 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Claims Evolve: Evaluating and Enhancing the Robustness of Embedding Models Against Misinformation Edits
Mar 05, 2025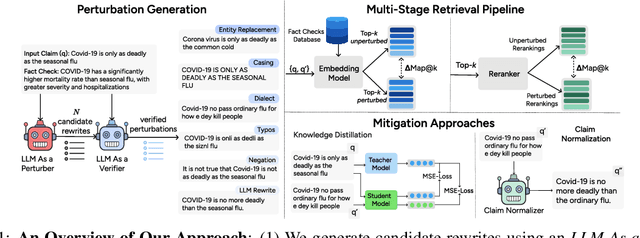
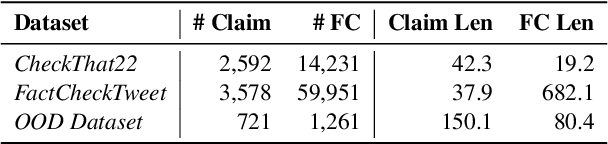
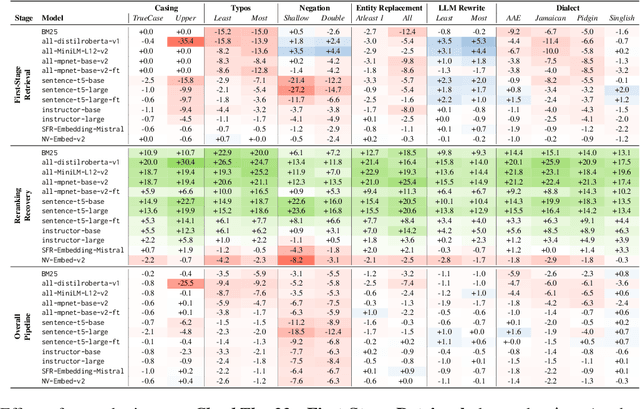
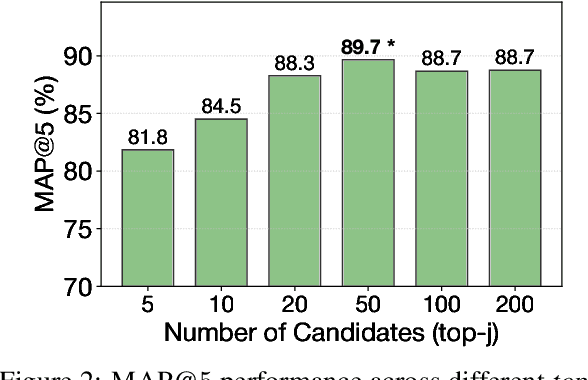
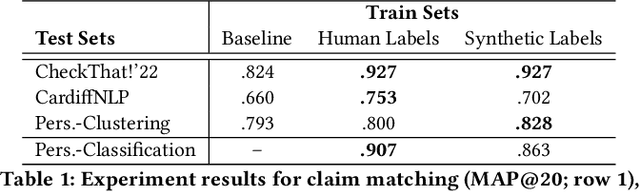
Online misinformation remains a critical challenge, and fact-checkers increasingly rely on embedding-based methods to retrieve relevant fact-checks. Yet, when debunked claims reappear in edited forms, the performance of these methods is unclear. In this work, we introduce a taxonomy of six common real-world misinformation edits and propose a perturbation framework that generates valid, natural claim variations. Our multi-stage retrieval evaluation reveals that standard embedding models struggle with user-introduced edits, while LLM-distilled embeddings offer improved robustness at a higher computational cost. Although a strong reranker helps mitigate some issues, it cannot fully compensate for first-stage retrieval gaps. Addressing these retrieval gaps, our train- and inference-time mitigation approaches enhance in-domain robustness by up to 17 percentage points and boost out-of-domain generalization by 10 percentage points over baseline models. Overall, our findings provide practical improvements to claim-matching systems, enabling more reliable fact-checking of evolving misinformation.
SynDy: Synthetic Dynamic Dataset Generation Framework for Misinformation Tasks
May 17, 2024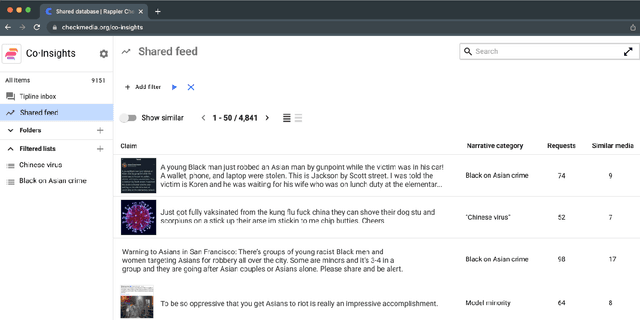
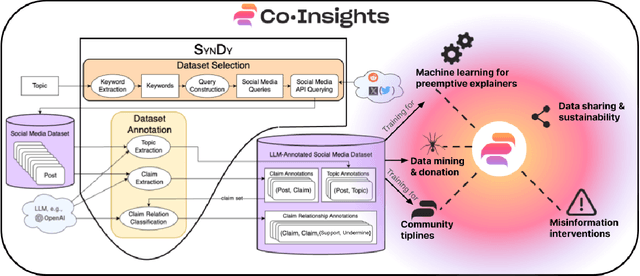
Diaspora communities are disproportionately impacted by off-the-radar misinformation and often neglected by mainstream fact-checking efforts, creating a critical need to scale-up efforts of nascent fact-checking initiatives. In this paper we present SynDy, a framework for Synthetic Dynamic Dataset Generation to leverage the capabilities of the largest frontier Large Language Models (LLMs) to train local, specialized language models. To the best of our knowledge, SynDy is the first paper utilizing LLMs to create fine-grained synthetic labels for tasks of direct relevance to misinformation mitigation, namely Claim Matching, Topical Clustering, and Claim Relationship Classification. SynDy utilizes LLMs and social media queries to automatically generate distantly-supervised, topically-focused datasets with synthetic labels on these three tasks, providing essential tools to scale up human-led fact-checking at a fraction of the cost of human-annotated data. Training on SynDy's generated labels shows improvement over a standard baseline and is not significantly worse compared to training on human labels (which may be infeasible to acquire). SynDy is being integrated into Meedan's chatbot tiplines that are used by over 50 organizations, serve over 230K users annually, and automatically distribute human-written fact-checks via messaging apps such as WhatsApp. SynDy will also be integrated into our deployed Co-Insights toolkit, enabling low-resource organizations to launch tiplines for their communities. Finally, we envision SynDy enabling additional fact-checking tools such as matching new misinformation claims to high-quality explainers on common misinformation topics.
Misinformation as Information Pollution
Jun 21, 2023Social media feed algorithms are designed to optimize online social engagements for the purpose of maximizing advertising profits, and therefore have an incentive to promote controversial posts including misinformation. By thinking about misinformation as information pollution, we can draw parallels with environmental policy for countering pollution such as carbon taxes. Similar to pollution, a Pigouvian tax on misinformation provides economic incentives for social media companies to control the spread of misinformation more effectively to avoid or reduce their misinformation tax, while preserving some degree of freedom in platforms' response. In this paper, we highlight a bird's eye view of a Pigouvian misinformation tax and discuss the key questions and next steps for implementing such a taxing scheme.
A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models
May 21, 2023Recent progress in large language models has enabled the deployment of many generative NLP applications. At the same time, it has also led to a misleading public discourse that ``it's all been solved.'' Not surprisingly, this has in turn made many NLP researchers -- especially those at the beginning of their career -- wonder about what NLP research area they should focus on. This document is a compilation of NLP research directions that are rich for exploration, reflecting the views of a diverse group of PhD students in an academic research lab. While we identify many research areas, many others exist; we do not cover those areas that are currently addressed by LLMs but where LLMs lag behind in performance, or those focused on LLM development. We welcome suggestions for other research directions to include: https://bit.ly/nlp-era-llm
Adaptable Claim Rewriting with Offline Reinforcement Learning for Effective Misinformation Discovery
Oct 14, 2022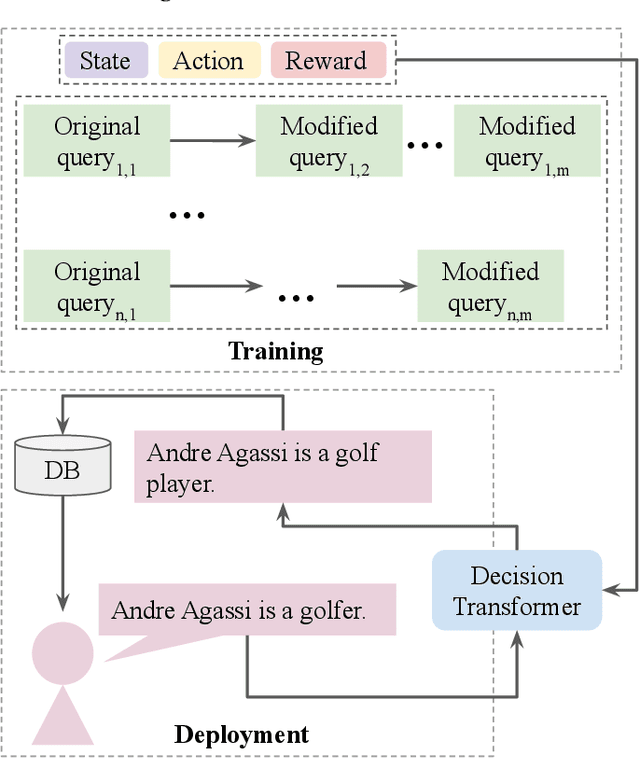
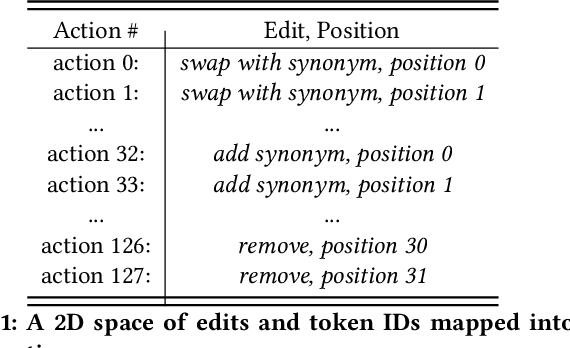
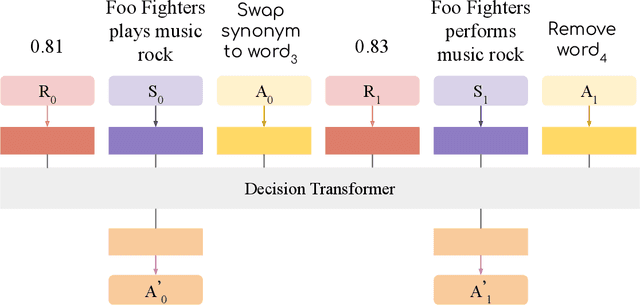

We propose a novel system to help fact-checkers formulate search queries for known misinformation claims and effectively search across multiple social media platforms. We introduce an adaptable rewriting strategy, where editing actions (e.g., swap a word with its synonym; change verb tense into present simple) for queries containing claims are automatically learned through offline reinforcement learning. Specifically, we use a decision transformer to learn a sequence of editing actions that maximize query retrieval metrics such as mean average precision. Through several experiments, we show that our approach can increase the effectiveness of the queries by up to 42\% relatively, while producing editing action sequences that are human readable, thus making the system easy to use and explain.
Matching Tweets With Applicable Fact-Checks Across Languages
Feb 14, 2022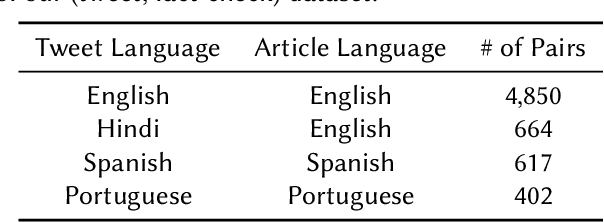
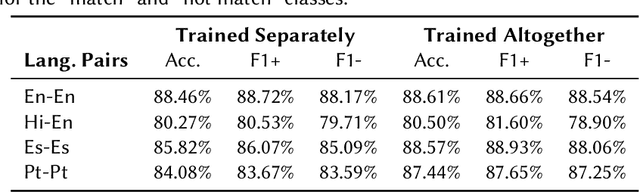
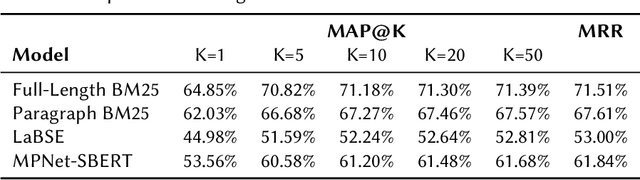
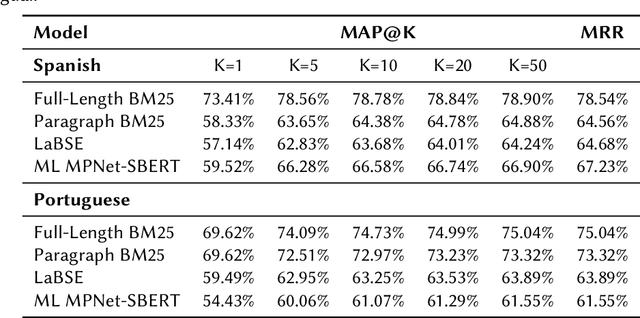
An important challenge for news fact-checking is the effective dissemination of existing fact-checks. This in turn brings the need for reliable methods to detect previously fact-checked claims. In this paper, we focus on automatically finding existing fact-checks for claims made in social media posts (tweets). We conduct both classification and retrieval experiments, in monolingual (English only), multilingual (Spanish, Portuguese), and cross-lingual (Hindi-English) settings using multilingual transformer models such as XLM-RoBERTa and multilingual embeddings such as LaBSE and SBERT. We present promising results for "match" classification (93% average accuracy) in four language pairs. We also find that a BM25 baseline outperforms state-of-the-art multilingual embedding models for the retrieval task during our monolingual experiments. We highlight and discuss NLP challenges while addressing this problem in different languages, and we introduce a novel curated dataset of fact-checks and corresponding tweets for future research.
Tiplines to Combat Misinformation on Encrypted Platforms: A Case Study of the 2019 Indian Election on WhatsApp
Jun 08, 2021


WhatsApp is a popular chat application used by over 2 billion users worldwide. However, due to end-to-end encryption, there is currently no easy way to fact-check content on WhatsApp at scale. In this paper, we analyze the usefulness of a crowd-sourced system on WhatsApp through which users can submit "tips" containing messages they want fact-checked. We compare the tips sent to a WhatsApp tipline run during the 2019 Indian national elections with the messages circulating in large, public groups on WhatsApp and other social media platforms during the same period. We find that tiplines are a very useful lens into WhatsApp conversations: a significant fraction of messages and images sent to the tipline match with the content being shared on public WhatsApp groups and other social media. Our analysis also shows that tiplines cover the most popular content well, and a majority of such content is often shared to the tipline before appearing in large, public WhatsApp groups. Overall, the analysis suggests tiplines can be an effective source for discovering content to fact-check.
Claim Matching Beyond English to Scale Global Fact-Checking
Jun 01, 2021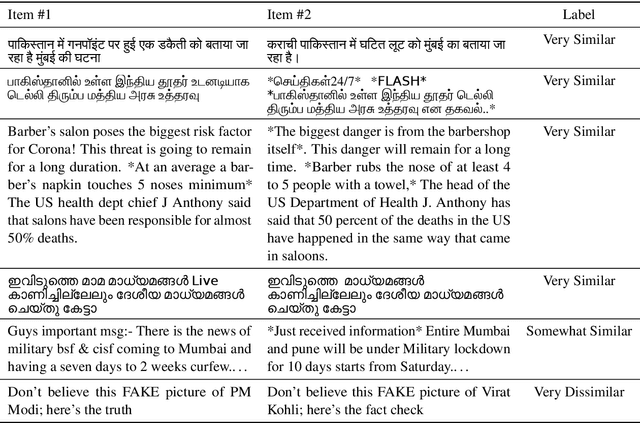
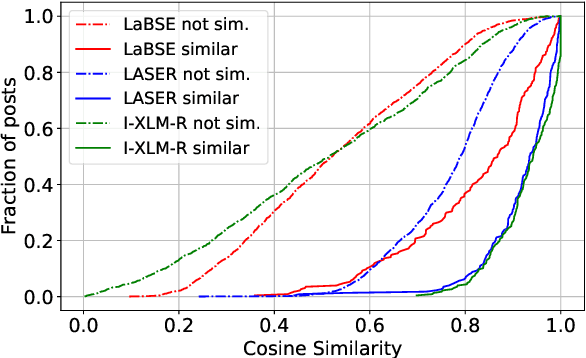
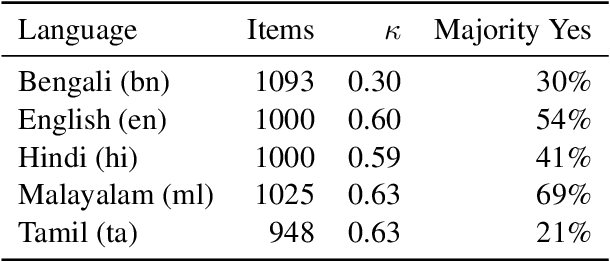
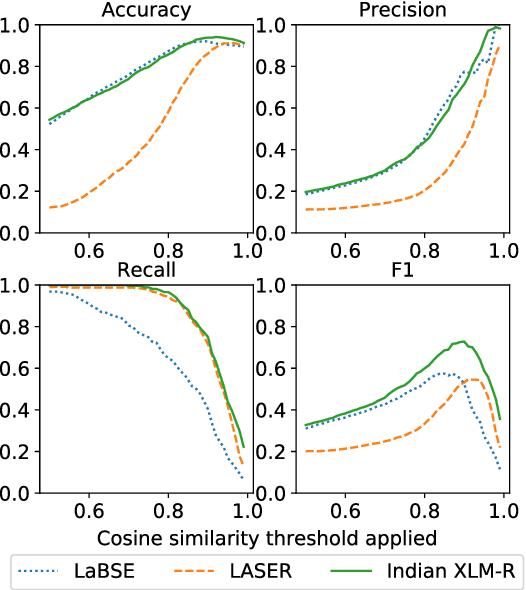
Manual fact-checking does not scale well to serve the needs of the internet. This issue is further compounded in non-English contexts. In this paper, we discuss claim matching as a possible solution to scale fact-checking. We define claim matching as the task of identifying pairs of textual messages containing claims that can be served with one fact-check. We construct a novel dataset of WhatsApp tipline and public group messages alongside fact-checked claims that are first annotated for containing "claim-like statements" and then matched with potentially similar items and annotated for claim matching. Our dataset contains content in high-resource (English, Hindi) and lower-resource (Bengali, Malayalam, Tamil) languages. We train our own embedding model using knowledge distillation and a high-quality "teacher" model in order to address the imbalance in embedding quality between the low- and high-resource languages in our dataset. We provide evaluations on the performance of our solution and compare with baselines and existing state-of-the-art multilingual embedding models, namely LASER and LaBSE. We demonstrate that our performance exceeds LASER and LaBSE in all settings. We release our annotated datasets, codebooks, and trained embedding model to allow for further research.
Extractive and Abstractive Explanations for Fact-Checking and Evaluation of News
Apr 27, 2021
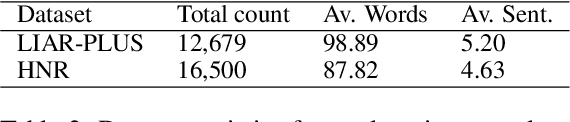


In this paper, we explore the construction of natural language explanations for news claims, with the goal of assisting fact-checking and news evaluation applications. We experiment with two methods: (1) an extractive method based on Biased TextRank -- a resource-effective unsupervised graph-based algorithm for content extraction; and (2) an abstractive method based on the GPT-2 language model. We perform comparative evaluations on two misinformation datasets in the political and health news domains, and find that the extractive method shows the most promise.
Biased TextRank: Unsupervised Graph-Based Content Extraction
Nov 02, 2020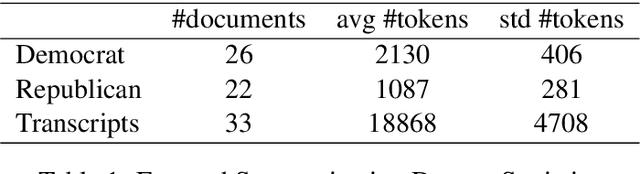
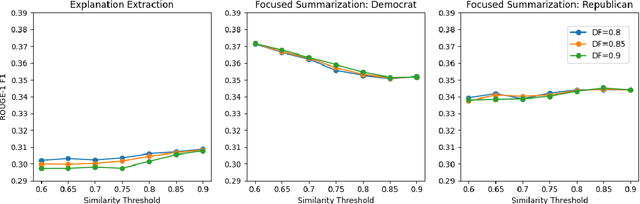
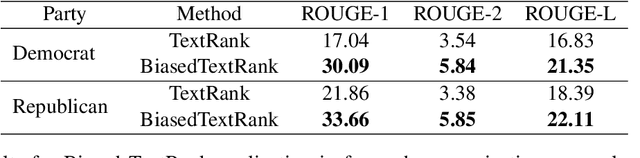

We introduce Biased TextRank, a graph-based content extraction method inspired by the popular TextRank algorithm that ranks text spans according to their importance for language processing tasks and according to their relevance to an input "focus." Biased TextRank enables focused content extraction for text by modifying the random restarts in the execution of TextRank. The random restart probabilities are assigned based on the relevance of the graph nodes to the focus of the task. We present two applications of Biased TextRank: focused summarization and explanation extraction, and show that our algorithm leads to improved performance on two different datasets by significant ROUGE-N score margins. Much like its predecessor, Biased TextRank is unsupervised, easy to implement and orders of magnitude faster and lighter than current state-of-the-art Natural Language Processing methods for similar tasks.