 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepEmotex: Classifying Emotion in Text Messages using Deep Transfer Learning
Jun 12, 2022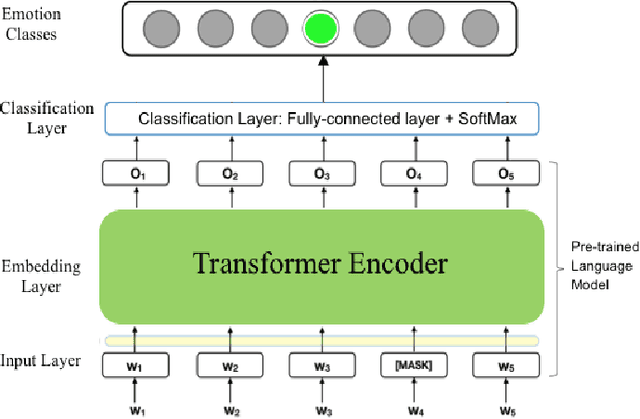
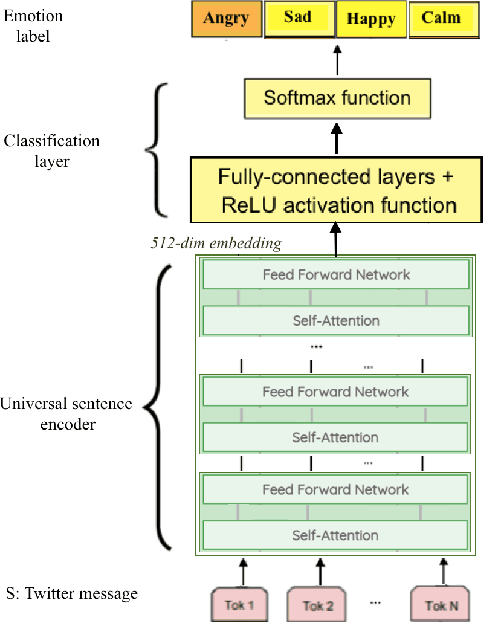


Transfer learning has been widely used in natural language processing through deep pretrained language models, such as Bidirectional Encoder Representations from Transformers and Universal Sentence Encoder. Despite the great success, language models get overfitted when applied to small datasets and are prone to forgetting when fine-tuned with a classifier. To remedy this problem of forgetting in transferring deep pretrained language models from one domain to another domain, existing efforts explore fine-tuning methods to forget less. We propose DeepEmotex an effective sequential transfer learning method to detect emotion in text. To avoid forgetting problem, the fine-tuning step is instrumented by a large amount of emotion-labeled data collected from Twitter. We conduct an experimental study using both curated Twitter data sets and benchmark data sets. DeepEmotex models achieve over 91% accuracy for multi-class emotion classification on test dataset. We evaluate the performance of the fine-tuned DeepEmotex models in classifying emotion in EmoInt and Stimulus benchmark datasets. The models correctly classify emotion in 73% of the instances in the benchmark datasets. The proposed DeepEmotex-BERT model outperforms Bi-LSTM result on the benchmark datasets by 23%. We also study the effect of the size of the fine-tuning dataset on the accuracy of our models. Our evaluation results show that fine-tuning with a large set of emotion-labeled data improves both the robustness and effectiveness of the resulting target task model.