 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Token Prediction via Compressed-to-fine Language Modeling for Speech Generation
May 30, 2025Neural audio codecs, used as speech tokenizers, have demonstrated remarkable potential in the field of speech generation. However, to ensure high-fidelity audio reconstruction, neural audio codecs typically encode audio into long sequences of speech tokens, posing a significant challenge for downstream language models in long-context modeling. We observe that speech token sequences exhibit short-range dependency: due to the monotonic alignment between text and speech in text-to-speech (TTS) tasks, the prediction of the current token primarily relies on its local context, while long-range tokens contribute less to the current token prediction and often contain redundant information. Inspired by this observation, we propose a \textbf{compressed-to-fine language modeling} approach to address the challenge of long sequence speech tokens within neural codec language models: (1) \textbf{Fine-grained Initial and Short-range Information}: Our approach retains the prompt and local tokens during prediction to ensure text alignment and the integrity of paralinguistic information; (2) \textbf{Compressed Long-range Context}: Our approach compresses long-range token spans into compact representations to reduce redundant information while preserving essential semantics. Extensive experiments on various neural audio codecs and downstream language models validate the effectiveness and generalizability of the proposed approach, highlighting the importance of token compression in improving speech generation within neural codec language models. The demo of audio samples will be available at https://anonymous.4open.science/r/SpeechTokenPredictionViaCompressedToFinedLM.
Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Feb 26, 2025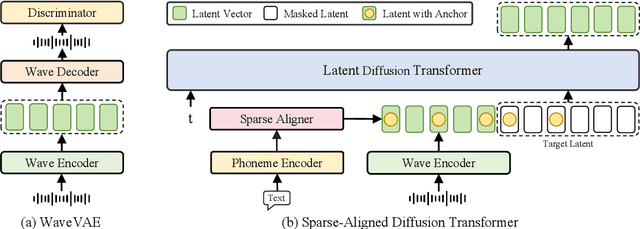
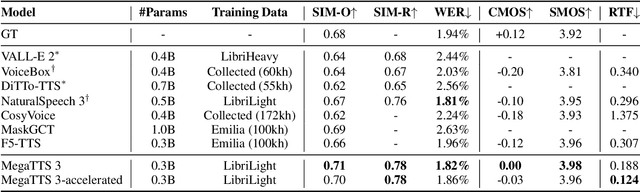
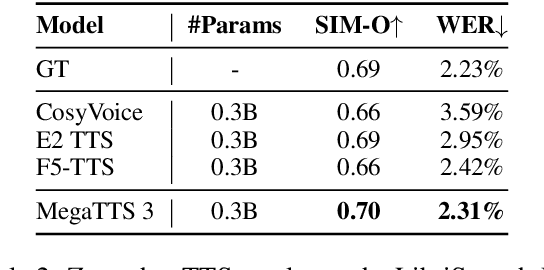

While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{S-DiT}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to S-DiT to reduce the difficulty of alignment learning without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that S-DiT achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
Jan 02, 2025



With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.