 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Low-Resource ASR through Versatile TTS: Bridging the Data Gap
Paper and Code
Oct 22, 2024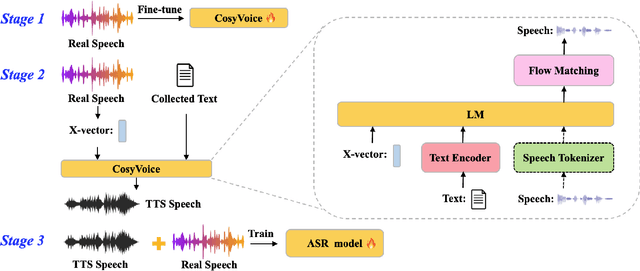
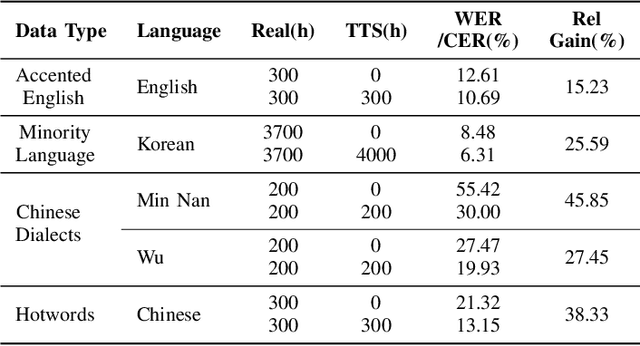

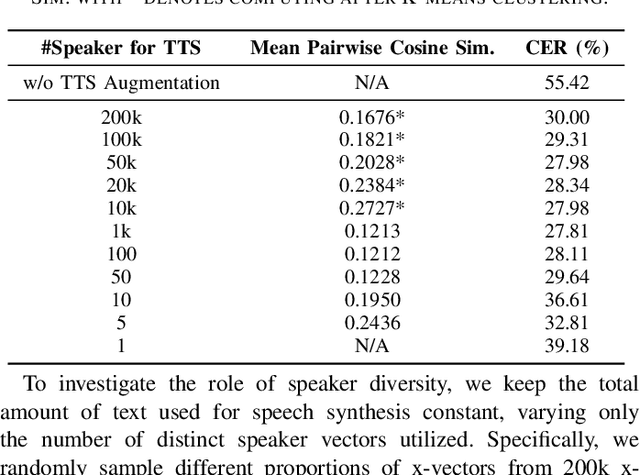
While automatic speech recognition (ASR) systems have achieved remarkable performance with large-scale datasets, their efficacy remains inadequate in low-resource settings, encompassing dialects, accents, minority languages, and long-tail hotwords, domains with significant practical relevance. With the advent of versatile and powerful text-to-speech (TTS) models, capable of generating speech with human-level naturalness, expressiveness, and diverse speaker profiles, leveraging TTS for ASR data augmentation provides a cost-effective and practical approach to enhancing ASR performance. Comprehensive experiments on an unprecedentedly rich variety of low-resource datasets demonstrate consistent and substantial performance improvements, proving that the proposed method of enhancing low-resource ASR through a versatile TTS model is highly effective and has broad application prospects. Furthermore, we delve deeper into key characteristics of synthesized speech data that contribute to ASR improvement, examining factors such as text diversity, speaker diversity, and the volume of synthesized data, with text diversity being studied for the first time in this work. We hope our findings provide helpful guidance and reference for the practical application of TTS-based data augmentation and push the advancement of low-resource ASR one step further.