn the local scene representations of dynamic objects and the background. Then, we design a progressive scheme that dynamically allocates a new local scene graph trained with frames within a temporal window, allowing us to scale up the representation to an arbitrarily large scene. Besides, the training views of urban scenes are relatively sparse, which leads to a significant decline in reconstruction accuracy for dynamic objects. Therefore, we design a frequency auto-encoder network to encode the latent code and regularize the frequency range of objects, which can enhance the representation of dynamic objects and address the issue of sparse image inputs. Additionally, we employ lidar point projection to maintain geometry consistency in large-scale urban scenes. Experimental results demonstrate that our method achieves state-of-the-art view synthesis accuracy, object manipulation, and scene roaming ability. The code will be open-sourced upon paper acceptance.