 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTellWhisper: Tell Whisper Who Speaks When
Jan 08, 2026Multi-speaker automatic speech recognition (MASR) aims to predict ''who spoke when and what'' from multi-speaker speech, a key technology for multi-party dialogue understanding. However, most existing approaches decouple temporal modeling and speaker modeling when addressing ''when'' and ''who'': some inject speaker cues before encoding (e.g., speaker masking), which can cause irreversible information loss; others fuse identity by mixing speaker posteriors after encoding, which may entangle acoustic content with speaker identity. This separation is brittle under rapid turn-taking and overlapping speech, often leading to degraded performance. To address these limitations, we propose TellWhisper, a unified framework that jointly models speaker identity and temporal within the speech encoder. Specifically, we design TS-RoPE, a time-speaker rotary positional encoding: time coordinates are derived from frame indices, while speaker coordinates are derived from speaker activity and pause cues. By applying region-specific rotation angles, the model explicitly captures per-speaker continuity, speaker-turn transitions, and state dynamics, enabling the attention mechanism to simultaneously attend to ''when'' and ''who''. Moreover, to estimate frame-level speaker activity, we develop Hyper-SD, which casts speaker classification in hyperbolic space to enhance inter-class separation and refine speaker-activity estimates. Extensive experiments demonstrate the effectiveness of the proposed approach.
Optimizing Neural Speech Codec for Low-Bitrate Compression via Multi-Scale Encoding
Oct 21, 2024



Neural speech codecs have demonstrated their ability to compress high-quality speech and audio by converting them into discrete token representations. Most existing methods utilize Residual Vector Quantization (RVQ) to encode speech into multiple layers of discrete codes with uniform time scales. However, this strategy overlooks the differences in information density across various speech features, leading to redundant encoding of sparse information, which limits the performance of these methods at low bitrate. This paper proposes MsCodec, a novel multi-scale neural speech codec that encodes speech into multiple layers of discrete codes, each corresponding to a different time scale. This encourages the model to decouple speech features according to their diverse information densities, consequently enhancing the performance of speech compression. Furthermore, we incorporate mutual information loss to augment the diversity among speech codes across different layers. Experimental results indicate that our proposed method significantly improves codec performance at low bitrate.
Spontaneous Style Text-to-Speech Synthesis with Controllable Spontaneous Behaviors Based on Language Models
Jul 18, 2024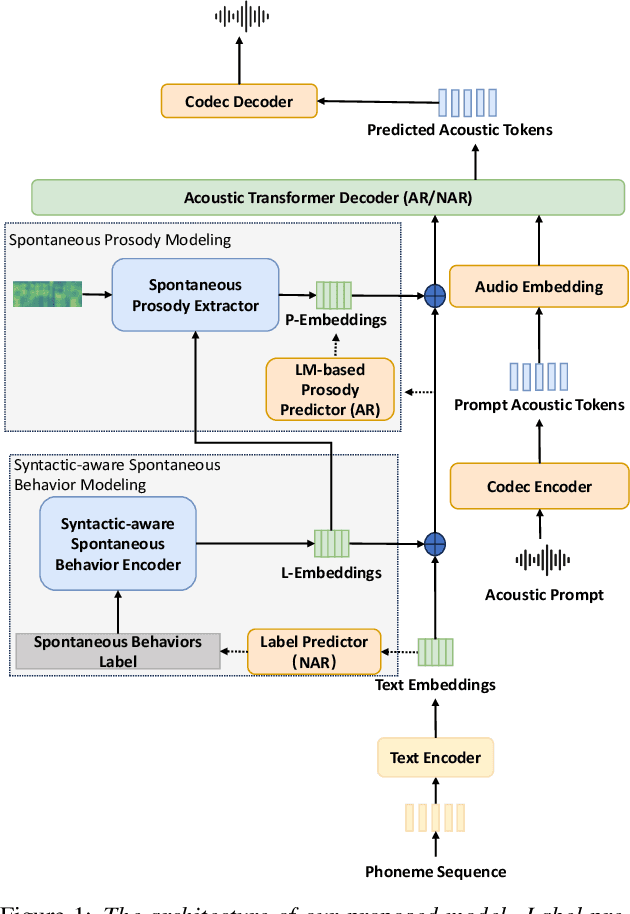
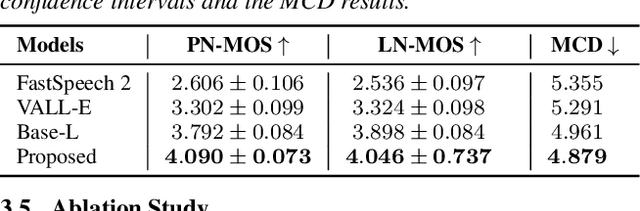
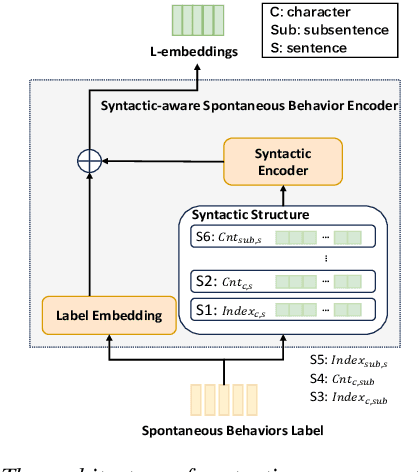
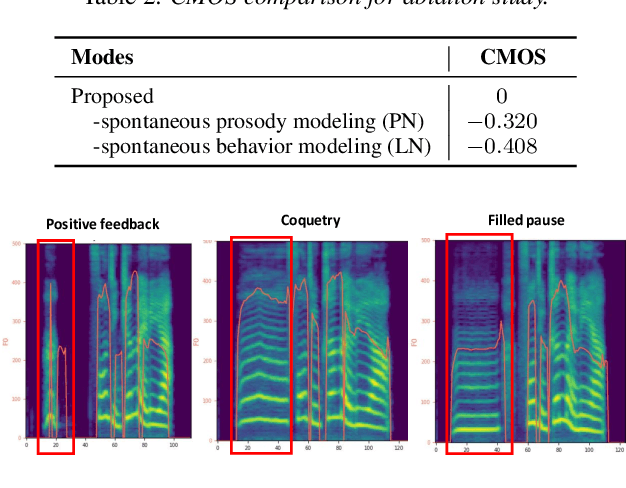
Spontaneous style speech synthesis, which aims to generate human-like speech, often encounters challenges due to the scarcity of high-quality data and limitations in model capabilities. Recent language model-based TTS systems can be trained on large, diverse, and low-quality speech datasets, resulting in highly natural synthesized speech. However, they are limited by the difficulty of simulating various spontaneous behaviors and capturing prosody variations in spontaneous speech. In this paper, we propose a novel spontaneous speech synthesis system based on language models. We systematically categorize and uniformly model diverse spontaneous behaviors. Moreover, fine-grained prosody modeling is introduced to enhance the model's ability to capture subtle prosody variations in spontaneous speech.Experimental results show that our proposed method significantly outperforms the baseline methods in terms of prosody naturalness and spontaneous behavior naturalness.
ExpCLIP: Bridging Text and Facial Expressions via Semantic Alignment
Sep 11, 2023The objective of stylized speech-driven facial animation is to create animations that encapsulate specific emotional expressions. Existing methods often depend on pre-established emotional labels or facial expression templates, which may limit the necessary flexibility for accurately conveying user intent. In this research, we introduce a technique that enables the control of arbitrary styles by leveraging natural language as emotion prompts. This technique presents benefits in terms of both flexibility and user-friendliness. To realize this objective, we initially construct a Text-Expression Alignment Dataset (TEAD), wherein each facial expression is paired with several prompt-like descriptions.We propose an innovative automatic annotation method, supported by Large Language Models (LLMs), to expedite the dataset construction, thereby eliminating the substantial expense of manual annotation. Following this, we utilize TEAD to train a CLIP-based model, termed ExpCLIP, which encodes text and facial expressions into semantically aligned style embeddings. The embeddings are subsequently integrated into the facial animation generator to yield expressive and controllable facial animations. Given the limited diversity of facial emotions in existing speech-driven facial animation training data, we further introduce an effective Expression Prompt Augmentation (EPA) mechanism to enable the animation generator to support unprecedented richness in style control. Comprehensive experiments illustrate that our method accomplishes expressive facial animation generation and offers enhanced flexibility in effectively conveying the desired style.
AccentSpeech: Learning Accent from Crowd-sourced Data for Target Speaker TTS with Accents
Oct 31, 2022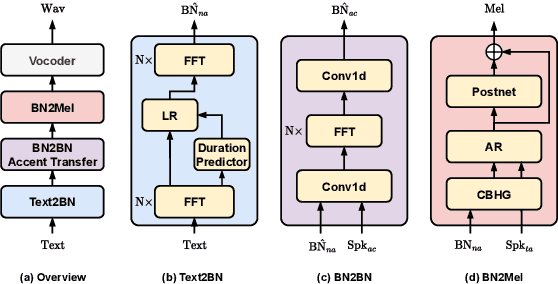
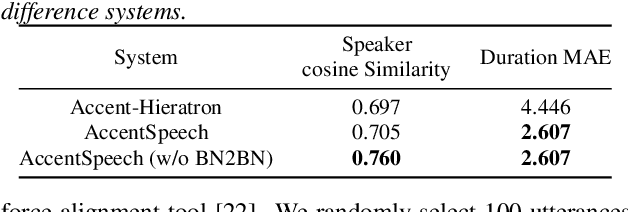
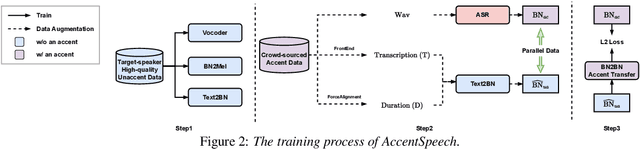
Learning accent from crowd-sourced data is a feasible way to achieve a target speaker TTS system that can synthesize accent speech. To this end, there are two challenging problems to be solved. First, direct use of the poor acoustic quality crowd-sourced data and the target speaker data in accent transfer will apparently lead to synthetic speech with degraded quality. To mitigate this problem, we take a bottleneck feature (BN) based TTS approach, in which TTS is decomposed into a Text-to-BN (T2BN) module to learn accent and a BN-to-Mel (BN2Mel) module to learn speaker timbre, where neural network based BN feature serves as the intermediate representation that are robust to noise interference. Second, direct training T2BN using the crowd-sourced data in the two-stage system will produce accent speech of target speaker with poor prosody. This is because the the crowd-sourced recordings are contributed from the ordinary unprofessional speakers. To tackle this problem, we update the two-stage approach to a novel three-stage approach, where T2BN and BN2Mel are trained using the high-quality target speaker data and a new BN-to-BN module is plugged in between the two modules to perform accent transfer. To train the BN2BN module, the parallel unaccented and accented BN features are obtained by a proposed data augmentation procedure. Finally the proposed three-stage approach manages to produce accent speech for the target speaker with good prosody, as the prosody pattern is inherited from the professional target speaker and accent transfer is achieved by the BN2BN module at the same time. The proposed approach, named as AccentSpeech, is validated in a Mandarin TTS accent transfer task.
Cross-lingual Text Classification with Heterogeneous Graph Neural Network
May 24, 2021

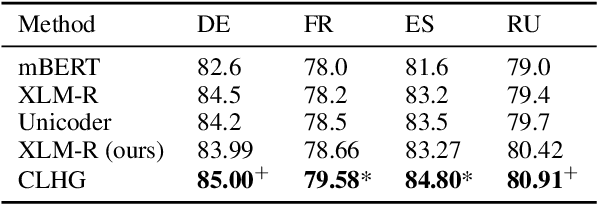

Cross-lingual text classification aims at training a classifier on the source language and transferring the knowledge to target languages, which is very useful for low-resource languages. Recent multilingual pretrained language models (mPLM) achieve impressive results in cross-lingual classification tasks, but rarely consider factors beyond semantic similarity, causing performance degradation between some language pairs. In this paper we propose a simple yet effective method to incorporate heterogeneous information within and across languages for cross-lingual text classification using graph convolutional networks (GCN). In particular, we construct a heterogeneous graph by treating documents and words as nodes, and linking nodes with different relations, which include part-of-speech roles, semantic similarity, and document translations. Extensive experiments show that our graph-based method significantly outperforms state-of-the-art models on all tasks, and also achieves consistent performance gain over baselines in low-resource settings where external tools like translators are unavailable.