 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAM-LLM: A Modular, Open-Source Multimodal Large Language Model Framework and Best Practice for Speech, Language, Audio and Music Processing
Jan 14, 2026The recent surge in open-source Multimodal Large Language Models (MLLM) frameworks, such as LLaVA, provides a convenient kickoff for artificial intelligence developers and researchers. However, most of the MLLM frameworks take vision as the main input modality, and provide limited in-depth support for the modality of speech, audio, and music. This situation hinders the development of audio-language models, and forces researchers to spend a lot of effort on code writing and hyperparameter tuning. We present SLAM-LLM, an open-source deep learning framework designed to train customized MLLMs, focused on speech, language, audio, and music processing. SLAM-LLM provides a modular configuration of different encoders, projectors, LLMs, and parameter-efficient fine-tuning plugins. SLAM-LLM also includes detailed training and inference recipes for mainstream tasks, along with high-performance checkpoints like LLM-based Automatic Speech Recognition (ASR), Automated Audio Captioning (AAC), and Music Captioning (MC). Some of these recipes have already reached or are nearing state-of-the-art performance, and some relevant techniques have also been accepted by academic papers. We hope SLAM-LLM will accelerate iteration, development, data engineering, and model training for researchers. We are committed to continually pushing forward audio-based MLLMs through this open-source framework, and call on the community to contribute to the LLM-based speech, audio and music processing.
Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training
Jan 06, 2026Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
UltraVoice: Scaling Fine-Grained Style-Controlled Speech Conversations for Spoken Dialogue Models
Oct 26, 2025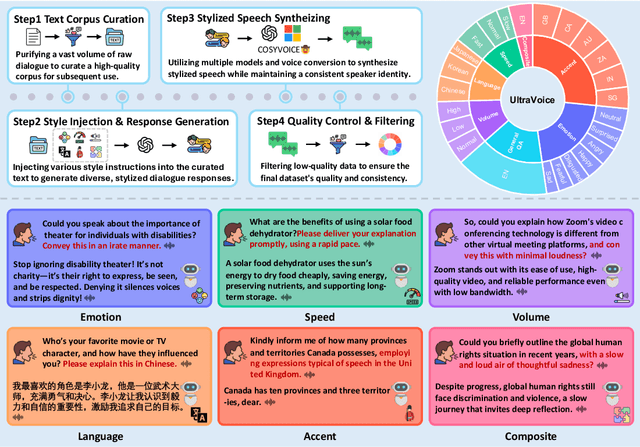
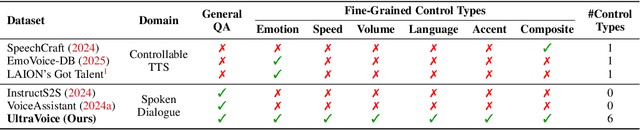
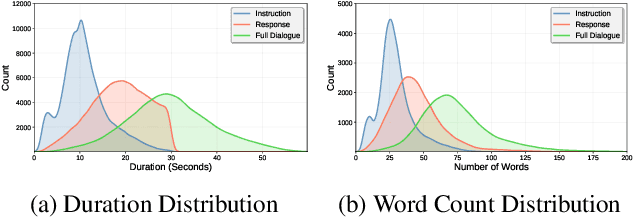

Spoken dialogue models currently lack the ability for fine-grained speech style control, a critical capability for human-like interaction that is often overlooked in favor of purely functional capabilities like reasoning and question answering. To address this limitation, we introduce UltraVoice, the first large-scale speech dialogue dataset engineered for multiple fine-grained speech style control. Encompassing over 830 hours of speech dialogues, UltraVoice provides instructions across six key speech stylistic dimensions: emotion, speed, volume, accent, language, and composite styles. Fine-tuning leading models such as SLAM-Omni and VocalNet on UltraVoice significantly enhances their fine-grained speech stylistic controllability without degrading core conversational abilities. Specifically, our fine-tuned models achieve improvements of 29.12-42.33% in Mean Opinion Score (MOS) and 14.61-40.09 percentage points in Instruction Following Rate (IFR) on multi-dimensional control tasks designed in the UltraVoice. Moreover, on the URO-Bench benchmark, our fine-tuned models demonstrate substantial gains in core understanding, reasoning, and conversational abilities, with average improvements of +10.84% on the Basic setting and +7.87% on the Pro setting. Furthermore, the dataset's utility extends to training controllable Text-to-Speech (TTS) models, underscoring its high quality and broad applicability for expressive speech synthesis. The complete dataset and model checkpoints are available at: https://github.com/bigai-nlco/UltraVoice.
Speech Token Prediction via Compressed-to-fine Language Modeling for Speech Generation
May 30, 2025Neural audio codecs, used as speech tokenizers, have demonstrated remarkable potential in the field of speech generation. However, to ensure high-fidelity audio reconstruction, neural audio codecs typically encode audio into long sequences of speech tokens, posing a significant challenge for downstream language models in long-context modeling. We observe that speech token sequences exhibit short-range dependency: due to the monotonic alignment between text and speech in text-to-speech (TTS) tasks, the prediction of the current token primarily relies on its local context, while long-range tokens contribute less to the current token prediction and often contain redundant information. Inspired by this observation, we propose a \textbf{compressed-to-fine language modeling} approach to address the challenge of long sequence speech tokens within neural codec language models: (1) \textbf{Fine-grained Initial and Short-range Information}: Our approach retains the prompt and local tokens during prediction to ensure text alignment and the integrity of paralinguistic information; (2) \textbf{Compressed Long-range Context}: Our approach compresses long-range token spans into compact representations to reduce redundant information while preserving essential semantics. Extensive experiments on various neural audio codecs and downstream language models validate the effectiveness and generalizability of the proposed approach, highlighting the importance of token compression in improving speech generation within neural codec language models. The demo of audio samples will be available at https://anonymous.4open.science/r/SpeechTokenPredictionViaCompressedToFinedLM.
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
May 23, 2025In our prior works, we introduced a scalable streaming speech synthesis model, CosyVoice 2, which integrates a large language model (LLM) and a chunk-aware flow matching (FM) model, and achieves low-latency bi-streaming speech synthesis and human-parity quality. Despite these advancements, CosyVoice 2 exhibits limitations in language coverage, domain diversity, data volume, text formats, and post-training techniques. In this paper, we present CosyVoice 3, an improved model designed for zero-shot multilingual speech synthesis in the wild, surpassing its predecessor in content consistency, speaker similarity, and prosody naturalness. Key features of CosyVoice 3 include: 1) A novel speech tokenizer to improve prosody naturalness, developed via supervised multi-task training, including automatic speech recognition, speech emotion recognition, language identification, audio event detection, and speaker analysis. 2) A new differentiable reward model for post-training applicable not only to CosyVoice 3 but also to other LLM-based speech synthesis models. 3) Dataset Size Scaling: Training data is expanded from ten thousand hours to one million hours, encompassing 9 languages and 18 Chinese dialects across various domains and text formats. 4) Model Size Scaling: Model parameters are increased from 0.5 billion to 1.5 billion, resulting in enhanced performance on our multilingual benchmark due to the larger model capacity. These advancements contribute significantly to the progress of speech synthesis in the wild. We encourage readers to listen to the demo at https://funaudiollm.github.io/cosyvoice3.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025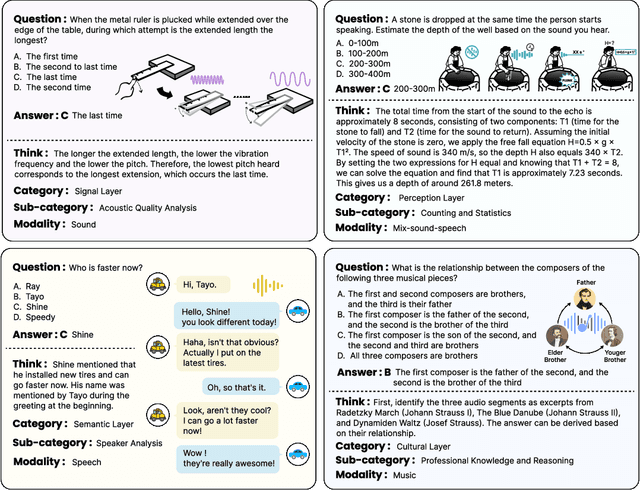

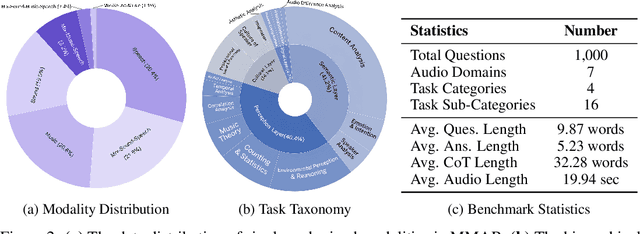
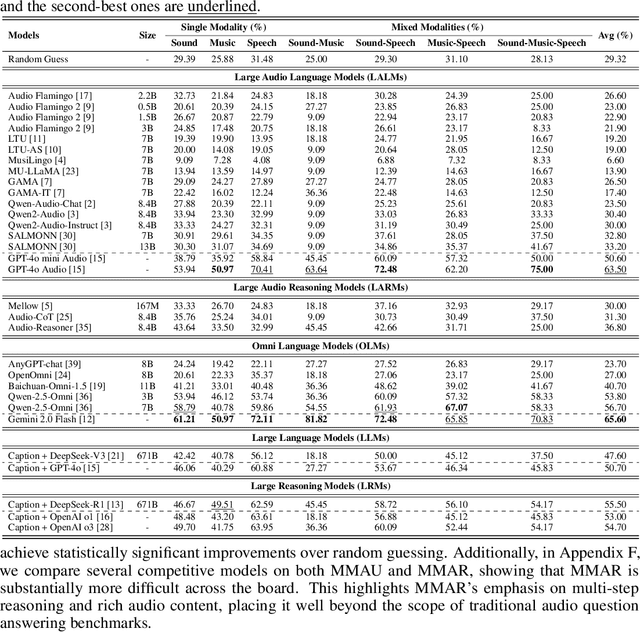
We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Apr 22, 2025Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://yanghaha0908.github.io/EmoVoice/. Dataset, code, and checkpoints will be released.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
CTC-Assisted LLM-Based Contextual ASR
Nov 10, 2024
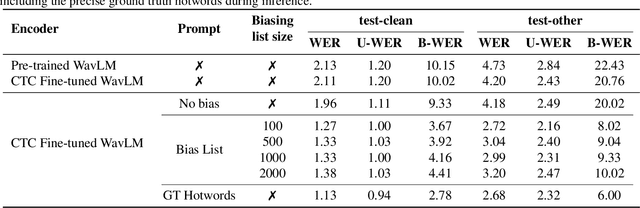
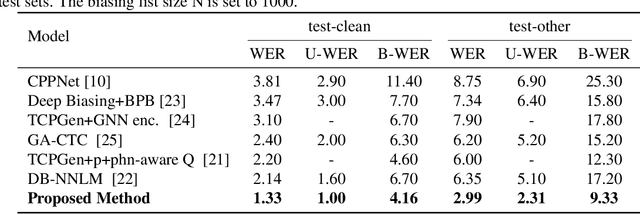

Contextual ASR or hotword customization holds substantial practical value. Despite the impressive performance of current end-to-end (E2E) automatic speech recognition (ASR) systems, they often face challenges in accurately recognizing rare words. Typical E2E contextual ASR models commonly feature complex architectures and decoding mechanisms, limited in performance and susceptible to interference from distractor words. With large language model (LLM)-based ASR models emerging as the new mainstream, we propose a CTC-Assisted LLM-Based Contextual ASR model with an efficient filtering algorithm. By using coarse CTC decoding results to filter potential relevant hotwords and incorporating them into LLM prompt input, our model attains WER/B-WER of 1.27%/3.67% and 2.72%/8.02% on the Librispeech test-clean and test-other sets targeting on recognizing rare long-tail words, demonstrating significant improvements compared to the baseline LLM-based ASR model, and substantially surpassing other related work. More remarkably, with the help of the large language model and proposed filtering algorithm, our contextual ASR model still performs well with 2000 biasing words.
Enhancing Low-Resource ASR through Versatile TTS: Bridging the Data Gap
Oct 22, 2024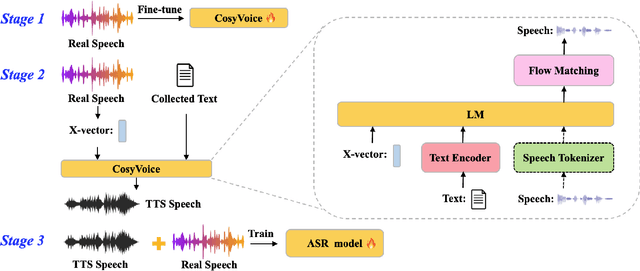
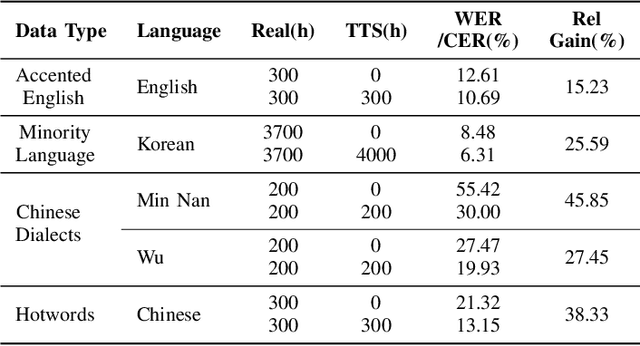

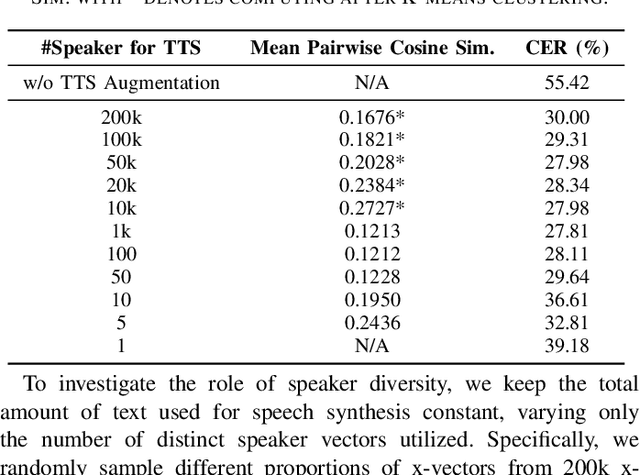
While automatic speech recognition (ASR) systems have achieved remarkable performance with large-scale datasets, their efficacy remains inadequate in low-resource settings, encompassing dialects, accents, minority languages, and long-tail hotwords, domains with significant practical relevance. With the advent of versatile and powerful text-to-speech (TTS) models, capable of generating speech with human-level naturalness, expressiveness, and diverse speaker profiles, leveraging TTS for ASR data augmentation provides a cost-effective and practical approach to enhancing ASR performance. Comprehensive experiments on an unprecedentedly rich variety of low-resource datasets demonstrate consistent and substantial performance improvements, proving that the proposed method of enhancing low-resource ASR through a versatile TTS model is highly effective and has broad application prospects. Furthermore, we delve deeper into key characteristics of synthesized speech data that contribute to ASR improvement, examining factors such as text diversity, speaker diversity, and the volume of synthesized data, with text diversity being studied for the first time in this work. We hope our findings provide helpful guidance and reference for the practical application of TTS-based data augmentation and push the advancement of low-resource ASR one step further.