 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative-of-Thought: Improving Temporal Reasoning of Large Language Models via Recounted Narratives
Oct 07, 2024



Reasoning about time and temporal relations is an integral aspect of human cognition, essential for perceiving the world and navigating our experiences. Though large language models (LLMs) have demonstrated impressive performance in many reasoning tasks, temporal reasoning remains challenging due to its intrinsic complexity. In this work, we first study an essential task of temporal reasoning -- temporal graph generation, to unveil LLMs' inherent, global reasoning capabilities. We show that this task presents great challenges even for the most powerful LLMs, such as GPT-3.5/4. We also notice a significant performance gap by small models (<10B) that lag behind LLMs by 50%. Next, we study how to close this gap with a budget constraint, e.g., not using model finetuning. We propose a new prompting technique tailored for temporal reasoning, Narrative-of-Thought (NoT), that first converts the events set to a Python class, then prompts a small model to generate a temporally grounded narrative, guiding the final generation of a temporal graph. Extensive experiments showcase the efficacy of NoT in improving various metrics. Notably, NoT attains the highest F1 on the Schema-11 evaluation set, while securing an overall F1 on par with GPT-3.5. NoT also achieves the best structural similarity across the board, even compared with GPT-3.5/4. Our code is available at https://github.com/launchnlp/NoT.
MOKA: Moral Knowledge Augmentation for Moral Event Extraction
Nov 16, 2023



News media employ moral language to create memorable stories, and readers often engage with the content that align with their values. Moral theories have been applied to news analysis studying moral values in isolation, while the intricate dynamics among participating entities in shaping moral events have been overlooked. This is mainly due to the use of obscure language to conceal evident ideology and values, coupled with the insufficient moral reasoning capability in most existing NLP systems, where LLMs are no exception. To study this phenomenon, we first annotate a new dataset, MORAL EVENTS, consisting of 5,494 structured annotations on 474 news articles by diverse US media across the political spectrum. We further propose MOKA, a moral event extraction framework with MOral Knowledge Augmentation, that leverages knowledge derived from moral words and moral scenarios. Experimental results show that MOKA outperforms competitive baselines across three moral event understanding tasks. Further analyses illuminate the selective reporting of moral events by media outlets of different ideological leanings, suggesting the significance of event-level morality analysis in news. Our datasets and codebase are available at https://github.com/launchnlp/MOKA.
All Things Considered: Detecting Partisan Events from News Media with Cross-Article Comparison
Oct 28, 2023



Public opinion is shaped by the information news media provide, and that information in turn may be shaped by the ideological preferences of media outlets. But while much attention has been devoted to media bias via overt ideological language or topic selection, a more unobtrusive way in which the media shape opinion is via the strategic inclusion or omission of partisan events that may support one side or the other. We develop a latent variable-based framework to predict the ideology of news articles by comparing multiple articles on the same story and identifying partisan events whose inclusion or omission reveals ideology. Our experiments first validate the existence of partisan event selection, and then show that article alignment and cross-document comparison detect partisan events and article ideology better than competitive baselines. Our results reveal the high-level form of media bias, which is present even among mainstream media with strong norms of objectivity and nonpartisanship. Our codebase and dataset are available at https://github.com/launchnlp/ATC.
Crossing the Aisle: Unveiling Partisan and Counter-Partisan Events in News Reporting
Oct 28, 2023



News media is expected to uphold unbiased reporting. Yet they may still affect public opinion by selectively including or omitting events that support or contradict their ideological positions. Prior work in NLP has only studied media bias via linguistic style and word usage. In this paper, we study to which degree media balances news reporting and affects consumers through event inclusion or omission. We first introduce the task of detecting both partisan and counter-partisan events: events that support or oppose the author's political ideology. To conduct our study, we annotate a high-quality dataset, PAC, containing 8,511 (counter-)partisan event annotations in 304 news articles from ideologically diverse media outlets. We benchmark PAC to highlight the challenges of this task. Our findings highlight both the ways in which the news subtly shapes opinion and the need for large language models that better understand events within a broader context. Our dataset can be found at https://github.com/launchnlp/Partisan-Event-Dataset.
Generative Entity-to-Entity Stance Detection with Knowledge Graph Augmentation
Nov 02, 2022



Stance detection is typically framed as predicting the sentiment in a given text towards a target entity. However, this setup overlooks the importance of the source entity, i.e., who is expressing the opinion. In this paper, we emphasize the need for studying interactions among entities when inferring stances. We first introduce a new task, entity-to-entity (E2E) stance detection, which primes models to identify entities in their canonical names and discern stances jointly. To support this study, we curate a new dataset with 10,619 annotations labeled at the sentence-level from news articles of different ideological leanings. We present a novel generative framework to allow the generation of canonical names for entities as well as stances among them. We further enhance the model with a graph encoder to summarize entity activities and external knowledge surrounding the entities. Experiments show that our model outperforms strong comparisons by large margins. Further analyses demonstrate the usefulness of E2E stance detection for understanding media quotation and stance landscape, as well as inferring entity ideology.
POLITICS: Pretraining with Same-story Article Comparison for Ideology Prediction and Stance Detection
May 02, 2022

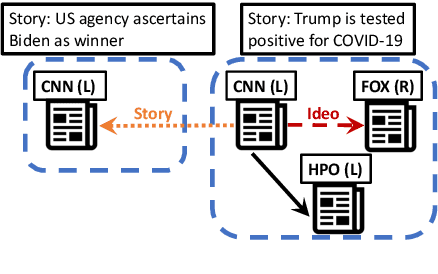
Ideology is at the core of political science research. Yet, there still does not exist general-purpose tools to characterize and predict ideology across different genres of text. To this end, we study Pretrained Language Models using novel ideology-driven pretraining objectives that rely on the comparison of articles on the same story written by media of different ideologies. We further collect a large-scale dataset, consisting of more than 3.6M political news articles, for pretraining. Our model POLITICS outperforms strong baselines and the previous state-of-the-art models on ideology prediction and stance detection tasks. Further analyses show that POLITICS is especially good at understanding long or formally written texts, and is also robust in few-shot learning scenarios.
Winning on the Merits: The Joint Effects of Content and Style on Debate Outcomes
May 15, 2017Debate and deliberation play essential roles in politics and government, but most models presume that debates are won mainly via superior style or agenda control. Ideally, however, debates would be won on the merits, as a function of which side has the stronger arguments. We propose a predictive model of debate that estimates the effects of linguistic features and the latent persuasive strengths of different topics, as well as the interactions between the two. Using a dataset of 118 Oxford-style debates, our model's combination of content (as latent topics) and style (as linguistic features) allows us to predict audience-adjudicated winners with 74% accuracy, significantly outperforming linguistic features alone (66%). Our model finds that winning sides employ stronger arguments, and allows us to identify the linguistic features associated with strong or weak arguments.