 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect, Localize, and Explain: Interactive Hierarchical Log Anomaly Analytics with LLM Augmentation
May 09, 2026Logs are ubiquitous in modern systems. Unfortunately, their unstructured nature in flat sequences limits understanding of execution behaviors, hindering effective anomaly diagnosis. To address this, Krone introduces a novel hierarchical log abstraction that transforms flat log sequences into semantically coherent units across entity, action, and status levels. Building on this abstraction, Krone introduces a hierarchical orchestration framework that decomposes flat log sequences into hierarchical execution units and performs modular detection over them. It executes and optimizes the modular detection tasks across levels, enabling precise anomaly detection, localization, and explanation with selective invocation of LLM-based reasoning. In this work, we present Krone-viz, an interactive visualization system based on Krone, which makes hierarchical log analysis interpretable and actionable for software engineers and system operators. Demonstrated on the widely used HDFS benchmark dataset, Krone-viz supports: 1) examining hierarchical decompositions of flat log sequences, 2) inspecting detection results and abnormal segments identified by Krone with LLM-generated explanations, and 3) reusing, reviewing, and revising knowledge generated by LLMs with human-in-the-loop guardrails. The code of Krone-viz is available at https://github.com/LeiMa0324/KRONE_Demo_official, and we deploy a live demo at https://leima0324.github.io/KRONE_Demo_official.
Student Mental Health Screening via Fitbit Data Collected During the COVID-19 Pandemic
Jan 22, 2026College students experience many stressors, resulting in high levels of anxiety and depression. Wearable technology provides unobtrusive sensor data that can be used for the early detection of mental illness. However, current research is limited concerning the variety of psychological instruments administered, physiological modalities, and time series parameters. In this research, we collect the Student Mental and Environmental Health (StudentMEH) Fitbit dataset from students at our institution during the pandemic. We provide a comprehensive assessment of the ability of predictive machine learning models to screen for depression, anxiety, and stress using different Fitbit modalities. Our findings indicate potential in physiological modalities such as heart rate and sleep to screen for mental illness with the F1 scores as high as 0.79 for anxiety, the former modality reaching 0.77 for stress screening, and the latter modality achieving 0.78 for depression. This research highlights the potential of wearable devices to support continuous mental health monitoring, the importance of identifying best data aggregation levels and appropriate modalities for screening for different mental ailments.
CLID-MU: Cross-Layer Information Divergence Based Meta Update Strategy for Learning with Noisy Labels
Jul 16, 2025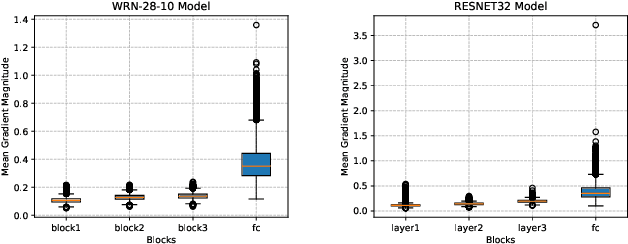
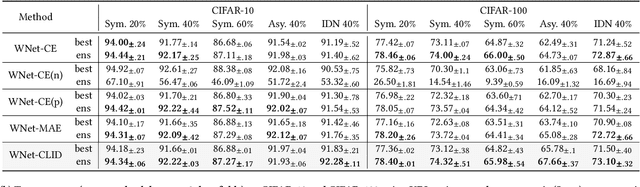
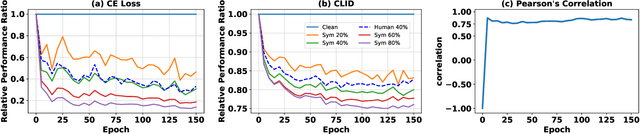
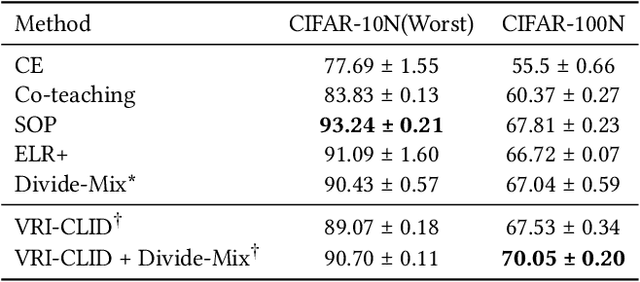
Learning with noisy labels (LNL) is essential for training deep neural networks with imperfect data. Meta-learning approaches have achieved success by using a clean unbiased labeled set to train a robust model. However, this approach heavily depends on the availability of a clean labeled meta-dataset, which is difficult to obtain in practice. In this work, we thus tackle the challenge of meta-learning for noisy label scenarios without relying on a clean labeled dataset. Our approach leverages the data itself while bypassing the need for labels. Building on the insight that clean samples effectively preserve the consistency of related data structures across the last hidden and the final layer, whereas noisy samples disrupt this consistency, we design the Cross-layer Information Divergence-based Meta Update Strategy (CLID-MU). CLID-MU leverages the alignment of data structures across these diverse feature spaces to evaluate model performance and use this alignment to guide training. Experiments on benchmark datasets with varying amounts of labels under both synthetic and real-world noise demonstrate that CLID-MU outperforms state-of-the-art methods. The code is released at https://github.com/ruofanhu/CLID-MU.
Deep Loss Convexification for Learning Iterative Models
Nov 16, 2024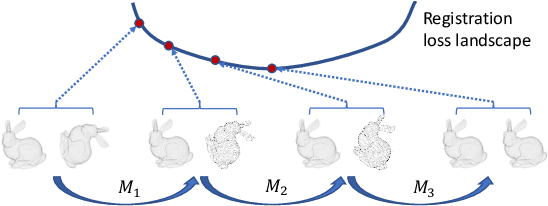
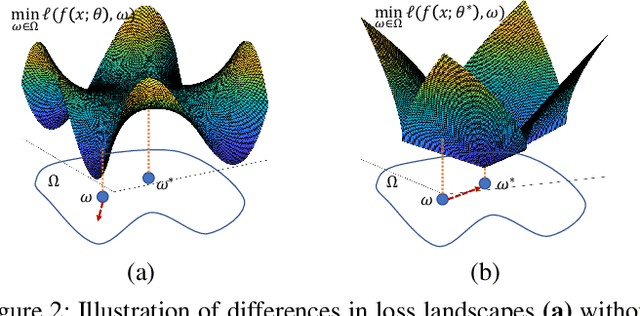
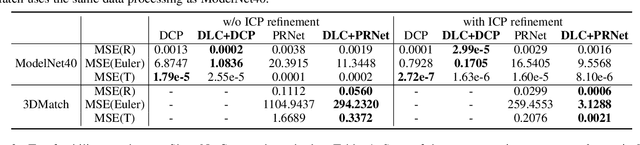
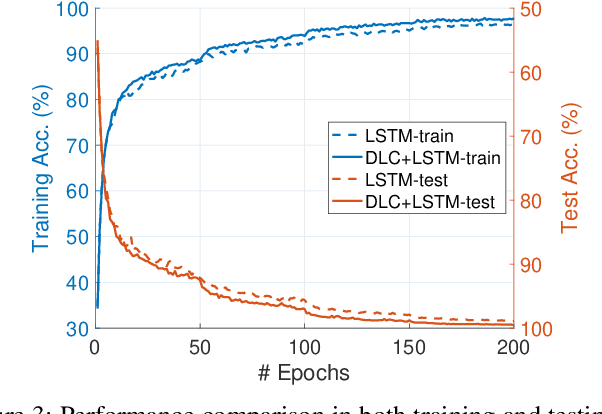
Iterative methods such as iterative closest point (ICP) for point cloud registration often suffer from bad local optimality (e.g. saddle points), due to the nature of nonconvex optimization. To address this fundamental challenge, in this paper we propose learning to form the loss landscape of a deep iterative method w.r.t. predictions at test time into a convex-like shape locally around each ground truth given data, namely Deep Loss Convexification (DLC), thanks to the overparametrization in neural networks. To this end, we formulate our learning objective based on adversarial training by manipulating the ground-truth predictions, rather than input data. In particular, we propose using star-convexity, a family of structured nonconvex functions that are unimodal on all lines that pass through a global minimizer, as our geometric constraint for reshaping loss landscapes, leading to (1) extra novel hinge losses appended to the original loss and (2) near-optimal predictions. We demonstrate the state-of-the-art performance using DLC with existing network architectures for the tasks of training recurrent neural networks (RNNs), 3D point cloud registration, and multimodel image alignment.
Hidden or Inferred: Fair Learning-To-Rank with Unknown Demographics
Jul 24, 2024As learning-to-rank models are increasingly deployed for decision-making in areas with profound life implications, the FairML community has been developing fair learning-to-rank (LTR) models. These models rely on the availability of sensitive demographic features such as race or sex. However, in practice, regulatory obstacles and privacy concerns protect this data from collection and use. As a result, practitioners may either need to promote fairness despite the absence of these features or turn to demographic inference tools to attempt to infer them. Given that these tools are fallible, this paper aims to further understand how errors in demographic inference impact the fairness performance of popular fair LTR strategies. In which cases would it be better to keep such demographic attributes hidden from models versus infer them? We examine a spectrum of fair LTR strategies ranging from fair LTR with and without demographic features hidden versus inferred to fairness-unaware LTR followed by fair re-ranking. We conduct a controlled empirical investigation modeling different levels of inference errors by systematically perturbing the inferred sensitive attribute. We also perform three case studies with real-world datasets and popular open-source inference methods. Our findings reveal that as inference noise grows, LTR-based methods that incorporate fairness considerations into the learning process may increase bias. In contrast, fair re-ranking strategies are more robust to inference errors. All source code, data, and experimental artifacts of our experimental study are available here: https://github.com/sewen007/hoiltr.git
CoLafier: Collaborative Noisy Label Purifier With Local Intrinsic Dimensionality Guidance
Jan 10, 2024Deep neural networks (DNNs) have advanced many machine learning tasks, but their performance is often harmed by noisy labels in real-world data. Addressing this, we introduce CoLafier, a novel approach that uses Local Intrinsic Dimensionality (LID) for learning with noisy labels. CoLafier consists of two subnets: LID-dis and LID-gen. LID-dis is a specialized classifier. Trained with our uniquely crafted scheme, LID-dis consumes both a sample's features and its label to predict the label - which allows it to produce an enhanced internal representation. We observe that LID scores computed from this representation effectively distinguish between correct and incorrect labels across various noise scenarios. In contrast to LID-dis, LID-gen, functioning as a regular classifier, operates solely on the sample's features. During training, CoLafier utilizes two augmented views per instance to feed both subnets. CoLafier considers the LID scores from the two views as produced by LID-dis to assign weights in an adapted loss function for both subnets. Concurrently, LID-gen, serving as classifier, suggests pseudo-labels. LID-dis then processes these pseudo-labels along with two views to derive LID scores. Finally, these LID scores along with the differences in predictions from the two subnets guide the label update decisions. This dual-view and dual-subnet approach enhances the overall reliability of the framework. Upon completion of the training, we deploy the LID-gen subnet of CoLafier as the final classification model. CoLafier demonstrates improved prediction accuracy, surpassing existing methods, particularly under severe label noise. For more details, see the code at https://github.com/zdy93/CoLafier.
UCE-FID: Using Large Unlabeled, Medium Crowdsourced-Labeled, and Small Expert-Labeled Tweets for Foodborne Illness Detection
Dec 02, 2023Foodborne illnesses significantly impact public health. Deep learning surveillance applications using social media data aim to detect early warning signals. However, labeling foodborne illness-related tweets for model training requires extensive human resources, making it challenging to collect a sufficient number of high-quality labels for tweets within a limited budget. The severe class imbalance resulting from the scarcity of foodborne illness-related tweets among the vast volume of social media further exacerbates the problem. Classifiers trained on a class-imbalanced dataset are biased towards the majority class, making accurate detection difficult. To overcome these challenges, we propose EGAL, a deep learning framework for foodborne illness detection that uses small expert-labeled tweets augmented by crowdsourced-labeled and massive unlabeled data. Specifically, by leveraging tweets labeled by experts as a reward set, EGAL learns to assign a weight of zero to incorrectly labeled tweets to mitigate their negative influence. Other tweets receive proportionate weights to counter-balance the unbalanced class distribution. Extensive experiments on real-world \textit{TWEET-FID} data show that EGAL outperforms strong baseline models across different settings, including varying expert-labeled set sizes and class imbalance ratios. A case study on a multistate outbreak of Salmonella Typhimurium infection linked to packaged salad greens demonstrates how the trained model captures relevant tweets offering valuable outbreak insights. EGAL, funded by the U.S. Department of Agriculture (USDA), has the potential to be deployed for real-time analysis of tweet streaming, contributing to foodborne illness outbreak surveillance efforts.
Finding Short Signals in Long Irregular Time Series with Continuous-Time Attention Policy Networks
Feb 08, 2023Irregularly-sampled time series (ITS) are native to high-impact domains like healthcare, where measurements are collected over time at uneven intervals. However, for many classification problems, only small portions of long time series are often relevant to the class label. In this case, existing ITS models often fail to classify long series since they rely on careful imputation, which easily over- or under-samples the relevant regions. Using this insight, we then propose CAT, a model that classifies multivariate ITS by explicitly seeking highly-relevant portions of an input series' timeline. CAT achieves this by integrating three components: (1) A Moment Network learns to seek relevant moments in an ITS's continuous timeline using reinforcement learning. (2) A Receptor Network models the temporal dynamics of both observations and their timing localized around predicted moments. (3) A recurrent Transition Model models the sequence of transitions between these moments, cultivating a representation with which the series is classified. Using synthetic and real data, we find that CAT outperforms ten state-of-the-art methods by finding short signals in long irregular time series.
Class-Specific Explainability for Deep Time Series Classifiers
Oct 11, 2022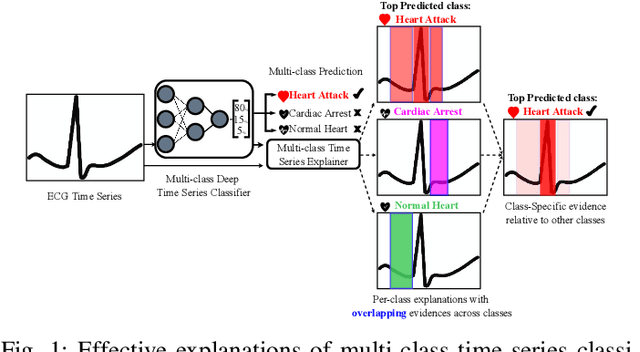
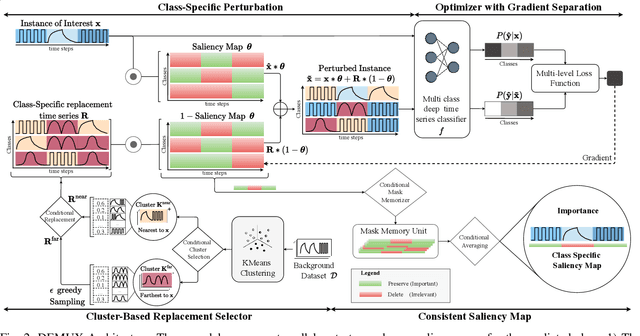

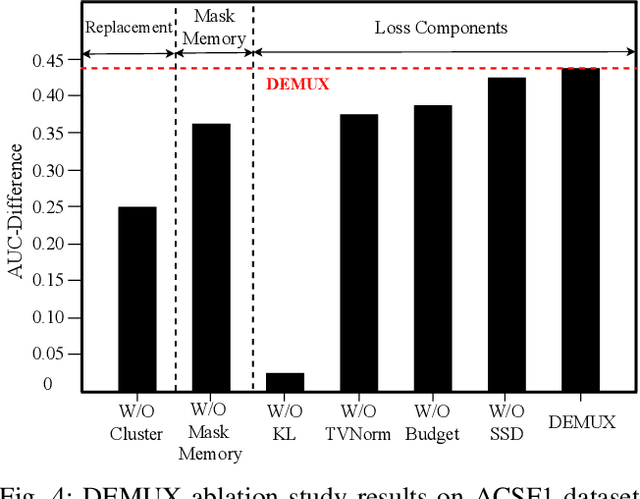
Explainability helps users trust deep learning solutions for time series classification. However, existing explainability methods for multi-class time series classifiers focus on one class at a time, ignoring relationships between the classes. Instead, when a classifier is choosing between many classes, an effective explanation must show what sets the chosen class apart from the rest. We now formalize this notion, studying the open problem of class-specific explainability for deep time series classifiers, a challenging and impactful problem setting. We design a novel explainability method, DEMUX, which learns saliency maps for explaining deep multi-class time series classifiers by adaptively ensuring that its explanation spotlights the regions in an input time series that a model uses specifically to its predicted class. DEMUX adopts a gradient-based approach composed of three interdependent modules that combine to generate consistent, class-specific saliency maps that remain faithful to the classifier's behavior yet are easily understood by end users. Our experimental study demonstrates that DEMUX outperforms nine state-of-the-art alternatives on five popular datasets when explaining two types of deep time series classifiers. Further, through a case study, we demonstrate that DEMUX's explanations indeed highlight what separates the predicted class from the others in the eyes of the classifier. Our code is publicly available at https://github.com/rameshdoddaiah/DEMUX.
Stop&Hop: Early Classification of Irregular Time Series
Aug 21, 2022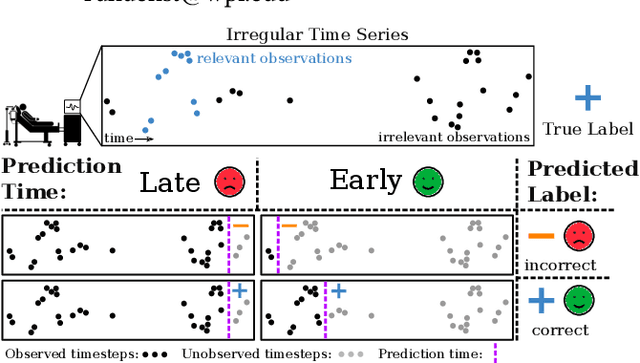
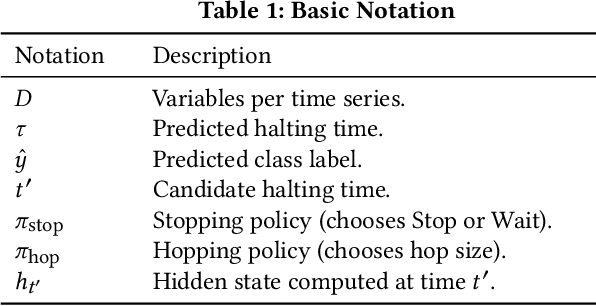
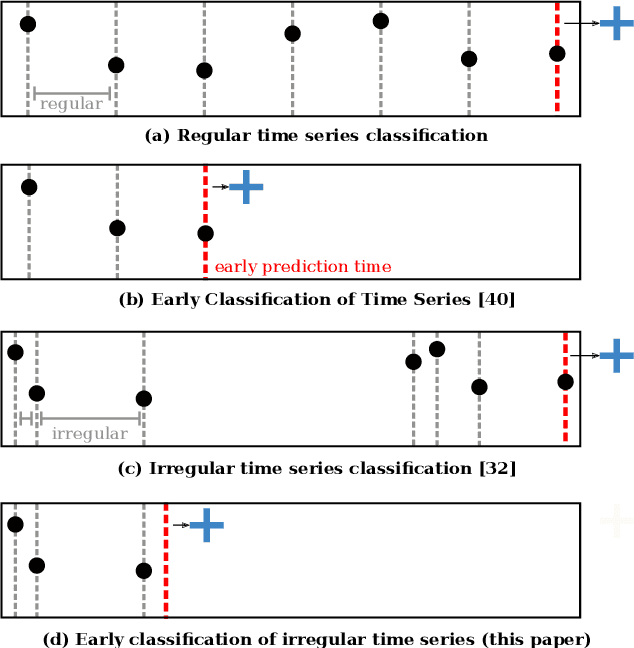
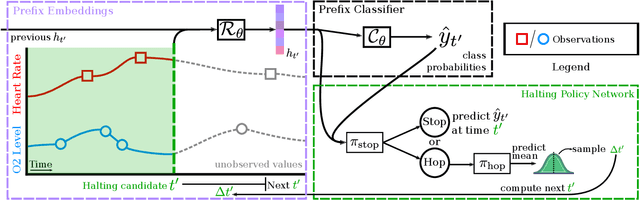
Early classification algorithms help users react faster to their machine learning model's predictions. Early warning systems in hospitals, for example, let clinicians improve their patients' outcomes by accurately predicting infections. While early classification systems are advancing rapidly, a major gap remains: existing systems do not consider irregular time series, which have uneven and often-long gaps between their observations. Such series are notoriously pervasive in impactful domains like healthcare. We bridge this gap and study early classification of irregular time series, a new setting for early classifiers that opens doors to more real-world problems. Our solution, Stop&Hop, uses a continuous-time recurrent network to model ongoing irregular time series in real time, while an irregularity-aware halting policy, trained with reinforcement learning, predicts when to stop and classify the streaming series. By taking real-valued step sizes, the halting policy flexibly decides exactly when to stop ongoing series in real time. This way, Stop&Hop seamlessly integrates information contained in the timing of observations, a new and vital source for early classification in this setting, with the time series values to provide early classifications for irregular time series. Using four synthetic and three real-world datasets, we demonstrate that Stop&Hop consistently makes earlier and more-accurate predictions than state-of-the-art alternatives adapted to this new problem. Our code is publicly available at https://github.com/thartvigsen/StopAndHop.