 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynDy: Synthetic Dynamic Dataset Generation Framework for Misinformation Tasks
Paper and Code
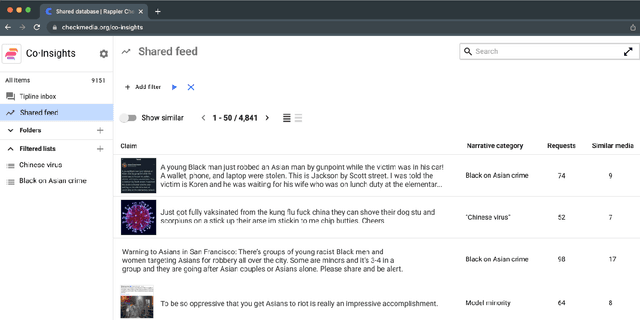
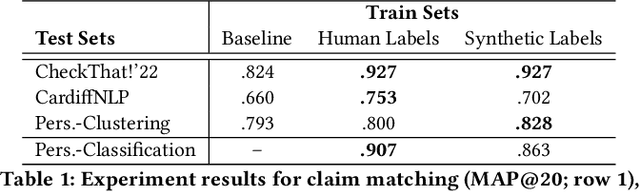
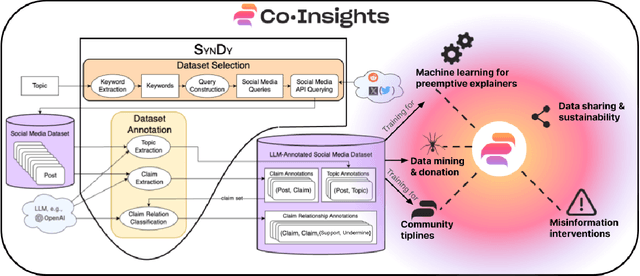
Diaspora communities are disproportionately impacted by off-the-radar misinformation and often neglected by mainstream fact-checking efforts, creating a critical need to scale-up efforts of nascent fact-checking initiatives. In this paper we present SynDy, a framework for Synthetic Dynamic Dataset Generation to leverage the capabilities of the largest frontier Large Language Models (LLMs) to train local, specialized language models. To the best of our knowledge, SynDy is the first paper utilizing LLMs to create fine-grained synthetic labels for tasks of direct relevance to misinformation mitigation, namely Claim Matching, Topical Clustering, and Claim Relationship Classification. SynDy utilizes LLMs and social media queries to automatically generate distantly-supervised, topically-focused datasets with synthetic labels on these three tasks, providing essential tools to scale up human-led fact-checking at a fraction of the cost of human-annotated data. Training on SynDy's generated labels shows improvement over a standard baseline and is not significantly worse compared to training on human labels (which may be infeasible to acquire). SynDy is being integrated into Meedan's chatbot tiplines that are used by over 50 organizations, serve over 230K users annually, and automatically distribute human-written fact-checks via messaging apps such as WhatsApp. SynDy will also be integrated into our deployed Co-Insights toolkit, enabling low-resource organizations to launch tiplines for their communities. Finally, we envision SynDy enabling additional fact-checking tools such as matching new misinformation claims to high-quality explainers on common misinformation topics.