 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-Speech: Intrinsic Zero-Shot Text-to-Speech with a Learnable Speaker Encoder
May 12, 2025We introduce MiniMax-Speech, an autoregressive Transformer-based Text-to-Speech (TTS) model that generates high-quality speech. A key innovation is our learnable speaker encoder, which extracts timbre features from a reference audio without requiring its transcription. This enables MiniMax-Speech to produce highly expressive speech with timbre consistent with the reference in a zero-shot manner, while also supporting one-shot voice cloning with exceptionally high similarity to the reference voice. In addition, the overall quality of the synthesized audio is enhanced through the proposed Flow-VAE. Our model supports 32 languages and demonstrates excellent performance across multiple objective and subjective evaluations metrics. Notably, it achieves state-of-the-art (SOTA) results on objective voice cloning metrics (Word Error Rate and Speaker Similarity) and has secured the top position on the public TTS Arena leaderboard. Another key strength of MiniMax-Speech, granted by the robust and disentangled representations from the speaker encoder, is its extensibility without modifying the base model, enabling various applications such as: arbitrary voice emotion control via LoRA; text to voice (T2V) by synthesizing timbre features directly from text description; and professional voice cloning (PVC) by fine-tuning timbre features with additional data. We encourage readers to visit https://minimax-ai.github.io/tts_tech_report for more examples.
Text-aware and Context-aware Expressive Audiobook Speech Synthesis
Jun 12, 2024Recent advances in text-to-speech have significantly improved the expressiveness of synthetic speech. However, a major challenge remains in generating speech that captures the diverse styles exhibited by professional narrators in audiobooks without relying on manually labeled data or reference speech. To address this problem, we propose a text-aware and context-aware(TACA) style modeling approach for expressive audiobook speech synthesis. We first establish a text-aware style space to cover diverse styles via contrastive learning with the supervision of the speech style. Meanwhile, we adopt a context encoder to incorporate cross-sentence information and the style embedding obtained from text. Finally, we introduce the context encoder to two typical TTS models, VITS-based TTS and language model-based TTS. Experimental results demonstrate that our proposed approach can effectively capture diverse styles and coherent prosody, and consequently improves naturalness and expressiveness in audiobook speech synthesis.
Accent-VITS:accent transfer for end-to-end TTS
Dec 29, 2023


Accent transfer aims to transfer an accent from a source speaker to synthetic speech in the target speaker's voice. The main challenge is how to effectively disentangle speaker timbre and accent which are entangled in speech. This paper presents a VITS-based end-to-end accent transfer model named Accent-VITS.Based on the main structure of VITS, Accent-VITS makes substantial improvements to enable effective and stable accent transfer.We leverage a hierarchical CVAE structure to model accent pronunciation information and acoustic features, respectively, using bottleneck features and mel spectrums as constraints.Moreover, the text-to-wave mapping in VITS is decomposed into text-to-accent and accent-to-wave mappings in Accent-VITS. In this way, the disentanglement of accent and speaker timbre becomes be more stable and effective.Experiments on multi-accent and Mandarin datasets show that Accent-VITS achieves higher speaker similarity, accent similarity and speech naturalness as compared with a strong baseline.
PromptSpeaker: Speaker Generation Based on Text Descriptions
Oct 08, 2023



Recently, text-guided content generation has received extensive attention. In this work, we explore the possibility of text description-based speaker generation, i.e., using text prompts to control the speaker generation process. Specifically, we propose PromptSpeaker, a text-guided speaker generation system. PromptSpeaker consists of a prompt encoder, a zero-shot VITS, and a Glow model, where the prompt encoder predicts a prior distribution based on the text description and samples from this distribution to obtain a semantic representation. The Glow model subsequently converts the semantic representation into a speaker representation, and the zero-shot VITS finally synthesizes the speaker's voice based on the speaker representation. We verify that PromptSpeaker can generate speakers new from the training set by objective metrics, and the synthetic speaker voice has reasonable subjective matching quality with the speaker prompt.
METTS: Multilingual Emotional Text-to-Speech by Cross-speaker and Cross-lingual Emotion Transfer
Jul 29, 2023



Previous multilingual text-to-speech (TTS) approaches have considered leveraging monolingual speaker data to enable cross-lingual speech synthesis. However, such data-efficient approaches have ignored synthesizing emotional aspects of speech due to the challenges of cross-speaker cross-lingual emotion transfer - the heavy entanglement of speaker timbre, emotion, and language factors in the speech signal will make a system produce cross-lingual synthetic speech with an undesired foreign accent and weak emotion expressiveness. This paper proposes the Multilingual Emotional TTS (METTS) model to mitigate these problems, realizing both cross-speaker and cross-lingual emotion transfer. Specifically, METTS takes DelightfulTTS as the backbone model and proposes the following designs. First, to alleviate the foreign accent problem, METTS introduces multi-scale emotion modeling to disentangle speech prosody into coarse-grained and fine-grained scales, producing language-agnostic and language-specific emotion representations, respectively. Second, as a pre-processing step, formant shift-based information perturbation is applied to the reference signal for better disentanglement of speaker timbre in the speech. Third, a vector quantization-based emotion matcher is designed for reference selection, leading to decent naturalness and emotion diversity in cross-lingual synthetic speech. Experiments demonstrate the good design of METTS.
The NPU-MSXF Speech-to-Speech Translation System for IWSLT 2023 Speech-to-Speech Translation Task
Jul 10, 2023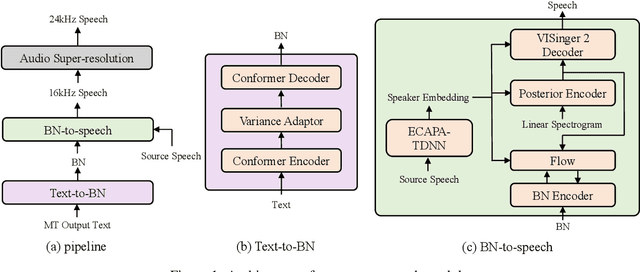


This paper describes the NPU-MSXF system for the IWSLT 2023 speech-to-speech translation (S2ST) task which aims to translate from English speech of multi-source to Chinese speech. The system is built in a cascaded manner consisting of automatic speech recognition (ASR), machine translation (MT), and text-to-speech (TTS). We make tremendous efforts to handle the challenging multi-source input. Specifically, to improve the robustness to multi-source speech input, we adopt various data augmentation strategies and a ROVER-based score fusion on multiple ASR model outputs. To better handle the noisy ASR transcripts, we introduce a three-stage fine-tuning strategy to improve translation accuracy. Finally, we build a TTS model with high naturalness and sound quality, which leverages a two-stage framework, using network bottleneck features as a robust intermediate representation for speaker timbre and linguistic content disentanglement. Based on the two-stage framework, pre-trained speaker embedding is leveraged as a condition to transfer the speaker timbre in the source English speech to the translated Chinese speech. Experimental results show that our system has high translation accuracy, speech naturalness, sound quality, and speaker similarity. Moreover, it shows good robustness to multi-source data.
PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions
Jun 01, 2023Style transfer TTS has shown impressive performance in recent years. However, style control is often restricted to systems built on expressive speech recordings with discrete style categories. In practical situations, users may be interested in transferring style by typing text descriptions of desired styles, without the reference speech in the target style. The text-guided content generation techniques have drawn wide attention recently. In this work, we explore the possibility of controllable style transfer with natural language descriptions. To this end, we propose PromptStyle, a text prompt-guided cross-speaker style transfer system. Specifically, PromptStyle consists of an improved VITS and a cross-modal style encoder. The cross-modal style encoder constructs a shared space of stylistic and semantic representation through a two-stage training process. Experiments show that PromptStyle can achieve proper style transfer with text prompts while maintaining relatively high stability and speaker similarity. Audio samples are available in our demo page.
Multi-Speaker Expressive Speech Synthesis via Multiple Factors Decoupling
Nov 19, 2022This paper aims to synthesize target speaker's speech with desired speaking style and emotion by transferring the style and emotion from reference speech recorded by other speakers. Specifically, we address this challenging problem with a two-stage framework composed of a text-to-style-and-emotion (Text2SE) module and a style-and-emotion-to-wave (SE2Wave) module, bridging by neural bottleneck (BN) features. To further solve the multi-factor (speaker timbre, speaking style and emotion) decoupling problem, we adopt the multi-label binary vector (MBV) and mutual information (MI) minimization to respectively discretize the extracted embeddings and disentangle these highly entangled factors in both Text2SE and SE2Wave modules. Moreover, we introduce a semi-supervised training strategy to leverage data from multiple speakers, including emotion-labelled data, style-labelled data, and unlabeled data. To better transfer the fine-grained expressiveness from references to the target speaker in the non-parallel transfer, we introduce a reference-candidate pool and propose an attention based reference selection approach. Extensive experiments demonstrate the good design of our model.
VISinger 2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer
Nov 05, 2022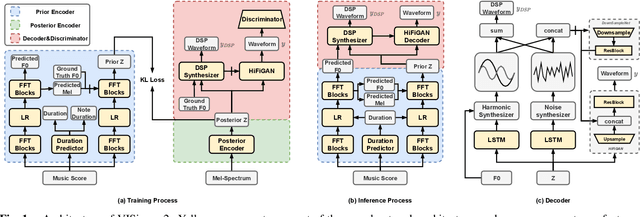
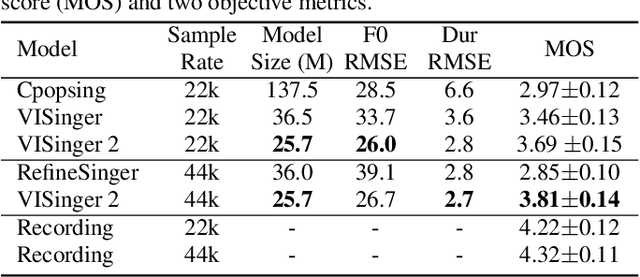
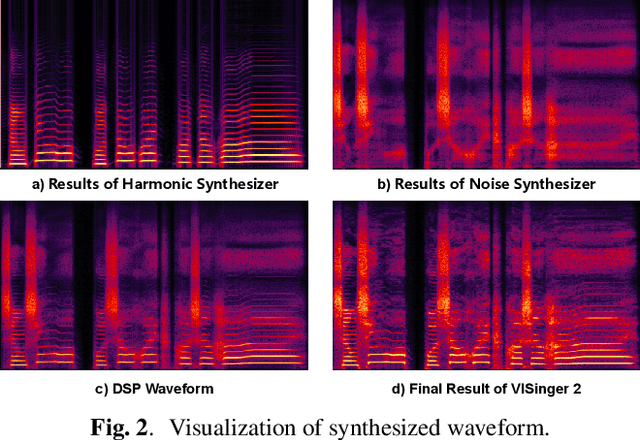
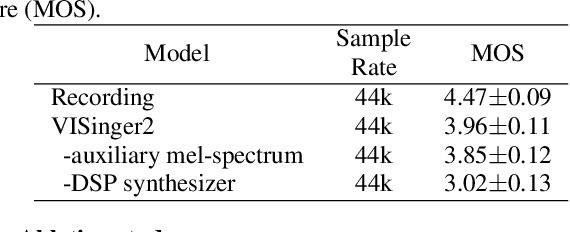
End-to-end singing voice synthesis (SVS) model VISinger can achieve better performance than the typical two-stage model with fewer parameters. However, VISinger has several problems: text-to-phase problem, the end-to-end model learns the meaningless mapping of text-to-phase; glitches problem, the harmonic components corresponding to the periodic signal of the voiced segment occurs a sudden change with audible artefacts; low sampling rate, the sampling rate of 24KHz does not meet the application needs of high-fidelity generation with the full-band rate (44.1KHz or higher). In this paper, we propose VISinger 2 to address these issues by integrating the digital signal processing (DSP) methods with VISinger. Specifically, inspired by recent advances in differentiable digital signal processing (DDSP), we incorporate a DSP synthesizer into the decoder to solve the above issues. The DSP synthesizer consists of a harmonic synthesizer and a noise synthesizer to generate periodic and aperiodic signals, respectively, from the latent representation z in VISinger. It supervises the posterior encoder to extract the latent representation without phase information and avoid the prior encoder modelling text-to-phase mapping. To avoid glitch artefacts, the HiFi-GAN is modified to accept the waveforms generated by the DSP synthesizer as a condition to produce the singing voice. Moreover, with the improved waveform decoder, VISinger 2 manages to generate 44.1kHz singing audio with richer expression and better quality. Experiments on OpenCpop corpus show that VISinger 2 outperforms VISinger, CpopSing and RefineSinger in both subjective and objective metrics.
DSPGAN: a GAN-based universal vocoder for high-fidelity TTS by time-frequency domain supervision from DSP
Nov 02, 2022



Recent development of neural vocoders based on the generative adversarial neural network (GAN) has shown their advantages of generating raw waveform conditioned on mel-spectrogram with fast inference speed and lightweight networks. Whereas, it is still challenging to train a universal neural vocoder that can synthesize high-fidelity speech from various scenarios with unseen speakers, languages, and speaking styles. In this paper, we propose DSPGAN, a GAN-based universal vocoder for high-fidelity speech synthesis by applying the time-frequency domain supervision from digital signal processing (DSP). To eliminate the mismatch problem caused by the ground-truth spectrograms in training phase and the predicted spectrograms in inference phase, we leverage the mel-spectrogram extracted from the waveform generated by a DSP module, rather than the predicted mel-spectrogram from the Text-to-Speech (TTS) acoustic model, as the time-frequency domain supervision to the GAN-based vocoder. We also utilize sine excitation as the time-domain supervision to improve the harmonic modeling and eliminate various artifacts of the GAN-based vocoder. Experimental results show that DSPGAN significantly outperforms the compared approaches and can generate high-fidelity speech based on diverse data in TTS.