 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Powered Detection of Inappropriate Language in Medical School Curricula
Aug 27, 2025The use of inappropriate language -- such as outdated, exclusionary, or non-patient-centered terms -- medical instructional materials can significantly influence clinical training, patient interactions, and health outcomes. Despite their reputability, many materials developed over past decades contain examples now considered inappropriate by current medical standards. Given the volume of curricular content, manually identifying instances of inappropriate use of language (IUL) and its subcategories for systematic review is prohibitively costly and impractical. To address this challenge, we conduct a first-in-class evaluation of small language models (SLMs) fine-tuned on labeled data and pre-trained LLMs with in-context learning on a dataset containing approximately 500 documents and over 12,000 pages. For SLMs, we consider: (1) a general IUL classifier, (2) subcategory-specific binary classifiers, (3) a multilabel classifier, and (4) a two-stage hierarchical pipeline for general IUL detection followed by multilabel classification. For LLMs, we consider variations of prompts that include subcategory definitions and/or shots. We found that both LLama-3 8B and 70B, even with carefully curated shots, are largely outperformed by SLMs. While the multilabel classifier performs best on annotated data, supplementing training with unflagged excerpts as negative examples boosts the specific classifiers' AUC by up to 25%, making them most effective models for mitigating harmful language in medical curricula.
A Scaling Law for Token Efficiency in LLM Fine-Tuning Under Fixed Compute Budgets
May 09, 2025



We introduce a scaling law for fine-tuning large language models (LLMs) under fixed compute budgets that explicitly accounts for data composition. Conventional approaches measure training data solely by total tokens, yet the number of examples and their average token length -- what we term \emph{dataset volume} -- play a decisive role in model performance. Our formulation is tuned following established procedures. Experiments on the BRICC dataset \cite{salavati2024reducing} and subsets of the MMLU dataset \cite{hendrycks2021measuringmassivemultitasklanguage}, evaluated under multiple subsampling strategies, reveal that data composition significantly affects token efficiency. These results motivate refined scaling laws for practical LLM fine-tuning in resource-constrained settings.
Towards Fairer Health Recommendations: finding informative unbiased samples via Word Sense Disambiguation
Sep 11, 2024
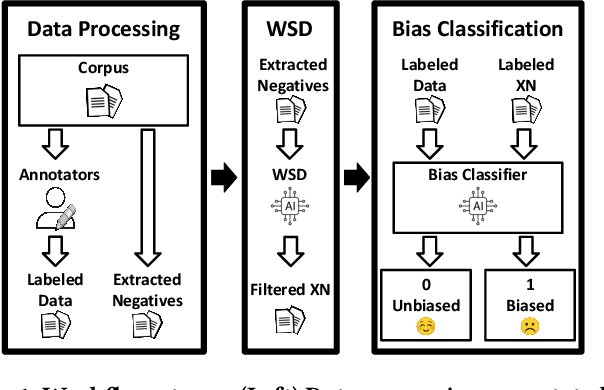

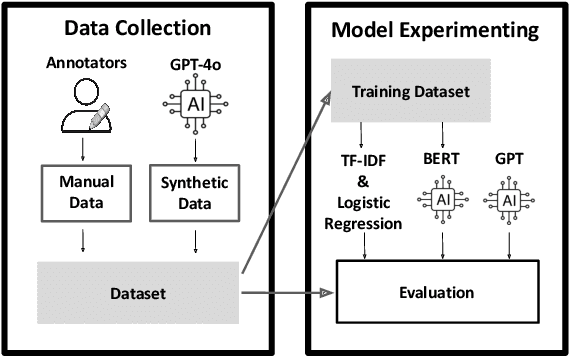
There have been growing concerns around high-stake applications that rely on models trained with biased data, which consequently produce biased predictions, often harming the most vulnerable. In particular, biased medical data could cause health-related applications and recommender systems to create outputs that jeopardize patient care and widen disparities in health outcomes. A recent framework titled Fairness via AI posits that, instead of attempting to correct model biases, researchers must focus on their root causes by using AI to debias data. Inspired by this framework, we tackle bias detection in medical curricula using NLP models, including LLMs, and evaluate them on a gold standard dataset containing 4,105 excerpts annotated by medical experts for bias from a large corpus. We build on previous work by coauthors which augments the set of negative samples with non-annotated text containing social identifier terms. However, some of these terms, especially those related to race and ethnicity, can carry different meanings (e.g., "white matter of spinal cord"). To address this issue, we propose the use of Word Sense Disambiguation models to refine dataset quality by removing irrelevant sentences. We then evaluate fine-tuned variations of BERT models as well as GPT models with zero- and few-shot prompting. We found LLMs, considered SOTA on many NLP tasks, unsuitable for bias detection, while fine-tuned BERT models generally perform well across all evaluated metrics.
ClaimCompare: A Data Pipeline for Evaluation of Novelty Destroying Patent Pairs
Jul 16, 2024


A fundamental step in the patent application process is the determination of whether there exist prior patents that are novelty destroying. This step is routinely performed by both applicants and examiners, in order to assess the novelty of proposed inventions among the millions of applications filed annually. However, conducting this search is time and labor-intensive, as searchers must navigate complex legal and technical jargon while covering a large amount of legal claims. Automated approaches using information retrieval and machine learning approaches to detect novelty destroying patents present a promising avenue to streamline this process, yet research focusing on this space remains limited. In this paper, we introduce a novel data pipeline, ClaimCompare, designed to generate labeled patent claim datasets suitable for training IR and ML models to address this challenge of novelty destruction assessment. To the best of our knowledge, ClaimCompare is the first pipeline that can generate multiple novelty destroying patent datasets. To illustrate the practical relevance of this pipeline, we utilize it to construct a sample dataset comprising of over 27K patents in the electrochemical domain: 1,045 base patents from USPTO, each associated with 25 related patents labeled according to their novelty destruction towards the base patent. Subsequently, we conduct preliminary experiments showcasing the efficacy of this dataset in fine-tuning transformer models to identify novelty destroying patents, demonstrating 29.2% and 32.7% absolute improvement in MRR and P@1, respectively.
Quantifying Misalignment Between Agents
Jun 06, 2024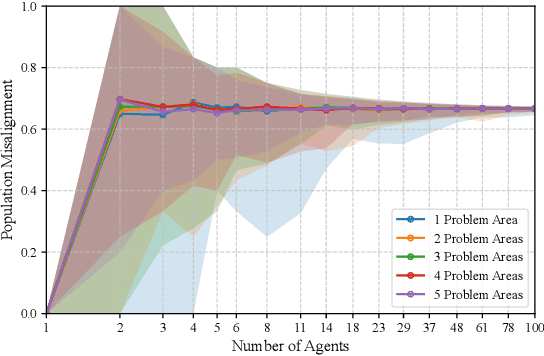
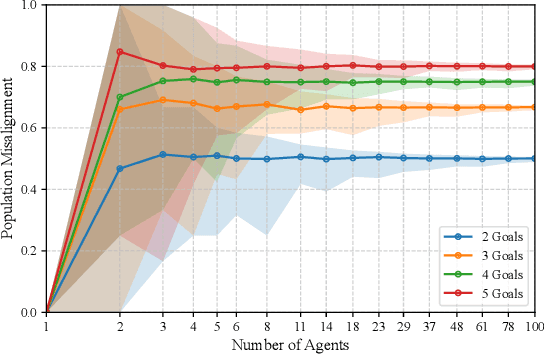
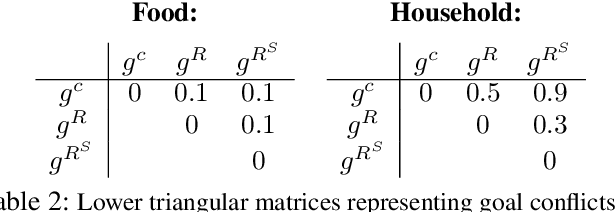
Growing concerns about the AI alignment problem have emerged in recent years, with previous work focusing mainly on (1) qualitative descriptions of the alignment problem; (2) attempting to align AI actions with human interests by focusing on value specification and learning; and/or (3) focusing on a single agent or on humanity as a singular unit. Recent work in sociotechnical AI alignment has made some progress in defining alignment inclusively, but the field as a whole still lacks a systematic understanding of how to specify, describe, and analyze misalignment among entities, which may include individual humans, AI agents, and complex compositional entities such as corporations, nation-states, and so forth. Previous work on controversy in computational social science offers a mathematical model of contention among populations (of humans). In this paper, we adapt this contention model to the alignment problem, and show how misalignment can vary depending on the population of agents (human or otherwise) being observed, the domain in question, and the agents' probability-weighted preferences between possible outcomes. Our model departs from value specification approaches and focuses instead on the morass of complex, interlocking, sometimes contradictory goals that agents may have in practice. We apply our model by analyzing several case studies ranging from social media moderation to autonomous vehicle behavior. By applying our model with appropriately representative value data, AI engineers can ensure that their systems learn values maximally aligned with diverse human interests.
SynDy: Synthetic Dynamic Dataset Generation Framework for Misinformation Tasks
May 17, 2024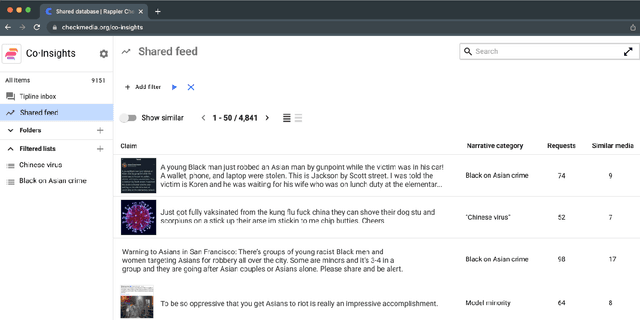
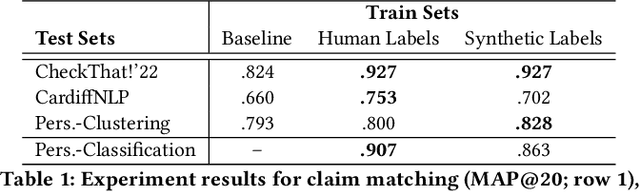
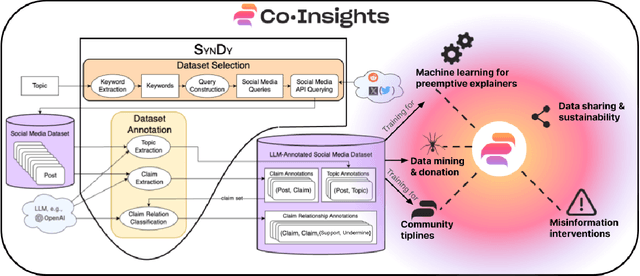
Diaspora communities are disproportionately impacted by off-the-radar misinformation and often neglected by mainstream fact-checking efforts, creating a critical need to scale-up efforts of nascent fact-checking initiatives. In this paper we present SynDy, a framework for Synthetic Dynamic Dataset Generation to leverage the capabilities of the largest frontier Large Language Models (LLMs) to train local, specialized language models. To the best of our knowledge, SynDy is the first paper utilizing LLMs to create fine-grained synthetic labels for tasks of direct relevance to misinformation mitigation, namely Claim Matching, Topical Clustering, and Claim Relationship Classification. SynDy utilizes LLMs and social media queries to automatically generate distantly-supervised, topically-focused datasets with synthetic labels on these three tasks, providing essential tools to scale up human-led fact-checking at a fraction of the cost of human-annotated data. Training on SynDy's generated labels shows improvement over a standard baseline and is not significantly worse compared to training on human labels (which may be infeasible to acquire). SynDy is being integrated into Meedan's chatbot tiplines that are used by over 50 organizations, serve over 230K users annually, and automatically distribute human-written fact-checks via messaging apps such as WhatsApp. SynDy will also be integrated into our deployed Co-Insights toolkit, enabling low-resource organizations to launch tiplines for their communities. Finally, we envision SynDy enabling additional fact-checking tools such as matching new misinformation claims to high-quality explainers on common misinformation topics.
Current and Near-Term AI as a Potential Existential Risk Factor
Sep 21, 2022

There is a substantial and ever-growing corpus of evidence and literature exploring the impacts of Artificial intelligence (AI) technologies on society, politics, and humanity as a whole. A separate, parallel body of work has explored existential risks to humanity, including but not limited to that stemming from unaligned Artificial General Intelligence (AGI). In this paper, we problematise the notion that current and near-term artificial intelligence technologies have the potential to contribute to existential risk by acting as intermediate risk factors, and that this potential is not limited to the unaligned AGI scenario. We propose the hypothesis that certain already-documented effects of AI can act as existential risk factors, magnifying the likelihood of previously identified sources of existential risk. Moreover, future developments in the coming decade hold the potential to significantly exacerbate these risk factors, even in the absence of artificial general intelligence. Our main contribution is a (non-exhaustive) exposition of potential AI risk factors and the causal relationships between them, focusing on how AI can affect power dynamics and information security. This exposition demonstrates that there exist causal pathways from AI systems to existential risks that do not presuppose hypothetical future AI capabilities.
Fairness via AI: Bias Reduction in Medical Information
Sep 06, 2021Most Fairness in AI research focuses on exposing biases in AI systems. A broader lens on fairness reveals that AI can serve a greater aspiration: rooting out societal inequities from their source. Specifically, we focus on inequities in health information, and aim to reduce bias in that domain using AI. The AI algorithms under the hood of search engines and social media, many of which are based on recommender systems, have an outsized impact on the quality of medical and health information online. Therefore, embedding bias detection and reduction into these recommender systems serving up medical and health content online could have an outsized positive impact on patient outcomes and wellbeing. In this position paper, we offer the following contributions: (1) we propose a novel framework of Fairness via AI, inspired by insights from medical education, sociology and antiracism; (2) we define a new term, bisinformation, which is related to, but distinct from, misinformation, and encourage researchers to study it; (3) we propose using AI to study, detect and mitigate biased, harmful, and/or false health information that disproportionately hurts minority groups in society; and (4) we suggest several pillars and pose several open problems in order to seed inquiry in this new space. While part (3) of this work specifically focuses on the health domain, the fundamental computer science advances and contributions stemming from research efforts in bias reduction and Fairness via AI have broad implications in all areas of society.