 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOKA: Moral Knowledge Augmentation for Moral Event Extraction
Nov 16, 2023



News media employ moral language to create memorable stories, and readers often engage with the content that align with their values. Moral theories have been applied to news analysis studying moral values in isolation, while the intricate dynamics among participating entities in shaping moral events have been overlooked. This is mainly due to the use of obscure language to conceal evident ideology and values, coupled with the insufficient moral reasoning capability in most existing NLP systems, where LLMs are no exception. To study this phenomenon, we first annotate a new dataset, MORAL EVENTS, consisting of 5,494 structured annotations on 474 news articles by diverse US media across the political spectrum. We further propose MOKA, a moral event extraction framework with MOral Knowledge Augmentation, that leverages knowledge derived from moral words and moral scenarios. Experimental results show that MOKA outperforms competitive baselines across three moral event understanding tasks. Further analyses illuminate the selective reporting of moral events by media outlets of different ideological leanings, suggesting the significance of event-level morality analysis in news. Our datasets and codebase are available at https://github.com/launchnlp/MOKA.
Crossing the Aisle: Unveiling Partisan and Counter-Partisan Events in News Reporting
Oct 28, 2023



News media is expected to uphold unbiased reporting. Yet they may still affect public opinion by selectively including or omitting events that support or contradict their ideological positions. Prior work in NLP has only studied media bias via linguistic style and word usage. In this paper, we study to which degree media balances news reporting and affects consumers through event inclusion or omission. We first introduce the task of detecting both partisan and counter-partisan events: events that support or oppose the author's political ideology. To conduct our study, we annotate a high-quality dataset, PAC, containing 8,511 (counter-)partisan event annotations in 304 news articles from ideologically diverse media outlets. We benchmark PAC to highlight the challenges of this task. Our findings highlight both the ways in which the news subtly shapes opinion and the need for large language models that better understand events within a broader context. Our dataset can be found at https://github.com/launchnlp/Partisan-Event-Dataset.
You Are What You Annotate: Towards Better Models through Annotator Representations
May 24, 2023Annotator disagreement is ubiquitous in natural language processing (NLP) tasks. There are multiple reasons for such disagreements, including the subjectivity of the task, difficult cases, unclear guidelines, and so on. Rather than simply aggregating labels to obtain data annotations, we instead propose to explicitly account for the annotator idiosyncrasies and leverage them in the modeling process. We create representations for the annotators (annotator embeddings) and their annotations (annotation embeddings) with learnable matrices associated with each. Our approach significantly improves model performance on various NLP benchmarks by adding fewer than 1% model parameters. By capturing the unique tendencies and subjectivity of individual annotators, our embeddings help democratize AI and ensure that AI models are inclusive of diverse viewpoints.
EASE: An Easily-Customized Annotation System Powered by Efficiency Enhancement Mechanisms
May 23, 2023The performance of current supervised AI systems is tightly connected to the availability of annotated datasets. Annotations are usually collected through annotation tools, which are often designed for specific tasks and are difficult to customize. Moreover, existing annotation tools with an active learning mechanism often only support limited use cases. To address these limitations, we present EASE, an Easily-Customized Annotation System Powered by Efficiency Enhancement Mechanisms. \sysname provides modular annotation units for building customized annotation interfaces and also provides multiple back-end options that suggest annotations using (1) multi-task active learning; (2) demographic feature based active learning; (3) a prompt system that can query the API of large language models. We conduct multiple experiments and user studies to evaluate our system's flexibility and effectiveness. Our results show that our system can meet the diverse needs of NLP researchers and significantly accelerate the annotation process.
A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models
May 21, 2023Recent progress in large language models has enabled the deployment of many generative NLP applications. At the same time, it has also led to a misleading public discourse that ``it's all been solved.'' Not surprisingly, this has in turn made many NLP researchers -- especially those at the beginning of their career -- wonder about what NLP research area they should focus on. This document is a compilation of NLP research directions that are rich for exploration, reflecting the views of a diverse group of PhD students in an academic research lab. While we identify many research areas, many others exist; we do not cover those areas that are currently addressed by LLMs but where LLMs lag behind in performance, or those focused on LLM development. We welcome suggestions for other research directions to include: https://bit.ly/nlp-era-llm
Late Fusion with Triplet Margin Objective for Multimodal Ideology Prediction and Analysis
Nov 04, 2022Prior work on ideology prediction has largely focused on single modalities, i.e., text or images. In this work, we introduce the task of multimodal ideology prediction, where a model predicts binary or five-point scale ideological leanings, given a text-image pair with political content. We first collect five new large-scale datasets with English documents and images along with their ideological leanings, covering news articles from a wide range of US mainstream media and social media posts from Reddit and Twitter. We conduct in-depth analyses of news articles and reveal differences in image content and usage across the political spectrum. Furthermore, we perform extensive experiments and ablation studies, demonstrating the effectiveness of targeted pretraining objectives on different model components. Our best-performing model, a late-fusion architecture pretrained with a triplet objective over multimodal content, outperforms the state-of-the-art text-only model by almost 4% and a strong multimodal baseline with no pretraining by over 3%.
Evaluating Neural Machine Comprehension Model Robustness to Noisy Inputs and Adversarial Attacks
May 01, 2020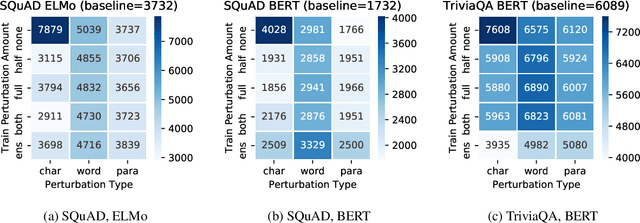

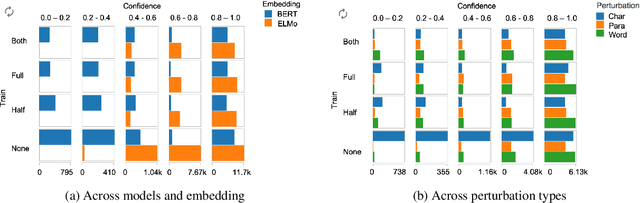
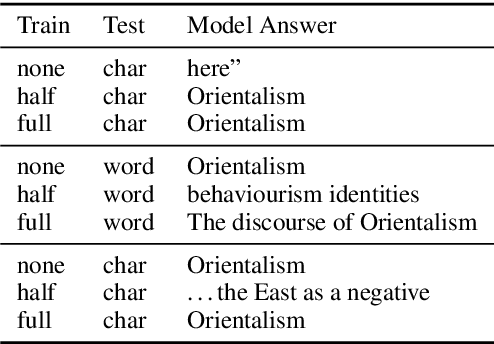
We evaluate machine comprehension models' robustness to noise and adversarial attacks by performing novel perturbations at the character, word, and sentence level. We experiment with different amounts of perturbations to examine model confidence and misclassification rate, and contrast model performance in adversarial training with different embedding types on two benchmark datasets. We demonstrate improving model performance with ensembling. Finally, we analyze factors that effect model behavior under adversarial training and develop a model to predict model errors during adversarial attacks.
Modeling Color Terminology Across Thousands of Languages
Oct 03, 2019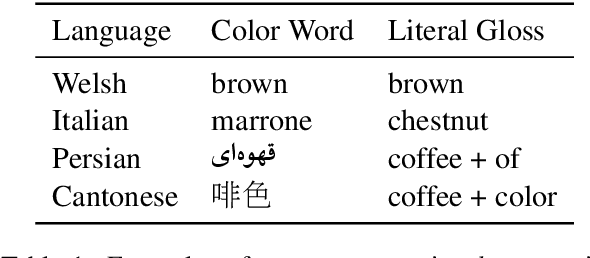
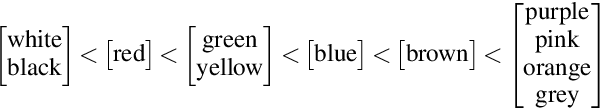

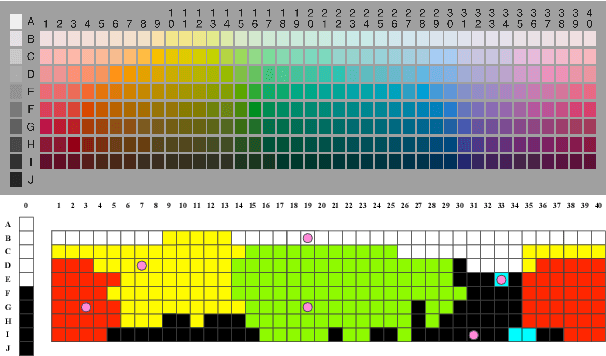
There is an extensive history of scholarship into what constitutes a "basic" color term, as well as a broadly attested acquisition sequence of basic color terms across many languages, as articulated in the seminal work of Berlin and Kay (1969). This paper employs a set of diverse measures on massively cross-linguistic data to operationalize and critique the Berlin and Kay color term hypotheses. Collectively, the 14 empirically-grounded computational linguistic metrics we design---as well as their aggregation---correlate strongly with both the Berlin and Kay basic/secondary color term partition (gamma=0.96) and their hypothesized universal acquisition sequence. The measures and result provide further empirical evidence from computational linguistics in support of their claims, as well as additional nuance: they suggest treating the partition as a spectrum instead of a dichotomy.