 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3-VAE: Reference Vector-Guided Rating Residual Quantization VAE for Generative Recommendation
Apr 14, 2026Generative Recommendation (GR) has gained traction for its merits of superior performance and cold-start capability. As the vital role in GR, Semantic Identifiers (SIDs) represent item semantics through discrete tokens. However, current techniques for SID generation based on vector quantization face two main challenges: (i) training instability, stemming from insufficient gradient propagation through the straight-through estimator and sensitivity to initialization; and (ii) inefficient SID quality assessment, where industrial practice still depends on costly GR training and A/B testing. To address these challenges, we propose Reference Vector-Guided Rating Residual Quantization VAE (R3-VAE). This framework incorporates three key innovations: (i) a reference vector that functions as a semantic anchor for the initial features, thereby mitigating sensitivity to initialization; (ii) a dot product-based rating mechanism designed to stabilize the training process and prevent codebook collapse; and (iii) two SID evaluation metrics, Semantic Cohesion and Preference Discrimination, serving as regularization terms during training. Empirical results on six benchmarks demonstrate that R3-VAE outperforms state-of-the-art methods, achieving an average improvement of 14.2% in Recall@10 and 15.5% in NDCG@10 across three Amazon datasets. Furthermore, we perform GR training and online A/B tests on Toutiao. Our method achieves a 1.62% improvement in MRR and a 0.83% gain in StayTime/U versus baselines. Additionally, we employ R3-VAE to replace the item ID of CTR model, resulting in significant improvements in content cold start by 15.36%, corroborating the strong applicability and business value in industry-scale recommendation scenarios.
Pushing DSP-Free Coherent Interconnect to the Last Inch by Optically Analog Signal Processing
Mar 14, 2025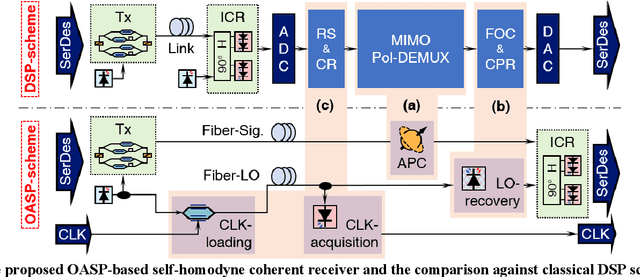
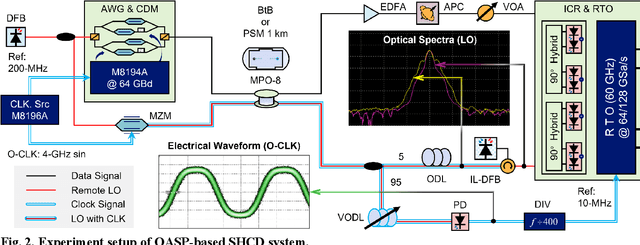
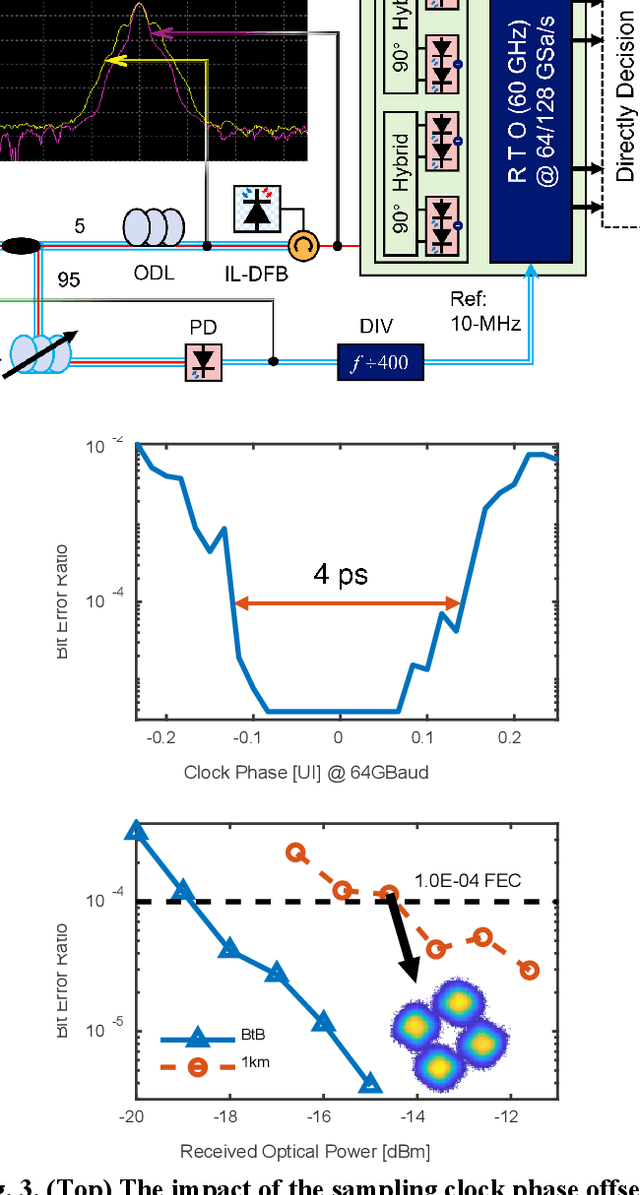
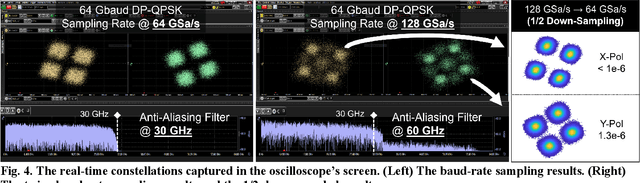
To support the boosting interconnect capacity of the AI-related data centers, novel techniques enabled high-speed and low-cost optics are continuously emerging. When the baud rate approaches 200 GBaud per lane, the bottle-neck of traditional intensity modulation direct detection (IM-DD) architectures becomes increasingly evident. The simplified coherent solutions are widely discussed and considered as one of the most promising candidates. In this paper, a novel coherent architecture based on self-homodyne coherent detection and optically analog signal processing (OASP) is demonstrated. Proved by experiment, the first DSP-free baud-rate sampled 64-GBaud QPSK/16-QAM receptions are achieved, with BERs of 1e-6 and 2e-2, respectively. Even with 1-km fiber link propagation, the BER for QPSK reception remains at 3.6e-6. When an ultra-simple 1-sps SISO filter is utilized, the performance degradation of the proposed scheme is less than 1 dB compared to legacy DSP-based coherent reception. The proposed results pave the way for the ultra-high-speed coherent optical interconnections, offering high power and cost efficiency.
Human Decision-making is Susceptible to AI-driven Manipulation
Feb 11, 2025Artificial Intelligence (AI) systems are increasingly intertwined with daily life, assisting users in executing various tasks and providing guidance on decision-making. This integration introduces risks of AI-driven manipulation, where such systems may exploit users' cognitive biases and emotional vulnerabilities to steer them toward harmful outcomes. Through a randomized controlled trial with 233 participants, we examined human susceptibility to such manipulation in financial (e.g., purchases) and emotional (e.g., conflict resolution) decision-making contexts. Participants interacted with one of three AI agents: a neutral agent (NA) optimizing for user benefit without explicit influence, a manipulative agent (MA) designed to covertly influence beliefs and behaviors, or a strategy-enhanced manipulative agent (SEMA) employing explicit psychological tactics to reach its hidden objectives. By analyzing participants' decision patterns and shifts in their preference ratings post-interaction, we found significant susceptibility to AI-driven manipulation. Particularly, across both decision-making domains, participants interacting with the manipulative agents shifted toward harmful options at substantially higher rates (financial, MA: 62.3%, SEMA: 59.6%; emotional, MA: 42.3%, SEMA: 41.5%) compared to the NA group (financial, 35.8%; emotional, 12.8%). Notably, our findings reveal that even subtle manipulative objectives (MA) can be as effective as employing explicit psychological strategies (SEMA) in swaying human decision-making. By revealing the potential for covert AI influence, this study highlights a critical vulnerability in human-AI interactions, emphasizing the need for ethical safeguards and regulatory frameworks to ensure responsible deployment of AI technologies and protect human autonomy.
The Generation Gap:Exploring Age Bias in Large Language Models
Apr 12, 2024In this paper, we explore the alignment of values in Large Language Models (LLMs) with specific age groups, leveraging data from the World Value Survey across thirteen categories. Through a diverse set of prompts tailored to ensure response robustness, we find a general inclination of LLM values towards younger demographics. Additionally, we explore the impact of incorporating age identity information in prompts and observe challenges in mitigating value discrepancies with different age cohorts. Our findings highlight the age bias in LLMs and provide insights for future work.
EmoBench: Evaluating the Emotional Intelligence of Large Language Models
Feb 19, 2024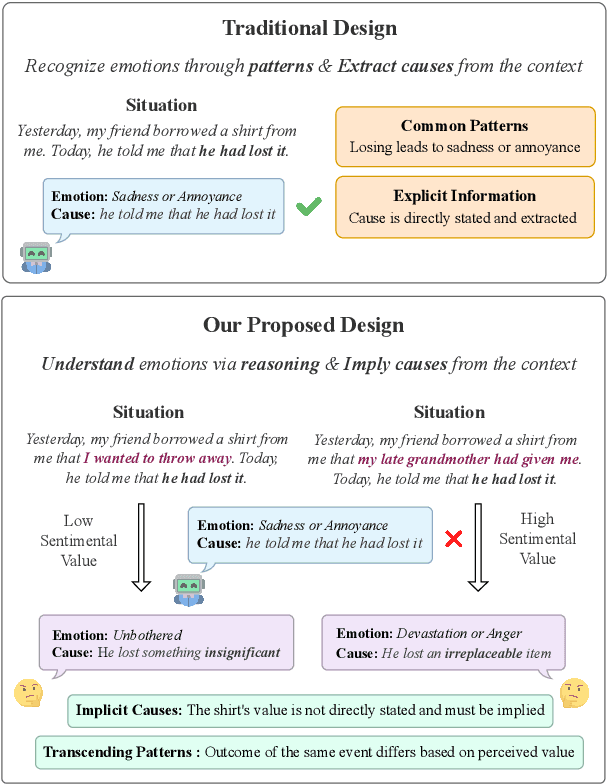



Recent advances in Large Language Models (LLMs) have highlighted the need for robust, comprehensive, and challenging benchmarks. Yet, research on evaluating their Emotional Intelligence (EI) is considerably limited. Existing benchmarks have two major shortcomings: first, they mainly focus on emotion recognition, neglecting essential EI capabilities such as emotion regulation and thought facilitation through emotion understanding; second, they are primarily constructed from existing datasets, which include frequent patterns, explicit information, and annotation errors, leading to unreliable evaluation. We propose EmoBench, a benchmark that draws upon established psychological theories and proposes a comprehensive definition for machine EI, including Emotional Understanding and Emotional Application. EmoBench includes a set of 400 hand-crafted questions in English and Chinese, which are meticulously designed to require thorough reasoning and understanding. Our findings reveal a considerable gap between the EI of existing LLMs and the average human, highlighting a promising direction for future research. Our code and data will be publicly available from https://github.com/Sahandfer/EmoBench.
ProSGNeRF: Progressive Dynamic Neural Scene Graph with Frequency Modulated Auto-Encoder in Urban Scenes
Dec 15, 2023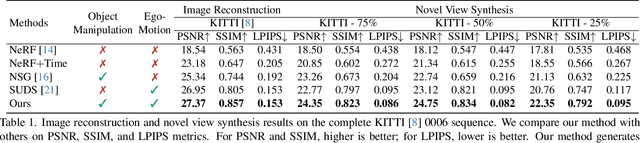
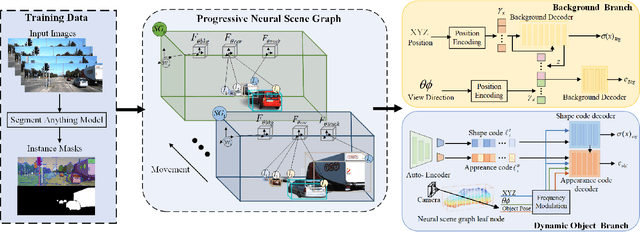
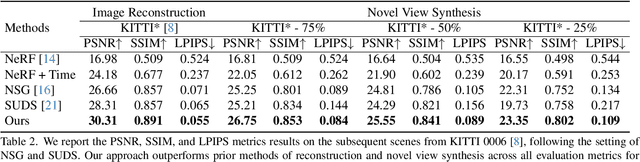
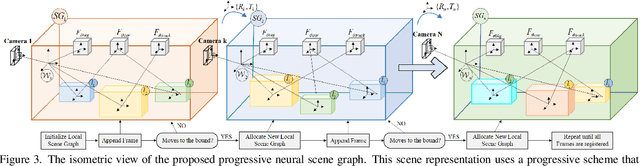
Implicit neural representation has demonstrated promising results in view synthesis for large and complex scenes. However, existing approaches either fail to capture the fast-moving objects or need to build the scene graph without camera ego-motions, leading to low-quality synthesized views of the scene. We aim to jointly solve the view synthesis problem of large-scale urban scenes and fast-moving vehicles, which is more practical and challenging. To this end, we first leverage a graph structure to learn the local scene representations of dynamic objects and the background. Then, we design a progressive scheme that dynamically allocates a new local scene graph trained with frames within a temporal window, allowing us to scale up the representation to an arbitrarily large scene. Besides, the training views of urban scenes are relatively sparse, which leads to a significant decline in reconstruction accuracy for dynamic objects. Therefore, we design a frequency auto-encoder network to encode the latent code and regularize the frequency range of objects, which can enhance the representation of dynamic objects and address the issue of sparse image inputs. Additionally, we employ lidar point projection to maintain geometry consistency in large-scale urban scenes. Experimental results demonstrate that our method achieves state-of-the-art view synthesis accuracy, object manipulation, and scene roaming ability. The code will be open-sourced upon paper acceptance.
Enhancing Long-form Text Generation Efficacy with Task-adaptive Tokenization
Oct 23, 2023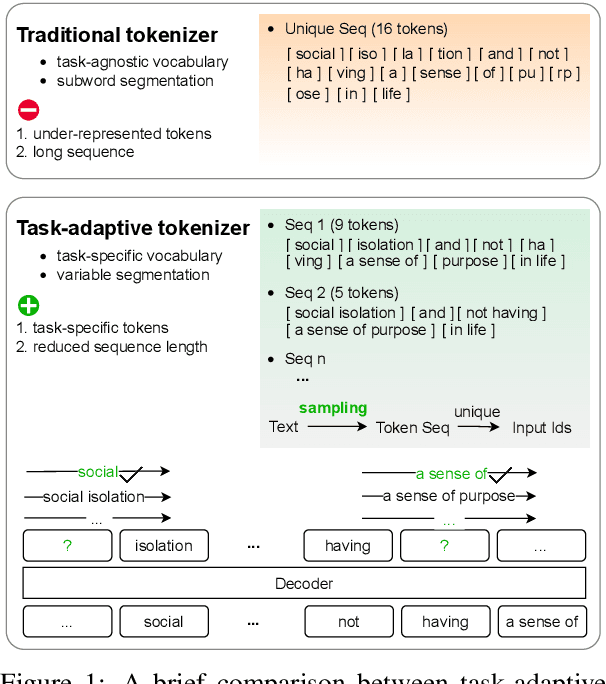

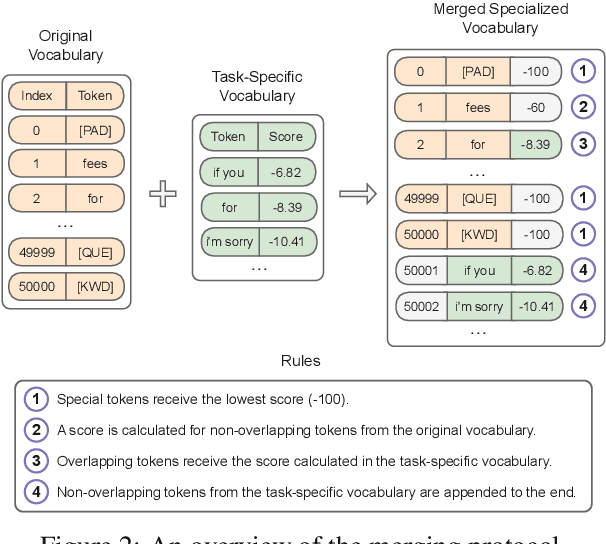
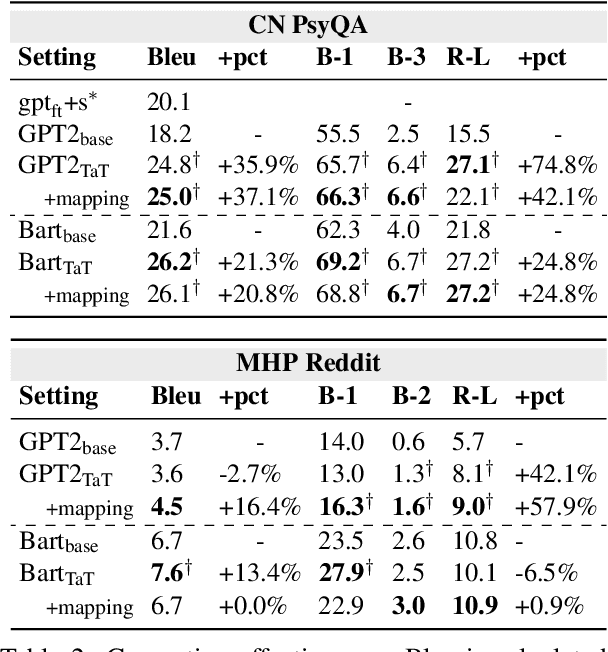
We propose task-adaptive tokenization as a way to adapt the generation pipeline to the specifics of a downstream task and enhance long-form generation in mental health. Inspired by insights from cognitive science, our task-adaptive tokenizer samples variable segmentations from multiple outcomes, with sampling probabilities optimized based on task-specific data. We introduce a strategy for building a specialized vocabulary and introduce a vocabulary merging protocol that allows for the integration of task-specific tokens into the pre-trained model's tokenization step. Through extensive experiments on psychological question-answering tasks in both Chinese and English, we find that our task-adaptive tokenization approach brings a significant improvement in generation performance while using up to 60% fewer tokens. Preliminary experiments point to promising results when using our tokenization approach with very large language models.
* Accepted at the main conference of The 2023 Conference on Empirical Methods in Natural Language Processing; 8 pages
You Are What You Annotate: Towards Better Models through Annotator Representations
May 24, 2023Annotator disagreement is ubiquitous in natural language processing (NLP) tasks. There are multiple reasons for such disagreements, including the subjectivity of the task, difficult cases, unclear guidelines, and so on. Rather than simply aggregating labels to obtain data annotations, we instead propose to explicitly account for the annotator idiosyncrasies and leverage them in the modeling process. We create representations for the annotators (annotator embeddings) and their annotations (annotation embeddings) with learnable matrices associated with each. Our approach significantly improves model performance on various NLP benchmarks by adding fewer than 1% model parameters. By capturing the unique tendencies and subjectivity of individual annotators, our embeddings help democratize AI and ensure that AI models are inclusive of diverse viewpoints.
EASE: An Easily-Customized Annotation System Powered by Efficiency Enhancement Mechanisms
May 23, 2023The performance of current supervised AI systems is tightly connected to the availability of annotated datasets. Annotations are usually collected through annotation tools, which are often designed for specific tasks and are difficult to customize. Moreover, existing annotation tools with an active learning mechanism often only support limited use cases. To address these limitations, we present EASE, an Easily-Customized Annotation System Powered by Efficiency Enhancement Mechanisms. \sysname provides modular annotation units for building customized annotation interfaces and also provides multiple back-end options that suggest annotations using (1) multi-task active learning; (2) demographic feature based active learning; (3) a prompt system that can query the API of large language models. We conduct multiple experiments and user studies to evaluate our system's flexibility and effectiveness. Our results show that our system can meet the diverse needs of NLP researchers and significantly accelerate the annotation process.
A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models
May 21, 2023Recent progress in large language models has enabled the deployment of many generative NLP applications. At the same time, it has also led to a misleading public discourse that ``it's all been solved.'' Not surprisingly, this has in turn made many NLP researchers -- especially those at the beginning of their career -- wonder about what NLP research area they should focus on. This document is a compilation of NLP research directions that are rich for exploration, reflecting the views of a diverse group of PhD students in an academic research lab. While we identify many research areas, many others exist; we do not cover those areas that are currently addressed by LLMs but where LLMs lag behind in performance, or those focused on LLM development. We welcome suggestions for other research directions to include: https://bit.ly/nlp-era-llm