 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Misalignment Between Agents
Jun 06, 2024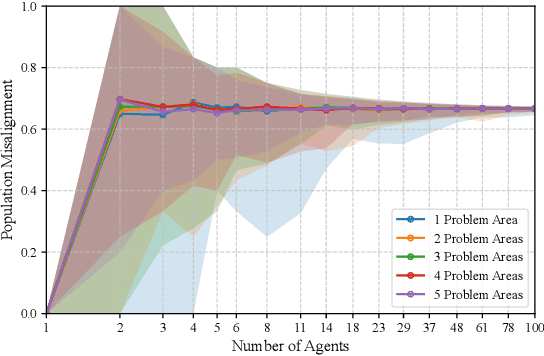
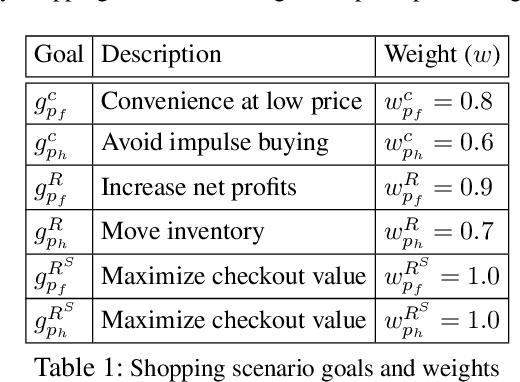
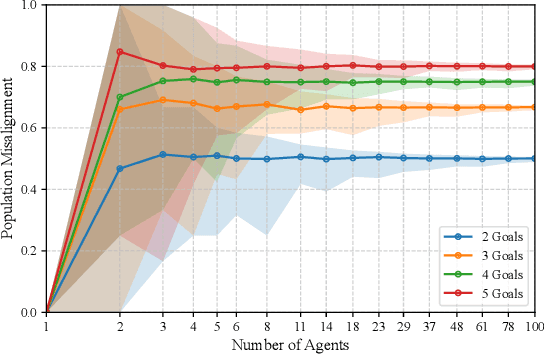
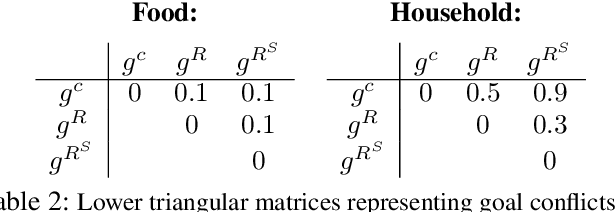
Growing concerns about the AI alignment problem have emerged in recent years, with previous work focusing mainly on (1) qualitative descriptions of the alignment problem; (2) attempting to align AI actions with human interests by focusing on value specification and learning; and/or (3) focusing on a single agent or on humanity as a singular unit. Recent work in sociotechnical AI alignment has made some progress in defining alignment inclusively, but the field as a whole still lacks a systematic understanding of how to specify, describe, and analyze misalignment among entities, which may include individual humans, AI agents, and complex compositional entities such as corporations, nation-states, and so forth. Previous work on controversy in computational social science offers a mathematical model of contention among populations (of humans). In this paper, we adapt this contention model to the alignment problem, and show how misalignment can vary depending on the population of agents (human or otherwise) being observed, the domain in question, and the agents' probability-weighted preferences between possible outcomes. Our model departs from value specification approaches and focuses instead on the morass of complex, interlocking, sometimes contradictory goals that agents may have in practice. We apply our model by analyzing several case studies ranging from social media moderation to autonomous vehicle behavior. By applying our model with appropriately representative value data, AI engineers can ensure that their systems learn values maximally aligned with diverse human interests.