 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpontaneous Style Text-to-Speech Synthesis with Controllable Spontaneous Behaviors Based on Language Models
Paper and Code
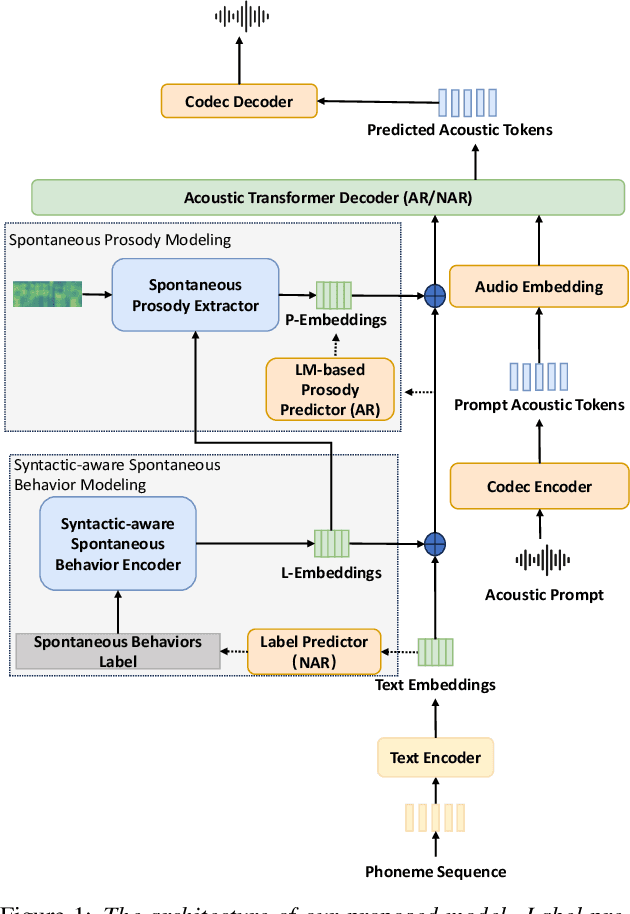
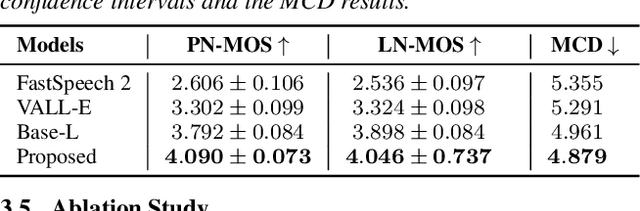
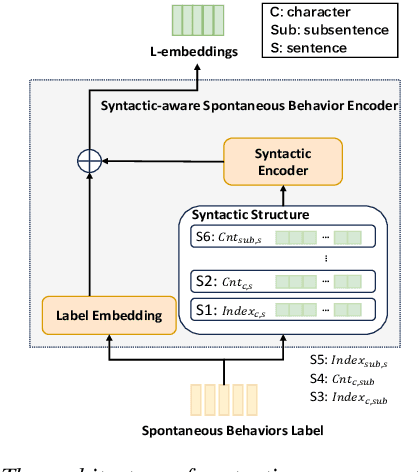
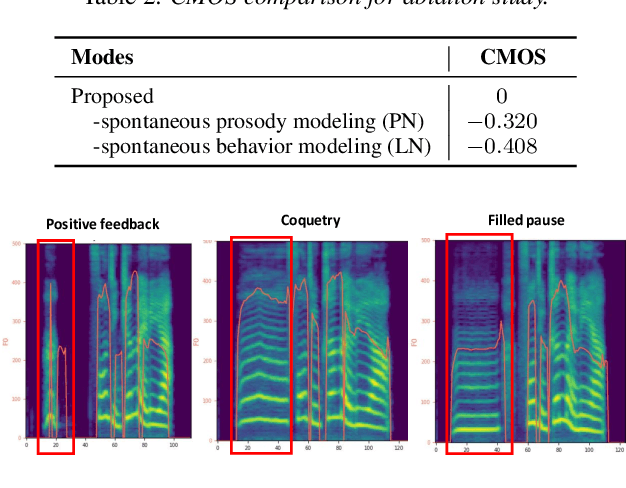
Spontaneous style speech synthesis, which aims to generate human-like speech, often encounters challenges due to the scarcity of high-quality data and limitations in model capabilities. Recent language model-based TTS systems can be trained on large, diverse, and low-quality speech datasets, resulting in highly natural synthesized speech. However, they are limited by the difficulty of simulating various spontaneous behaviors and capturing prosody variations in spontaneous speech. In this paper, we propose a novel spontaneous speech synthesis system based on language models. We systematically categorize and uniformly model diverse spontaneous behaviors. Moreover, fine-grained prosody modeling is introduced to enhance the model's ability to capture subtle prosody variations in spontaneous speech.Experimental results show that our proposed method significantly outperforms the baseline methods in terms of prosody naturalness and spontaneous behavior naturalness.