 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeEvolve: An open source evolutionary coding agent for algorithm discovery and optimization
Oct 15, 2025In this work, we introduce CodeEvolve, an open-source evolutionary coding agent that unites Large Language Models (LLMs) with genetic algorithms to solve complex computational problems. Our framework adapts powerful evolutionary concepts to the LLM domain, building upon recent methods for generalized scientific discovery. CodeEvolve employs an island-based genetic algorithm to maintain population diversity and increase throughput, introduces a novel inspiration-based crossover mechanism that leverages the LLMs context window to combine features from successful solutions, and implements meta-prompting strategies for dynamic exploration of the solution space. We conduct a rigorous evaluation of CodeEvolve on a subset of the mathematical benchmarks used to evaluate Google DeepMind's closed-source AlphaEvolve. Our findings show that our method surpasses AlphaEvolve's performance on several challenging problems. To foster collaboration and accelerate progress, we release our complete framework as an open-source repository.
AI-Powered Detection of Inappropriate Language in Medical School Curricula
Aug 27, 2025The use of inappropriate language -- such as outdated, exclusionary, or non-patient-centered terms -- medical instructional materials can significantly influence clinical training, patient interactions, and health outcomes. Despite their reputability, many materials developed over past decades contain examples now considered inappropriate by current medical standards. Given the volume of curricular content, manually identifying instances of inappropriate use of language (IUL) and its subcategories for systematic review is prohibitively costly and impractical. To address this challenge, we conduct a first-in-class evaluation of small language models (SLMs) fine-tuned on labeled data and pre-trained LLMs with in-context learning on a dataset containing approximately 500 documents and over 12,000 pages. For SLMs, we consider: (1) a general IUL classifier, (2) subcategory-specific binary classifiers, (3) a multilabel classifier, and (4) a two-stage hierarchical pipeline for general IUL detection followed by multilabel classification. For LLMs, we consider variations of prompts that include subcategory definitions and/or shots. We found that both LLama-3 8B and 70B, even with carefully curated shots, are largely outperformed by SLMs. While the multilabel classifier performs best on annotated data, supplementing training with unflagged excerpts as negative examples boosts the specific classifiers' AUC by up to 25%, making them most effective models for mitigating harmful language in medical curricula.
CLaDMoP: Learning Transferrable Models from Successful Clinical Trials via LLMs
May 24, 2025Many existing models for clinical trial outcome prediction are optimized using task-specific loss functions on trial phase-specific data. While this scheme may boost prediction for common diseases and drugs, it can hinder learning of generalizable representations, leading to more false positives/negatives. To address this limitation, we introduce CLaDMoP, a new pre-training approach for clinical trial outcome prediction, alongside the Successful Clinical Trials dataset(SCT), specifically designed for this task. CLaDMoP leverages a Large Language Model-to encode trials' eligibility criteria-linked to a lightweight Drug-Molecule branch through a novel multi-level fusion technique. To efficiently fuse long embeddings across levels, we incorporate a grouping block, drastically reducing computational overhead. CLaDMoP avoids reliance on task-specific objectives by pre-training on a "pair matching" proxy task. Compared to established zero-shot and few-shot baselines, our method significantly improves both PR-AUC and ROC-AUC, especially for phase I and phase II trials. We further evaluate and perform ablation on CLaDMoP after Parameter-Efficient Fine-Tuning, comparing it to state-of-the-art supervised baselines, including MEXA-CTP, on the Trial Outcome Prediction(TOP) benchmark. CLaDMoP achieves up to 10.5% improvement in PR-AUC and 3.6% in ROC-AUC, while attaining comparable F1 score to MEXA-CTP, highlighting its potential for clinical trial outcome prediction. Code and SCT dataset can be downloaded from https://github.com/murai-lab/CLaDMoP.
KEDRec-LM: A Knowledge-distilled Explainable Drug Recommendation Large Language Model
Feb 27, 2025Drug discovery is a critical task in biomedical natural language processing (NLP), yet explainable drug discovery remains underexplored. Meanwhile, large language models (LLMs) have shown remarkable abilities in natural language understanding and generation. Leveraging LLMs for explainable drug discovery has the potential to improve downstream tasks and real-world applications. In this study, we utilize open-source drug knowledge graphs, clinical trial data, and PubMed publications to construct a comprehensive dataset for the explainable drug discovery task, named \textbf{expRxRec}. Furthermore, we introduce \textbf{KEDRec-LM}, an instruction-tuned LLM which distills knowledge from rich medical knowledge corpus for drug recommendation and rationale generation. To encourage further research in this area, we will publicly release\footnote{A copy is attached with this submission} both the dataset and KEDRec-LM.
MEXA-CTP: Mode Experts Cross-Attention for Clinical Trial Outcome Prediction
Jan 12, 2025Clinical trials are the gold standard for assessing the effectiveness and safety of drugs for treating diseases. Given the vast design space of drug molecules, elevated financial cost, and multi-year timeline of these trials, research on clinical trial outcome prediction has gained immense traction. Accurate predictions must leverage data of diverse modes such as drug molecules, target diseases, and eligibility criteria to infer successes and failures. Previous Deep Learning approaches for this task, such as HINT, often require wet lab data from synthesized molecules and/or rely on prior knowledge to encode interactions as part of the model architecture. To address these limitations, we propose a light-weight attention-based model, MEXA-CTP, to integrate readily-available multi-modal data and generate effective representations via specialized modules dubbed "mode experts", while avoiding human biases in model design. We optimize MEXA-CTP with the Cauchy loss to capture relevant interactions across modes. Our experiments on the Trial Outcome Prediction (TOP) benchmark demonstrate that MEXA-CTP improves upon existing approaches by, respectively, up to 11.3% in F1 score, 12.2% in PR-AUC, and 2.5% in ROC-AUC, compared to HINT. Ablation studies are provided to quantify the effectiveness of each component in our proposed method.
Towards Fairer Health Recommendations: finding informative unbiased samples via Word Sense Disambiguation
Sep 11, 2024
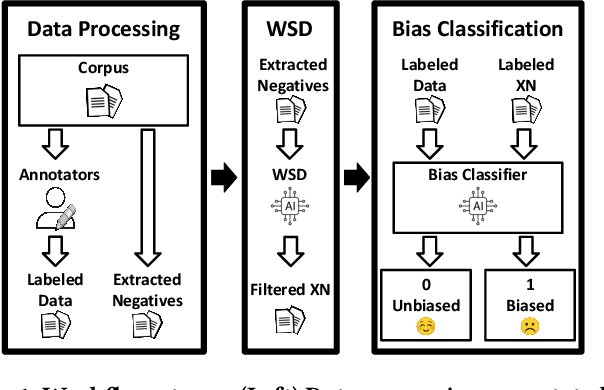

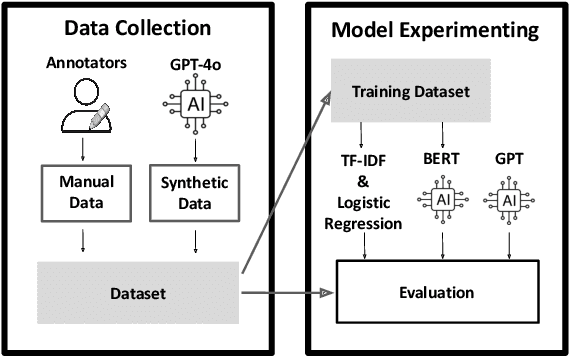
There have been growing concerns around high-stake applications that rely on models trained with biased data, which consequently produce biased predictions, often harming the most vulnerable. In particular, biased medical data could cause health-related applications and recommender systems to create outputs that jeopardize patient care and widen disparities in health outcomes. A recent framework titled Fairness via AI posits that, instead of attempting to correct model biases, researchers must focus on their root causes by using AI to debias data. Inspired by this framework, we tackle bias detection in medical curricula using NLP models, including LLMs, and evaluate them on a gold standard dataset containing 4,105 excerpts annotated by medical experts for bias from a large corpus. We build on previous work by coauthors which augments the set of negative samples with non-annotated text containing social identifier terms. However, some of these terms, especially those related to race and ethnicity, can carry different meanings (e.g., "white matter of spinal cord"). To address this issue, we propose the use of Word Sense Disambiguation models to refine dataset quality by removing irrelevant sentences. We then evaluate fine-tuned variations of BERT models as well as GPT models with zero- and few-shot prompting. We found LLMs, considered SOTA on many NLP tasks, unsuitable for bias detection, while fine-tuned BERT models generally perform well across all evaluated metrics.
Hidden or Inferred: Fair Learning-To-Rank with Unknown Demographics
Jul 24, 2024As learning-to-rank models are increasingly deployed for decision-making in areas with profound life implications, the FairML community has been developing fair learning-to-rank (LTR) models. These models rely on the availability of sensitive demographic features such as race or sex. However, in practice, regulatory obstacles and privacy concerns protect this data from collection and use. As a result, practitioners may either need to promote fairness despite the absence of these features or turn to demographic inference tools to attempt to infer them. Given that these tools are fallible, this paper aims to further understand how errors in demographic inference impact the fairness performance of popular fair LTR strategies. In which cases would it be better to keep such demographic attributes hidden from models versus infer them? We examine a spectrum of fair LTR strategies ranging from fair LTR with and without demographic features hidden versus inferred to fairness-unaware LTR followed by fair re-ranking. We conduct a controlled empirical investigation modeling different levels of inference errors by systematically perturbing the inferred sensitive attribute. We also perform three case studies with real-world datasets and popular open-source inference methods. Our findings reveal that as inference noise grows, LTR-based methods that incorporate fairness considerations into the learning process may increase bias. In contrast, fair re-ranking strategies are more robust to inference errors. All source code, data, and experimental artifacts of our experimental study are available here: https://github.com/sewen007/hoiltr.git
Towards Detecting Cascades of Biased Medical Claims on Twitter
Dec 22, 2023



Social media may disseminate medical claims that highlight misleading correlations between social identifiers and diseases due to not accounting for structural determinants of health. Our research aims to identify biased medical claims on Twitter and measure their spread. We propose a machine learning framework that uses two models in tandem: RoBERTa to detect medical claims and DistilBERT to classify bias. After identifying original biased medical claims, we conducted a retweet cascade analysis, computing their individual reach and rate of spread. Tweets containing biased claims were found to circulate faster and further than unbiased claims.
Delator: Automatic Detection of Money Laundering Evidence on Transaction Graphs via Neural Networks
May 20, 2022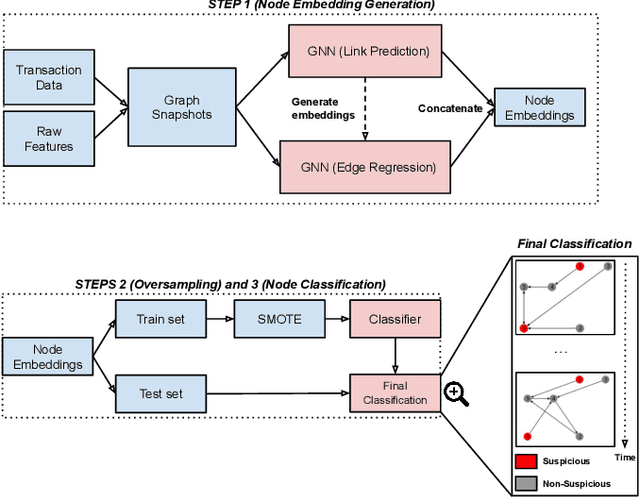


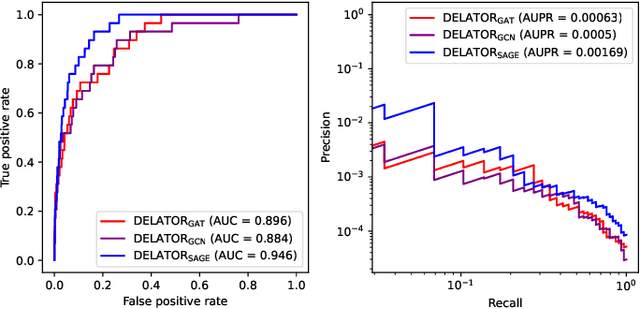
Money laundering is one of the most relevant criminal activities today, due to its potential to cause massive financial losses to governments, banks, etc. We propose DELATOR, a new CAAT (computer-assisted audit technology) to detect money laundering activities based on neural network models that encode bank transfers as a large-scale temporal graph. In collaboration with a Brazilian bank, we design and apply an evaluation strategy to quantify DELATOR's performance on historic data comprising millions of clients. DELATOR outperforms an off-the-shelf solution from Amazon AWS by 18.9% with respect to AUC. We conducted real experiments that led to discovery of 8 new suspicious among 100 analyzed cases, which would have been reported to the authorities under the current criteria.
Top-Down Deep Clustering with Multi-generator GANs
Dec 24, 2021
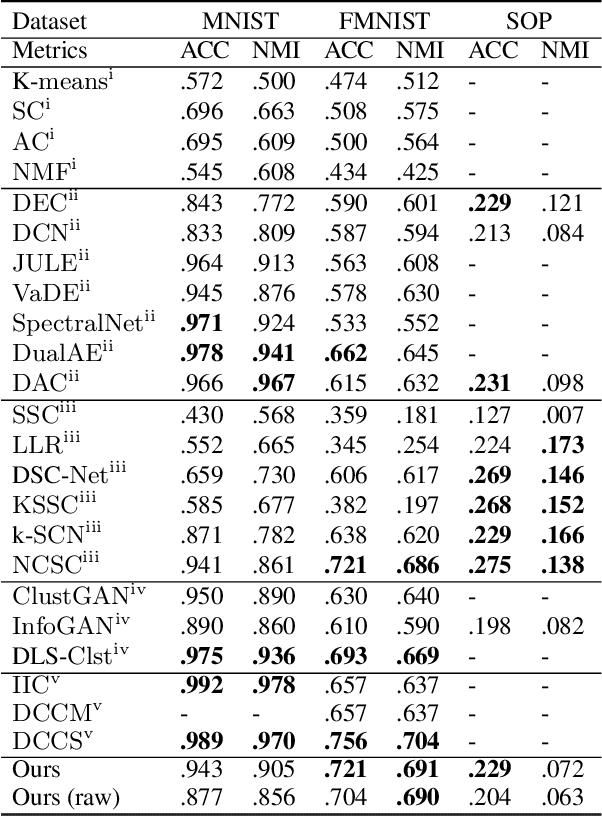
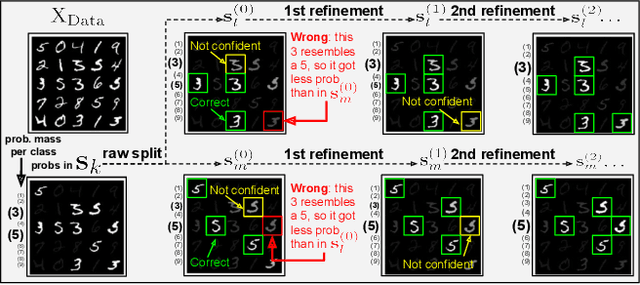

Deep clustering (DC) leverages the representation power of deep architectures to learn embedding spaces that are optimal for cluster analysis. This approach filters out low-level information irrelevant for clustering and has proven remarkably successful for high dimensional data spaces. Some DC methods employ Generative Adversarial Networks (GANs), motivated by the powerful latent representations these models are able to learn implicitly. In this work, we propose HC-MGAN, a new technique based on GANs with multiple generators (MGANs), which have not been explored for clustering. Our method is inspired by the observation that each generator of a MGAN tends to generate data that correlates with a sub-region of the real data distribution. We use this clustered generation to train a classifier for inferring from which generator a given image came from, thus providing a semantically meaningful clustering for the real distribution. Additionally, we design our method so that it is performed in a top-down hierarchical clustering tree, thus proposing the first hierarchical DC method, to the best of our knowledge. We conduct several experiments to evaluate the proposed method against recent DC methods, obtaining competitive results. Last, we perform an exploratory analysis of the hierarchical clustering tree that highlights how accurately it organizes the data in a hierarchy of semantically coherent patterns.