 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Reasoning Recommendation via LLMs
Oct 23, 2025Despite their remarkable reasoning capabilities across diverse domains, large language models (LLMs) face fundamental challenges in natively functioning as generative reasoning recommendation models (GRRMs), where the intrinsic modeling gap between textual semantics and collaborative filtering signals, combined with the sparsity and stochasticity of user feedback, presents significant obstacles. This work explores how to build GRRMs by adapting pre-trained LLMs, which achieves a unified understanding-reasoning-prediction manner for recommendation tasks. We propose GREAM, an end-to-end framework that integrates three components: (i) Collaborative-Semantic Alignment, which fuses heterogeneous textual evidence to construct semantically consistent, discrete item indices and auxiliary alignment tasks that ground linguistic representations in interaction semantics; (ii) Reasoning Curriculum Activation, which builds a synthetic dataset with explicit Chain-of-Thought supervision and a curriculum that progresses through behavioral evidence extraction, latent preference modeling, intent inference, recommendation formulation, and denoised sequence rewriting; and (iii) Sparse-Regularized Group Policy Optimization (SRPO), which stabilizes post-training via Residual-Sensitive Verifiable Reward and Bonus-Calibrated Group Advantage Estimation, enabling end-to-end optimization under verifiable signals despite sparse successes. GREAM natively supports two complementary inference modes: Direct Sequence Recommendation for high-throughput, low-latency deployment, and Sequential Reasoning Recommendation that first emits an interpretable reasoning chain for causal transparency. Experiments on three datasets demonstrate consistent gains over strong baselines, providing a practical path toward verifiable-RL-driven LLM recommenders.
CLID-MU: Cross-Layer Information Divergence Based Meta Update Strategy for Learning with Noisy Labels
Jul 16, 2025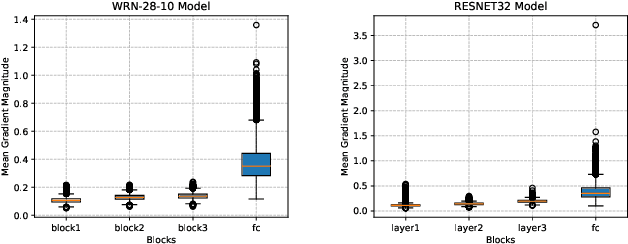
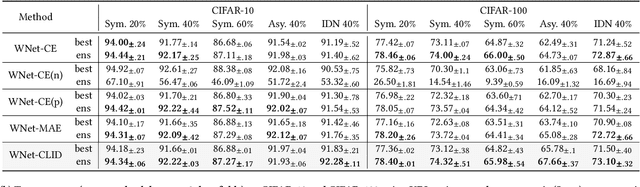
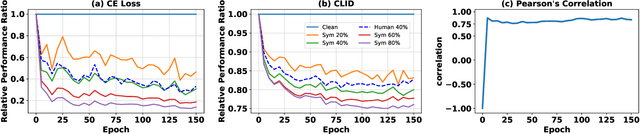
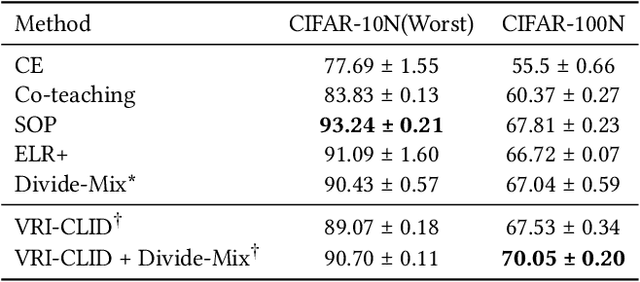
Learning with noisy labels (LNL) is essential for training deep neural networks with imperfect data. Meta-learning approaches have achieved success by using a clean unbiased labeled set to train a robust model. However, this approach heavily depends on the availability of a clean labeled meta-dataset, which is difficult to obtain in practice. In this work, we thus tackle the challenge of meta-learning for noisy label scenarios without relying on a clean labeled dataset. Our approach leverages the data itself while bypassing the need for labels. Building on the insight that clean samples effectively preserve the consistency of related data structures across the last hidden and the final layer, whereas noisy samples disrupt this consistency, we design the Cross-layer Information Divergence-based Meta Update Strategy (CLID-MU). CLID-MU leverages the alignment of data structures across these diverse feature spaces to evaluate model performance and use this alignment to guide training. Experiments on benchmark datasets with varying amounts of labels under both synthetic and real-world noise demonstrate that CLID-MU outperforms state-of-the-art methods. The code is released at https://github.com/ruofanhu/CLID-MU.
Vela: Scalable Embeddings with Voice Large Language Models for Multimodal Retrieval
Jun 17, 2025Multimodal large language models (MLLMs) have seen substantial progress in recent years. However, their ability to represent multimodal information in the acoustic domain remains underexplored. In this work, we introduce Vela, a novel framework designed to adapt MLLMs for the generation of universal multimodal embeddings. By leveraging MLLMs with specially crafted prompts and selected in-context learning examples, Vela effectively bridges the modality gap across various modalities. We then propose a single-modality training approach, where the model is trained exclusively on text pairs. Our experiments show that Vela outperforms traditional CLAP models in standard text-audio retrieval tasks. Furthermore, we introduce new benchmarks that expose CLAP models' limitations in handling long texts and complex retrieval tasks. In contrast, Vela, by harnessing the capabilities of MLLMs, demonstrates robust performance in these scenarios. Our code will soon be available.
OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
Jan 02, 2025



With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.
Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
Mar 18, 2024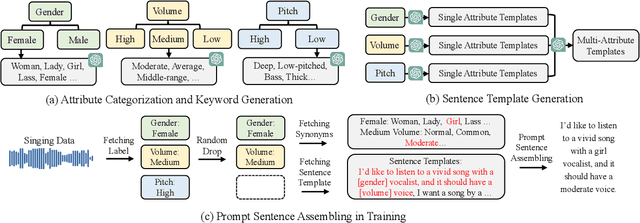
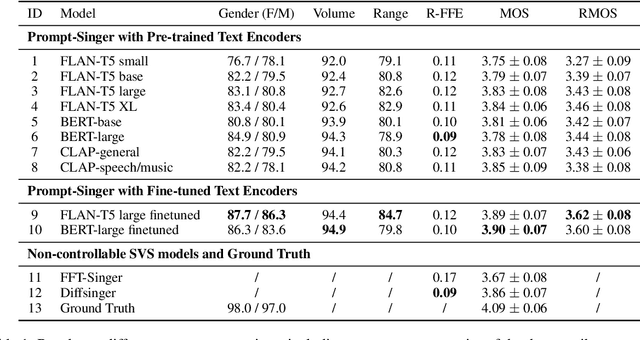
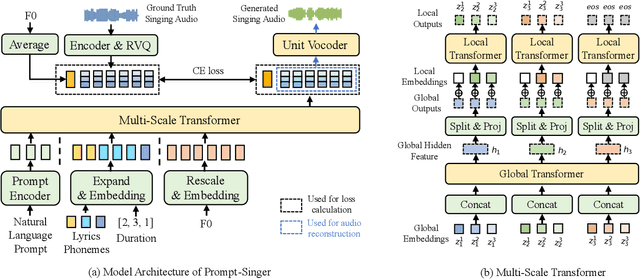
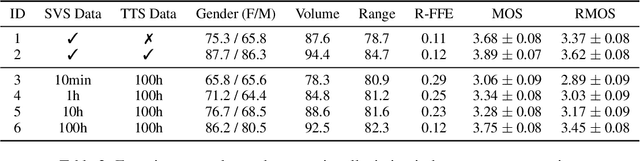
Recent singing-voice-synthesis (SVS) methods have achieved remarkable audio quality and naturalness, yet they lack the capability to control the style attributes of the synthesized singing explicitly. We propose Prompt-Singer, the first SVS method that enables attribute controlling on singer gender, vocal range and volume with natural language. We adopt a model architecture based on a decoder-only transformer with a multi-scale hierarchy, and design a range-melody decoupled pitch representation that enables text-conditioned vocal range control while keeping melodic accuracy. Furthermore, we explore various experiment settings, including different types of text representations, text encoder fine-tuning, and introducing speech data to alleviate data scarcity, aiming to facilitate further research. Experiments show that our model achieves favorable controlling ability and audio quality. Audio samples are available at http://prompt-singer.github.io .
CoLafier: Collaborative Noisy Label Purifier With Local Intrinsic Dimensionality Guidance
Jan 10, 2024Deep neural networks (DNNs) have advanced many machine learning tasks, but their performance is often harmed by noisy labels in real-world data. Addressing this, we introduce CoLafier, a novel approach that uses Local Intrinsic Dimensionality (LID) for learning with noisy labels. CoLafier consists of two subnets: LID-dis and LID-gen. LID-dis is a specialized classifier. Trained with our uniquely crafted scheme, LID-dis consumes both a sample's features and its label to predict the label - which allows it to produce an enhanced internal representation. We observe that LID scores computed from this representation effectively distinguish between correct and incorrect labels across various noise scenarios. In contrast to LID-dis, LID-gen, functioning as a regular classifier, operates solely on the sample's features. During training, CoLafier utilizes two augmented views per instance to feed both subnets. CoLafier considers the LID scores from the two views as produced by LID-dis to assign weights in an adapted loss function for both subnets. Concurrently, LID-gen, serving as classifier, suggests pseudo-labels. LID-dis then processes these pseudo-labels along with two views to derive LID scores. Finally, these LID scores along with the differences in predictions from the two subnets guide the label update decisions. This dual-view and dual-subnet approach enhances the overall reliability of the framework. Upon completion of the training, we deploy the LID-gen subnet of CoLafier as the final classification model. CoLafier demonstrates improved prediction accuracy, surpassing existing methods, particularly under severe label noise. For more details, see the code at https://github.com/zdy93/CoLafier.
UCE-FID: Using Large Unlabeled, Medium Crowdsourced-Labeled, and Small Expert-Labeled Tweets for Foodborne Illness Detection
Dec 02, 2023Foodborne illnesses significantly impact public health. Deep learning surveillance applications using social media data aim to detect early warning signals. However, labeling foodborne illness-related tweets for model training requires extensive human resources, making it challenging to collect a sufficient number of high-quality labels for tweets within a limited budget. The severe class imbalance resulting from the scarcity of foodborne illness-related tweets among the vast volume of social media further exacerbates the problem. Classifiers trained on a class-imbalanced dataset are biased towards the majority class, making accurate detection difficult. To overcome these challenges, we propose EGAL, a deep learning framework for foodborne illness detection that uses small expert-labeled tweets augmented by crowdsourced-labeled and massive unlabeled data. Specifically, by leveraging tweets labeled by experts as a reward set, EGAL learns to assign a weight of zero to incorrectly labeled tweets to mitigate their negative influence. Other tweets receive proportionate weights to counter-balance the unbalanced class distribution. Extensive experiments on real-world \textit{TWEET-FID} data show that EGAL outperforms strong baseline models across different settings, including varying expert-labeled set sizes and class imbalance ratios. A case study on a multistate outbreak of Salmonella Typhimurium infection linked to packaged salad greens demonstrates how the trained model captures relevant tweets offering valuable outbreak insights. EGAL, funded by the U.S. Department of Agriculture (USDA), has the potential to be deployed for real-time analysis of tweet streaming, contributing to foodborne illness outbreak surveillance efforts.
TWEET-FID: An Annotated Dataset for Multiple Foodborne Illness Detection Tasks
May 22, 2022

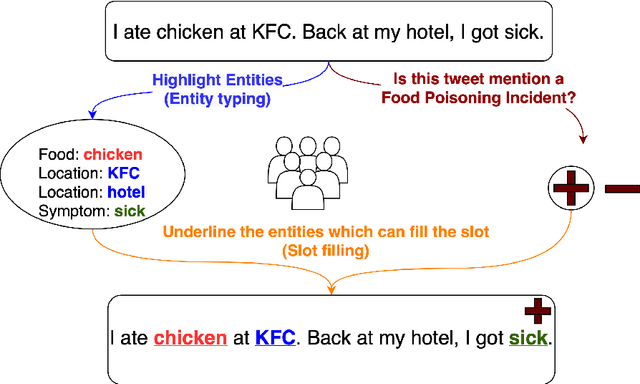
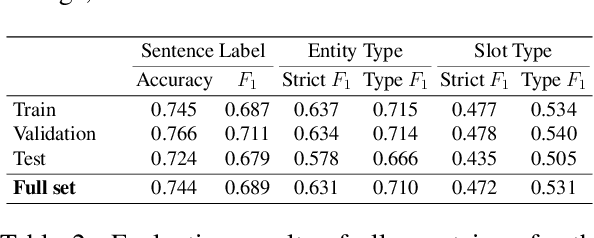
Foodborne illness is a serious but preventable public health problem -- with delays in detecting the associated outbreaks resulting in productivity loss, expensive recalls, public safety hazards, and even loss of life. While social media is a promising source for identifying unreported foodborne illnesses, there is a dearth of labeled datasets for developing effective outbreak detection models. To accelerate the development of machine learning-based models for foodborne outbreak detection, we thus present TWEET-FID (TWEET-Foodborne Illness Detection), the first publicly available annotated dataset for multiple foodborne illness incident detection tasks. TWEET-FID collected from Twitter is annotated with three facets: tweet class, entity type, and slot type, with labels produced by experts as well as by crowdsource workers. We introduce several domain tasks leveraging these three facets: text relevance classification (TRC), entity mention detection (EMD), and slot filling (SF). We describe the end-to-end methodology for dataset design, creation, and labeling for supporting model development for these tasks. A comprehensive set of results for these tasks leveraging state-of-the-art single- and multi-task deep learning methods on the TWEET-FID dataset are provided. This dataset opens opportunities for future research in foodborne outbreak detection.