 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCE-FID: Using Large Unlabeled, Medium Crowdsourced-Labeled, and Small Expert-Labeled Tweets for Foodborne Illness Detection
Dec 02, 2023Foodborne illnesses significantly impact public health. Deep learning surveillance applications using social media data aim to detect early warning signals. However, labeling foodborne illness-related tweets for model training requires extensive human resources, making it challenging to collect a sufficient number of high-quality labels for tweets within a limited budget. The severe class imbalance resulting from the scarcity of foodborne illness-related tweets among the vast volume of social media further exacerbates the problem. Classifiers trained on a class-imbalanced dataset are biased towards the majority class, making accurate detection difficult. To overcome these challenges, we propose EGAL, a deep learning framework for foodborne illness detection that uses small expert-labeled tweets augmented by crowdsourced-labeled and massive unlabeled data. Specifically, by leveraging tweets labeled by experts as a reward set, EGAL learns to assign a weight of zero to incorrectly labeled tweets to mitigate their negative influence. Other tweets receive proportionate weights to counter-balance the unbalanced class distribution. Extensive experiments on real-world \textit{TWEET-FID} data show that EGAL outperforms strong baseline models across different settings, including varying expert-labeled set sizes and class imbalance ratios. A case study on a multistate outbreak of Salmonella Typhimurium infection linked to packaged salad greens demonstrates how the trained model captures relevant tweets offering valuable outbreak insights. EGAL, funded by the U.S. Department of Agriculture (USDA), has the potential to be deployed for real-time analysis of tweet streaming, contributing to foodborne illness outbreak surveillance efforts.
TWEET-FID: An Annotated Dataset for Multiple Foodborne Illness Detection Tasks
May 22, 2022

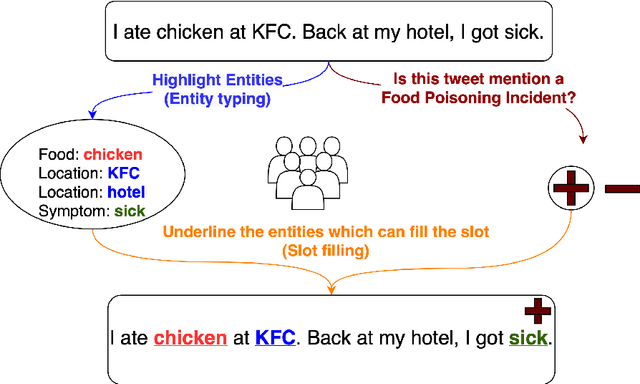
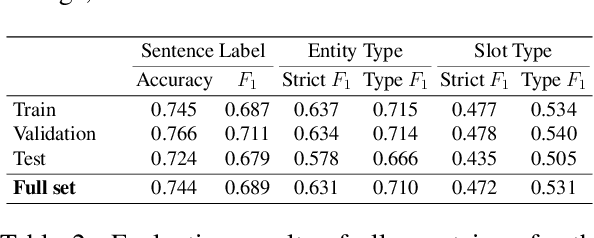
Foodborne illness is a serious but preventable public health problem -- with delays in detecting the associated outbreaks resulting in productivity loss, expensive recalls, public safety hazards, and even loss of life. While social media is a promising source for identifying unreported foodborne illnesses, there is a dearth of labeled datasets for developing effective outbreak detection models. To accelerate the development of machine learning-based models for foodborne outbreak detection, we thus present TWEET-FID (TWEET-Foodborne Illness Detection), the first publicly available annotated dataset for multiple foodborne illness incident detection tasks. TWEET-FID collected from Twitter is annotated with three facets: tweet class, entity type, and slot type, with labels produced by experts as well as by crowdsource workers. We introduce several domain tasks leveraging these three facets: text relevance classification (TRC), entity mention detection (EMD), and slot filling (SF). We describe the end-to-end methodology for dataset design, creation, and labeling for supporting model development for these tasks. A comprehensive set of results for these tasks leveraging state-of-the-art single- and multi-task deep learning methods on the TWEET-FID dataset are provided. This dataset opens opportunities for future research in foodborne outbreak detection.