 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Token Prediction via Compressed-to-fine Language Modeling for Speech Generation
May 30, 2025Neural audio codecs, used as speech tokenizers, have demonstrated remarkable potential in the field of speech generation. However, to ensure high-fidelity audio reconstruction, neural audio codecs typically encode audio into long sequences of speech tokens, posing a significant challenge for downstream language models in long-context modeling. We observe that speech token sequences exhibit short-range dependency: due to the monotonic alignment between text and speech in text-to-speech (TTS) tasks, the prediction of the current token primarily relies on its local context, while long-range tokens contribute less to the current token prediction and often contain redundant information. Inspired by this observation, we propose a \textbf{compressed-to-fine language modeling} approach to address the challenge of long sequence speech tokens within neural codec language models: (1) \textbf{Fine-grained Initial and Short-range Information}: Our approach retains the prompt and local tokens during prediction to ensure text alignment and the integrity of paralinguistic information; (2) \textbf{Compressed Long-range Context}: Our approach compresses long-range token spans into compact representations to reduce redundant information while preserving essential semantics. Extensive experiments on various neural audio codecs and downstream language models validate the effectiveness and generalizability of the proposed approach, highlighting the importance of token compression in improving speech generation within neural codec language models. The demo of audio samples will be available at https://anonymous.4open.science/r/SpeechTokenPredictionViaCompressedToFinedLM.
AutoStyle-TTS: Retrieval-Augmented Generation based Automatic Style Matching Text-to-Speech Synthesis
Apr 14, 2025With the advancement of speech synthesis technology, users have higher expectations for the naturalness and expressiveness of synthesized speech. But previous research ignores the importance of prompt selection. This study proposes a text-to-speech (TTS) framework based on Retrieval-Augmented Generation (RAG) technology, which can dynamically adjust the speech style according to the text content to achieve more natural and vivid communication effects. We have constructed a speech style knowledge database containing high-quality speech samples in various contexts and developed a style matching scheme. This scheme uses embeddings, extracted by Llama, PER-LLM-Embedder,and Moka, to match with samples in the knowledge database, selecting the most appropriate speech style for synthesis. Furthermore, our empirical research validates the effectiveness of the proposed method. Our demo can be viewed at: https://thuhcsi.github.io/icme2025-AutoStyle-TTS
UniSep: Universal Target Audio Separation with Language Models at Scale
Mar 31, 2025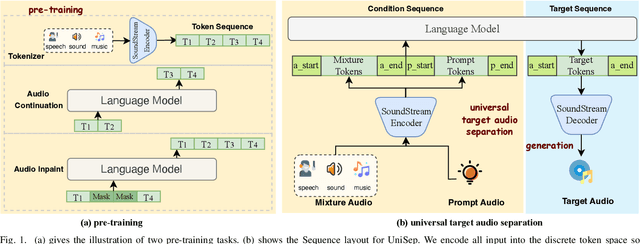
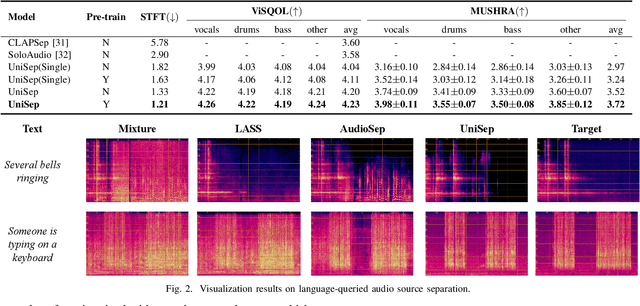

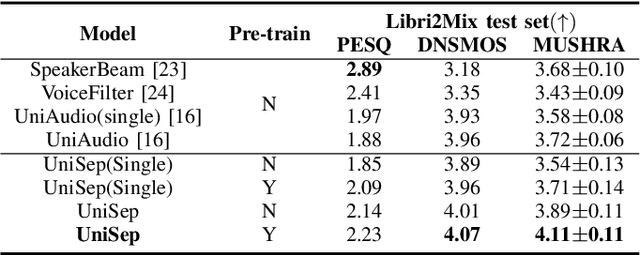
We propose Universal target audio Separation (UniSep), addressing the separation task on arbitrary mixtures of different types of audio. Distinguished from previous studies, UniSep is performed on unlimited source domains and unlimited source numbers. We formulate the separation task as a sequence-to-sequence problem, and a large language model (LLM) is used to model the audio sequence in the discrete latent space, leveraging the power of LLM in handling complex mixture audios with large-scale data. Moreover, a novel pre-training strategy is proposed to utilize audio-only data, which reduces the efforts of large-scale data simulation and enhances the ability of LLMs to understand the consistency and correlation of information within audio sequences. We also demonstrate the effectiveness of scaling datasets in an audio separation task: we use large-scale data (36.5k hours), including speech, music, and sound, to train a universal target audio separation model that is not limited to a specific domain. Experiments show that UniSep achieves competitive subjective and objective evaluation results compared with single-task models.
Spontaneous Style Text-to-Speech Synthesis with Controllable Spontaneous Behaviors Based on Language Models
Jul 18, 2024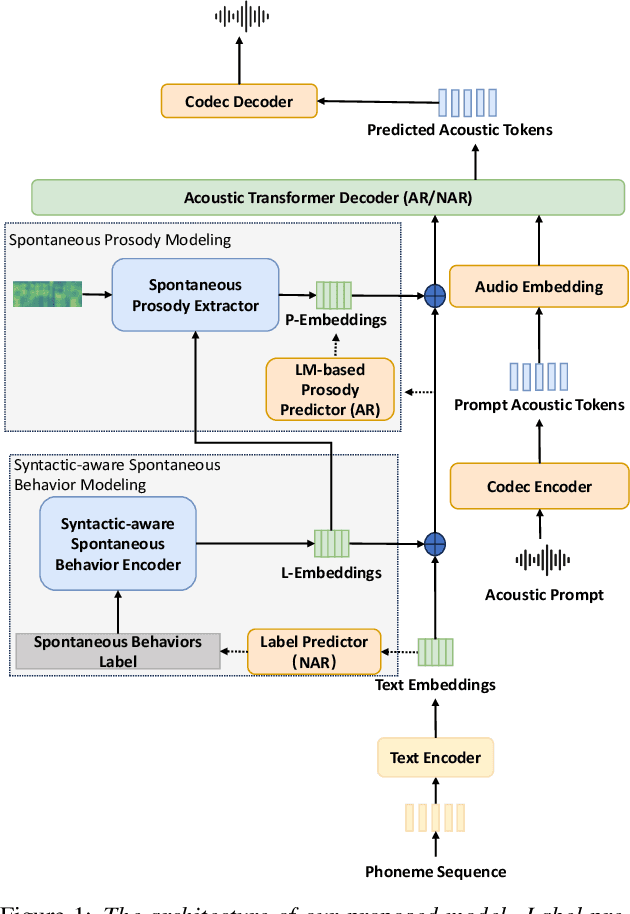
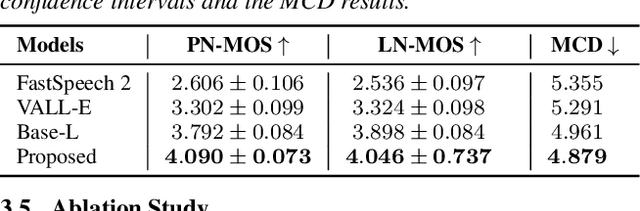
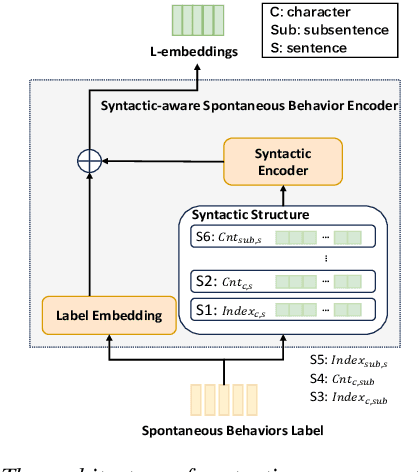
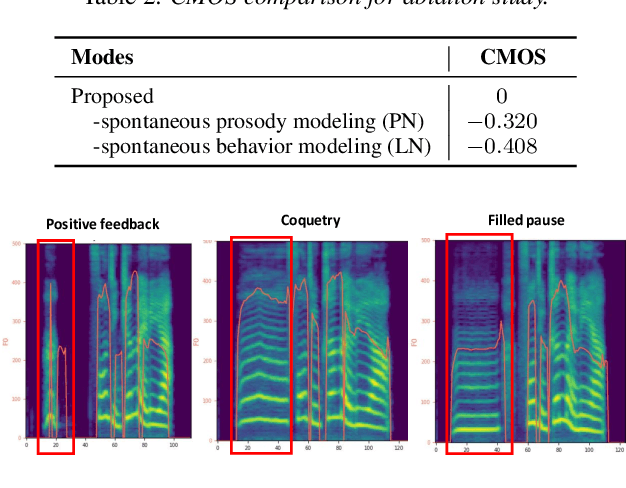
Spontaneous style speech synthesis, which aims to generate human-like speech, often encounters challenges due to the scarcity of high-quality data and limitations in model capabilities. Recent language model-based TTS systems can be trained on large, diverse, and low-quality speech datasets, resulting in highly natural synthesized speech. However, they are limited by the difficulty of simulating various spontaneous behaviors and capturing prosody variations in spontaneous speech. In this paper, we propose a novel spontaneous speech synthesis system based on language models. We systematically categorize and uniformly model diverse spontaneous behaviors. Moreover, fine-grained prosody modeling is introduced to enhance the model's ability to capture subtle prosody variations in spontaneous speech.Experimental results show that our proposed method significantly outperforms the baseline methods in terms of prosody naturalness and spontaneous behavior naturalness.
Towards Spontaneous Style Modeling with Semi-supervised Pre-training for Conversational Text-to-Speech Synthesis
Aug 31, 2023



The spontaneous behavior that often occurs in conversations makes speech more human-like compared to reading-style. However, synthesizing spontaneous-style speech is challenging due to the lack of high-quality spontaneous datasets and the high cost of labeling spontaneous behavior. In this paper, we propose a semi-supervised pre-training method to increase the amount of spontaneous-style speech and spontaneous behavioral labels. In the process of semi-supervised learning, both text and speech information are considered for detecting spontaneous behaviors labels in speech. Moreover, a linguistic-aware encoder is used to model the relationship between each sentence in the conversation. Experimental results indicate that our proposed method achieves superior expressive speech synthesis performance with the ability to model spontaneous behavior in spontaneous-style speech and predict reasonable spontaneous behavior from text.
GTN-Bailando: Genre Consistent Long-Term 3D Dance Generation based on Pre-trained Genre Token Network
Apr 25, 2023Music-driven 3D dance generation has become an intensive research topic in recent years with great potential for real-world applications. Most existing methods lack the consideration of genre, which results in genre inconsistency in the generated dance movements. In addition, the correlation between the dance genre and the music has not been investigated. To address these issues, we propose a genre-consistent dance generation framework, GTN-Bailando. First, we propose the Genre Token Network (GTN), which infers the genre from music to enhance the genre consistency of long-term dance generation. Second, to improve the generalization capability of the model, the strategy of pre-training and fine-tuning is adopted.Experimental results on the AIST++ dataset show that the proposed dance generation framework outperforms state-of-the-art methods in terms of motion quality and genre consistency.
Region-Manipulated Fusion Networks for Pancreatitis Recognition
Jul 03, 2019



This work first attempts to automatically recognize pancreatitis on CT scan images. However, different form the traditional object recognition, such pancreatitis recognition is challenging due to the fine-grained and non-rigid appearance variability of the local diseased regions. To this end, we propose a customized Region-Manipulated Fusion Networks (RMFN) to capture the key characteristics of local lesion for pancreatitis recognition. Specifically, to effectively highlight the imperceptible lesion regions, a novel region-manipulated scheme in RMFN is proposed to force the lesion regions while weaken the non-lesion regions by ceaselessly aggregating the multi-scale local information onto feature maps. The proposed scheme can be flexibly equipped into the existing neural networks, such as AlexNet and VGG. To evaluate the performance of the propose method, a real CT image database about pancreatitis is collected from hospitals \footnote{The database is available later}. And experimental results on such database well demonstrate the effectiveness of the proposed method for pancreatitis recognition.